

在单机系统中,大致的请求响应流程如下,1,客户端发出请求,2,服务端执行请求,3,服务端返回ack到客户端,这样客户端和服务端时保持一致的,
如果 在1阶段 发生故障,客户端会收到请求失败报错,服务端不会收到请求,此时依然保持一致,即什么都没有发生
在2阶段发生故障,客户端没有收到执行成功的ack信息,超时后认为执行失败,服务端执行失败,此时保持一致,什么都没有发生
在3阶段发生故障,客户端没有收到执行成功的ack信息,超时后认为执行失败,但是服务端执行成功,此时一致性被破坏,即服务端和客户端出现了不一致。
现实是 在任何时间都可能发生故障,如何避免这种单机不一致情况呢,可以在2阶段 将需要执行的命令 持久化,即落盘,如果3阶段出错,那么可以依据持久化的命令 回滚 执行的操作。类似mysql的redo log
可以看到 单机系统中 保持一致性还是比较简单的,当时实际的情况更加复杂,这里只是作为引子

在分布式系统中,保持一致性就变的更加复杂,因为除了故障宕机的问题外,还存在不同节点之间的通信问题,保持一致性更为困难
Paxos就是解决分布式一致性场景而诞生的算法,
Paxos算法的主要应用场景的特点如下
1,进程按照程序逻辑执行,并且返回正确结果(即非跑拜占庭问题)
ps:拜占庭问题 即使在分布式系统中,有一个或多和节点 不按照逻辑执行,其返回值是随意,混乱,错误的,简称内鬼
2,进程处理事件的速度不可控,不同进程的处理能力也不尽相同,甚至会crash
3,进程crash后,可以直接重启,并且接着之前的任务,继续处理
4,进程可以访问一个不受crash影响的持久化存储
5,进程之间互相通信速度不可控,信息可能丢失,延时,重复,但是不会损坏,即消息本身一定完整,可读
Paxos算法中定义了三种角色,Acceptor,Proposer 和 learner,其中Proposer是提议发起者,负责接受客户端的请求,并且将请求发送到Paxos集群中,通过集群来判断该请求是否可以被批准,Acceptor为提议批准者,即在Proposer发起提议后,Acceptor对提议进行表决,最终得出判断结果;learner是学习者,只能学习已经被批准的值,不能学习未被批准的值
ps:Acceptor,Proposer比较好理解,可以粗浅的理解为 议员和议会的关系,议员提出议案,议会内的所有议员对议案进行表决。那么learner是什么呢,learner相当计票员(个人理解),它负责统计表决的结果,最终促使改决议应用(apply),之后的叙述中,忽略此角色,因为不参与选举
ps: 在Paxos中还有第四种角色,即为clinet 产生议题者
在实际的分布式系统中,角色不是固定,每个线程都都可能成为某种角色
Paxos算法的核心
核心流程分为两个阶段 prepare和 accept阶段 (类比mysql的两阶段提交)
prepare阶段, Proposer 向所有的Acceptor 发起 提议申请(这个提议就是客户端发到Proposer的请求,比如修改一条数据,提议申请就是是否可以发起提议),Acceptor接受到提议申请后,自身进行决策,决定是否批准该提议申请,如果批准就回复promise消息
ps:在prepare阶段 Proposer实际上并没有真正的发送提议,可以理解为 此阶段在询问Acceptor 是否可以发起提案,如果Acceptor回复数过半,则Proposer才可以发起提案,否则不允许提案
accept阶段,Proposer 一旦获得提议申请,即可进一步的,真正的发起实际的提议了,实际的提议发送给Acceptor,同prepare阶段一样,Acceptor针对实际的提议进行判断,如果可以接受,就回复Proposer,如果过半的Acceptor都回复了,意味着该提议正式生效了。Proposer就可以返回给 client ;提议已经生效。
这样流程完成
由简单到复杂的推论
1 单Acceptor单Proposer
对于所有的client而言,所有的提议都发送到 一个Proposer上,Proposer将生成提议(不用提议申请了) 交由 唯一的 Acceptor进行批准,这时只需要一阶段提交。显然,这样面临是单点问题,如果Acceptor 宕机,则所有的提议都无法执行。
2 多Acceptor单Proposer
对于所有的client而言,所有的提议都发送到 一个Proposer上,Proposer将生成提议和提议申请 交由Acceptor集群进行判断批准,如果有超过半数的Acceptor批准了提议申请,那么提议申请通过,提议的批准流程同上。
此时如果依然采用 单Acceptor单Proposer 的一阶段提交还可以么?试想以下Proposer直接把提议发到Acceptor集群中,这时有A部分的Acceptor批准提议, B部分Acceptor拒绝了提议,然后Proposer收到了A集合Acceptor的回复,发现超过了一半,提议生效并返回client,但此时Acceptor集群内的状态发生了不一致,A集合已经提交了本地的操作日志,而B集合却没有,这时就需要Proposer再去通知B集合强行批准提议,同样的如果A集合没有超过一半,Proposer需要去通知A集合回滚操作。这增加了沟通的成本,也增加了操作(批准和回滚),这样会使得整个系统的复杂度大大提升,本来分布式系统就够复杂了,频繁的通信,回滚,批准会让本不富裕的家庭雪上加霜。
如此,Paxos 引入了二阶段提交,其步骤上文已经提到,那么二阶段提交是如何解决问题的呢。二阶段提交在一阶段提交的基础上引入了一个中间状态 prepare状态,其目的在于在提议正式被提交前让Acceptor的多数派进入 Accepted状态或Aborted状态 ,只有大部分的Acceptor同意提议,Proposer才会向Acceptor发送真正的提议,这样就避免了一阶段提交中出现的回滚,额外通信问题。
ps:问题,此时哪些没有同意提议申请的少数派Acceptor会收到 提议么 ,我猜测是需要的,但是看文章是不需要的,之后有结论再回来说

3 多Acceptor多Proposer
单Proposer也存在着风险,如果这个Proposer出现故障,那么整个系统就无法对外提供服务了,即无法接受任何提议。为了解决以上的问题可以通过以下两个方案解决
1)增加备份Proposer,一旦线上Proposer出现故障,由备份Proposer提供服务,
此方案的优势是比较简单的,hdfs集群的namenode就是如此的架构,缺点是线上提供服务的Proposer始终只有一个,这限制了性能。此外故障切换的过程中也是无法提供服务的,业务会有感知
2)多个Proposer对外提供服务
此方案的优势是集群拓展性好,Proposer性能几乎没有上限;缺点是架构比较复杂。
最终采用的方案2
在Proposer集群中,多个Proposer同时提出多个提议的场景是一定会出现的。在这种场景下可能会出现 多个Acceptor同意了多个提议,但是没有一个提议获得大多数的Acceptor的同意,即多个Proposer的提议瓜分了Acceptor的投票,这样整个系统就无法通过任何一个提案了。
那么在这种场景下,采用重试的方式可以么?即对Proposer而言,如果提议申请没有得到大多数Acceptor的认同,那么就重新提出提议申请,这种方案可以解决一部分的问题,但是实际运用时不能采用“碰运气”的方式,在流量大的场景下,新的提案源源不断,老的提案反复重试,很快整个系统就是崩溃
最终Paxos采用抢占的方式,即Proposer发现自己的提议申请没有得到大多数Acceptor,可以采用抢占的方式,去抢夺其他Acceptor的“票”,最终使自己的提议申请得到大多数Acceptor的同意。
关于抢占的理解可以参考https://www.cnblogs.com/endsock/p/3480093.html,会比较容易理解,下面依据下图介绍下抢占的流程
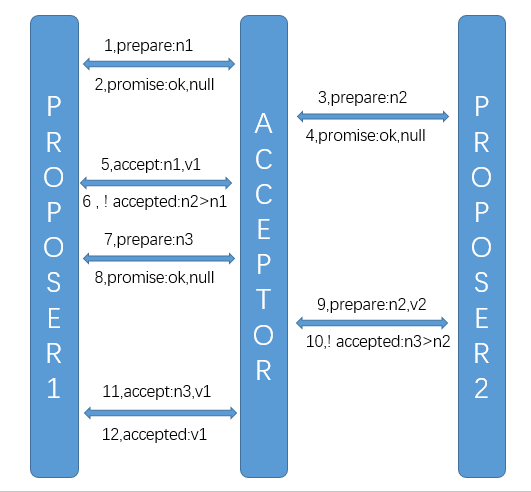
1,Proposer1向 Acceptor 提出 提议申请,提议申请中携带了提议的编号n1,注意提议申请时没有携带具体的提议值v1
2,Acceptor 接受 Proposer1的提议申请,并回复ok
3,Proposer2 向 Acceptor 提出 提议申请,提议编号为n2,
4,Acceptor 接受 Proposer2的提议申请,并回复ok
5,Proposer1 发现自己的提案已经被大部分的Acceptor接受了,从prepare阶段进入accept阶段,prepare1发送提议到Acceptor,此时的请求不但携带了提案的编号(即prepare阶段同意的提案申请编号)还携带了具体的提议值v1(因为accept阶段就要实际执行了)。
6,Acceptor接受到 accept请求,发现该请求的编号为n1,小于自己记录的最新编号n2,那么这就意味着此时的Acceptor已经把“票”投给Proposer2,即Proposer1的票被Proposer2抢占了,所以Acceptor会返回Proposer1 no。
7,Proposer1 接受提案被拒绝的信息后,就会知道自己的票已经被抢走了,所以他会再次发送更新的提议申请,提议的编号更新到更新的n3
8,Acceptor接受请求
9`11,同上
12,Acceptor接受了Proposer1的提议,循环接受
可以发现,在整个过程中是有可能出现活锁的,即Proposer1,Proposer2交替被对方抢占,导致提议无法执行
上诉的例子中只有一个Acceptor,如果有多个Acceptor时会发生什么变化么,此时关键点就在于哪一个Proposer先进入accept阶段,如果Proposer1,Proposer2都先后获得大多数Acceptor的同意,但是Proposer2是后被同意的,所以Proposer2提议n2是更新的提案;之后Proposer1进入accpet状态后,发现有些Acceptor已经“叛变”了,Proposer1就知道在它的prepare阶段之后,又有其他的提议申请获得大多数Acceptor的票了,所以Proposer1重新回到prepare阶段,尝试再次获得大多数Acceptor的票;但是这时Proposer2已经进入accept状态,并且大多数Acceptor已经接受了Proposer2的提议(会有部分Acceptor拒绝,因为被Proposer1的提议申请重新收买了),对Proposer2而言,执行提议的流程已经执行完成,大多数的Acceptor都接受了提议。对于Proposer1而言,当它会找到已经accept Proposer2提议的Acceptor时,会发现原来和我抢票的提议已经通过accept阶段了,Acceptor会返回ok,并且携带已经被接受的提议值v2,Proposer1接受Acceptor的返回值时,发现除了ok以外,居然还有提议值v2,就明白已经有提案accept了,所以会修改自己的提议值v1为v2,最终Proposer1和Proposer2的提议最终都保持了一致,那么Acceptor的状态最终保持了一致
以上看起来比较复杂,之后会结合图 一步一步的重新分析一次
多Acceptor多Proposer抢占流程分析
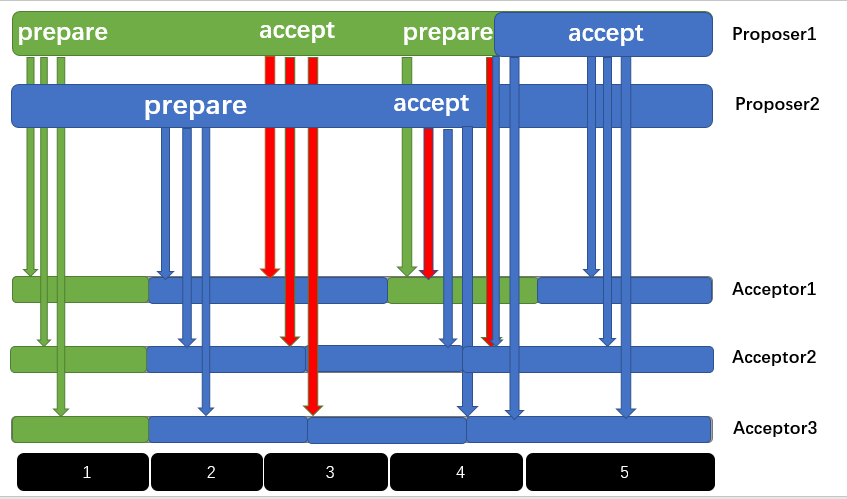
第一阶段 Proposer1发起提议n1申请,并得到三个 Acceptor的回复 回复结果为(ok,null), Proposer1 得到大多数Acceptor的认可,下一步即将进入 accept阶段
第二阶段 Proposer2发起提议n2申请,Acceptor接受到提议申请后,发现n2>n1,所以Acceptor回复(ok,null),并保证会拒绝任何<n2的提议,Proposer2进入accept阶段
第三阶段 Proposer1 进入accept阶段,发送提议到三个Acceptor,提议内容为(n1,v1),v1是提议内容。但是Acceptor发现n1<n2,所以就会拒绝Proposer1的提议,Proposer1发现提议失败,于是退回prepare阶段,重新开始发起提议申请
第四阶段 (时间顺序)
1,Proposer1 发送提议申请请求(n3)到Acceptor1,此时Acceptor1发现 n3>n2 ,决定接受Proposer1的提议申请,并返回(ok,null)
2,Proposer2 进入accept阶段,发送提议到Acceptor,提议内容是(n2,v2), Acceptor1发现 n2<n3,所以拒绝了请求,但是此时Acceptor2,和Acceptor3还没有接受到Proposer1的提议申请,于是同意了Proposer2的请求,并记录提议值v2,此时对于Proposer2而言,实现大多数Acceptor同意提议的条件,于是事件完成,可以回复client了。
3,可怜的Proposer1还在发送提议申请到Acceptor2和Acceptor3,但是此时的Acceptor2已经完成了accept阶段了,即使此时n3>n2。所以Acceptor2返回值附带上了 已经被accept的提议值,即返回(ok,v2),Acceptor3同样。
4,Proposer1接受到(ok,v2)的返回值,发现返回值中不含有null,马上就知道发生了什么,于是将自己的提议值也修改成了v2,此时Proposer1称之为learner。对于Proposer1 prepare阶段也获得了大多数Acceptor的同意,虽然这种同意是有附加值的。
第五阶段 Proposer1进入accept阶段,向所有Acceptor发送提议(n3,v2),虽然n3>n2,但是由于提议值是一样的,即v2,Acceptor也会同意提议的执行。
最终一致性得到了保证
写在最后
从以上的内容中,我们可以看出一些特点:
1,Acceptor 会观察提议的序号,在prepare阶段,序号大的提议申请覆盖序号小的,并且会拒绝序号小的提议申请,这需要Acceptor记录
1)minProposal,自己目前持有的最小提议编号,
2,Acceptor会记录已经被接受的提议编号和提议内容,即使有序号更大的提议申请,也不会影响已经被接受的提议,并且还会返回已经被接受提议的提议值,即Acceptor会记录2)acceptedProposal,已经接受的提案编号,3)acceptedValue,已经接受的提案内容
3,Proposer在prepare阶段会观察Acceptor的返回值,如果返回值形式为(ok,null),会正常进入accept阶段,如果有回复的null是其他值(即其他提议的提议值),则会根据返回的提议值修改自己的提议值(马上叛变革命),而且继续进入accept阶段
4,已数据库修改数据为例,我认为以上的抢占应该出现在涉及同一行数据的修改时才会出现,如果时对不同行的数据修改,是没有抢占的必要的,其次如果是在一个事务中有多个数据行修改,那么一旦其中一个数据行的修改出现失败,整个事务应该回滚,再次,在分布式系统中的binlog记录应该被严格限制为row格式,statement应该会很容易导致数据不一致(待验证)
至此对于 paxos的大致介绍到此结束。之后是更简单,应用范围更广的raft

