
Innodb的体系架构
innodb的线程
innodb是多线程模型,后台存在多个不同的后台线程,总览innodb的发展路径,会发现随着硬件技术的发展,CPU的数量越来越多,innodb不断的将主线程中的功能拆分出来,使用独立的线程处理,这是为了更好的利用多核CPU,提高效率并减轻主线程的压力。
Master Thread: 主线程,也是核心的线程。主要负责通过AIO刷新脏页数据,合并插入缓存,undo页回收,内部主要有1s和10s两个循环
IO Thread:io线程用于处理io请求的回调,innodb1.0之前的版本共有4个io线程,分别是 write,read,insert buffer 和log io thread,之后,write和read thread增加到各4个,即共有10个io线程。
Purge thread:purge线程用于回收已使用的undo 页,innodb 1.1之后,purge从主线程中独立出来,1.2版本后,支持多个purge 线程,在undo篇说的purge操作就是由此线程完成,见MySQL笔记三-事务-undolog
Page Cleaner Thread:负责脏页的刷新工作,在1.2版本从主线程拆分。
内存
innodb参数中如果要说个最重要的参数,我会选择innodb_buffer_pool_size(原因是我在做调度时,这个参数很重要,决定了占用多少资源),这个参数是指innodb引擎的缓冲池大小,这个参数越大,意味着越多的数据可以被缓冲到内存,内存操作显然是极快的。如果可以把所有数据都缓存起来,那就相当于缓存型数据库了,还是多线程的。但实际显然不可能,我们线上MySQL的数据多半在500G,2T数据的也有,不可能全部缓存。这意味着,只有一部分数据能够被放入内存中。如果我们可以更多的利用内存里的这部分数据,就可以使MySQL的整体效率会得到很大提升。
内存里有什么?如下图所示

占用的大部分内存都在缓冲池里,所以一个MySQL的实例所使用的内存大致会比 innod_buffer_pool_size高一些,额外的内存使用除了图中的重做日志缓存和额外缓冲池,其实还有连接所暂用的内存,一般一个连接占用的很小(一般几M),但是线上也遇到常态保持2000~3000连接的实例,这种情况下,连接占用的内存就比较多了。
从innodb 1.0以后,就可以设置多个缓冲池了,每个数据页根据哈希平均的分配到不同的缓冲池内,增加了并发,减少了冲突。我们线上默认是10个缓冲池
如何管理缓冲池?innodb使用LRU(last recent used)list进行管理,顾名思义,就是将“热”的页放到list前端,“温”页放到list后端,“冷”的页哪凉快呆着去。list已5/8为界,前5/8为new list,后3/8为old list。假设有个页刚刚被更新,那么会被放在midpoint位置,即5/8处。为什么不知道放到list的前端呢,这是为了防止有些大sql一次性读取了很多页,如果都放前端会把那些“热”页都刷回去,但是这个sql可能就执行一次。
有数据的页在LRU list中,那目前还没有数据的页呢,这些页放在free list里,这里保存那些可以使用的页。
如果页中的数据被修改,此页称之为脏页,因为此时内存和磁盘中的数据不同了,innodb会通过check point机制将脏页刷新回磁盘。这些脏页存在在flush list中,需要注意的是,脏页既存在于flush page 也存在于 LRU list中。
重做日志缓冲和额外缓冲池 重做日志缓冲就是存放redo log的地方,此内存不用分配太多,每s都会自动刷新,具体的刷新规则可见redo篇。额外缓冲池里存放的是缓冲池本身的控制对象,LRU等信息。
checkpoint
checkpoint机制的作用是将脏页flush进磁盘,可以理解为 在某种触发条件下,会将一定量的脏页flush进磁盘的机制。
checkpoint分为 sharp checkpoint和fuzzy checkpoint。其中sharp checkpoint在数据库关闭时执行,将所有脏页flush进磁盘。所以重点在fuzzy checkpoint,即是在数据库运行时,flush部分脏页到磁盘的机制。 fuzzy checkpoint大致有一下四种
mater thread checkpoint:即主线程定时执行的checkpoint,有每一秒和每十秒两种循环,每此会checkpoint一定数量的页
FLUSH_LRU_LIST checkpoint:在专用的page cleaner线程中执行,由于需要保障LRU list有足够的空闲也可用,会将list尾的page移除,如果是脏页,则触发checkpoint
async/sync flush checkpoint:此种checkpoint是专门用于redolog flush的,也放在page cleaner线程中。将已经落盘的redo log的LSN记作 checkpoint_LSN,将已经写入redo log 的LSN记作 redo_LSN,那么 定义checkpoint_age=redo_LSN - checkpoint_LSN。可以理解为还在redo log buffer中的数据量,前面说过redo log buffer不大,如果redo log buffer不够用,就需要触发checkpoint将redo log落盘。具体规则如下
-
checkpoint_age < async_water_mark 不需要checkpoint
-
async_water_mark < checkpoint_age < sync_water_mark 触发async flush,异步刷新
-
checkpoint > sync_water_mark 触发 sync flush,同步刷新
默认 async_water_mark 为 75% ,sync_water_mark 为90%
dirty page too much checkpoint:当缓冲池中的脏页超过一定数量后,触发checkpoint,默认是超过75%。
Master thread
主线程有多个循环,包括 主循环(loop),后台循环(background loop),刷新循环(flush),暂停循环(suspend loop)。主线程会在这几个状态中切换,
其中主循环中包含了大部分的引擎操作,正常对外提供服务时,大部分时间都处于loop中,如果当前没有用户活动了,主线程进入background,在background loop中执行一些purge,merge操作,此时如果有用户活动,就会跳转回loop,否则进入flush loop。在此循环innodb会不断flush 100个脏页,知道无脏页可刷,最后进入suspend loop,在这个循环里,innodb什么也不做,知道被再次唤醒。![]()
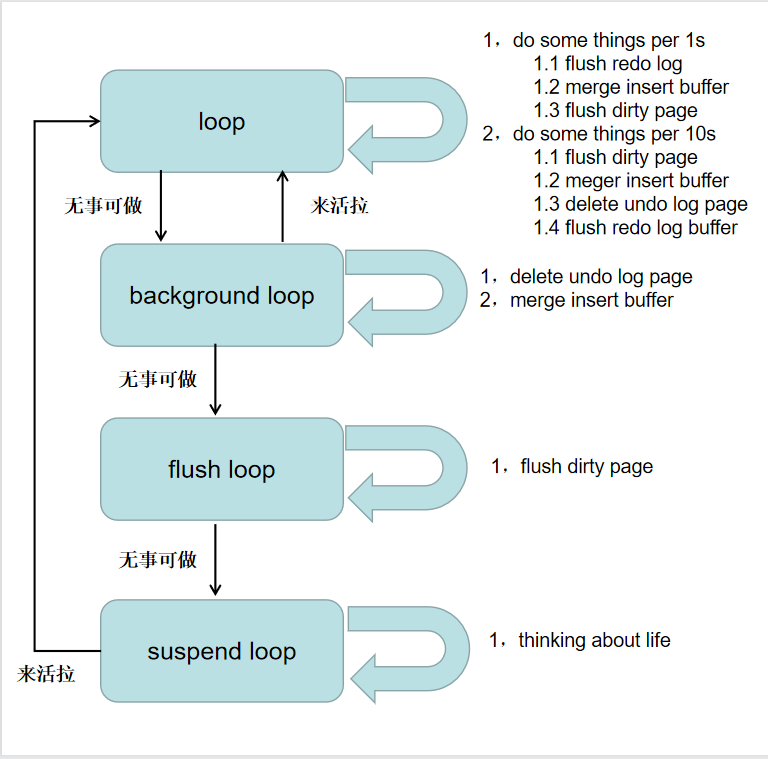
具体的状态变化和每个状态做什么,简易的用上图表示。
此图画的是innodb早期巡检,在1.2版本里,循环得到了很大的优化,比如flush dirty page 的操作就被单独放到purge clean thread里了,这里的图主要以帮助理解为主要目的
为什么1s loop 和 10s loop中有很多重复的操作呢?1s loop 中除了flush redo log是总是做的,其他工作是在有空闲或达到某个条件才做的。而10s loop中除了flush dirty page 是选做外,其他都是必做的。因为不想把图画的很复杂就省略了。
flush redo log buffer为何是必做的? 因为它真的很重要,别忘了group commit,之所以我们commit一个大事务速度快,原因就是loop实时在flush redo log,即使事务未提交,这也是保证crash recover的需求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号