

最近发现运行时特效的drawcall有点高,测试了一下发现有些情况下不会自动合批。
最后的结论如下:
1. 如果特效在同一位置,(猜测应该是PRS都相同,不过没具体测试,当时只是复制粘贴出来几个)一定会自动合批。
2. 特效中相同材质的,应该是可以被自动合批的,但是如果是半透的情况下,如果渲染队列不同,会合批失败,需要手动的将渲染队列变更为3000+1,+2..以此类推,只要不同即可。猜测原因可能是,当渲染队列相同是,半透物体的前后无法确认,底层需要对其排序(可能要渲染预处理之类的?),导致合批失败;当渲染队列不同的时候,底层可能无脑使用了渲染队列来作为渲染顺序,所以就不用自己排序了,所以相同材质的就可以被合批了。
当然,这个只是猜测。另外,ParticleSystem的order in layer也能手动划分渲染次序使得合批成功,但是根据我自己的测试情况来看,这个时候drawcall数目比修改渲染队列来的多(也能合批,但是感觉有一些还是合批失败了),目前不知道原因,可能也跟特效有关系?
另外,经过自己研究,ParticleSystem的order in layer排序优先级比渲染队列高,并且当两个都相同时,会随机决定渲染顺序(测试下来好像是先创建的先被渲染,不怎么清楚)。
使用这个优化后的效果图:
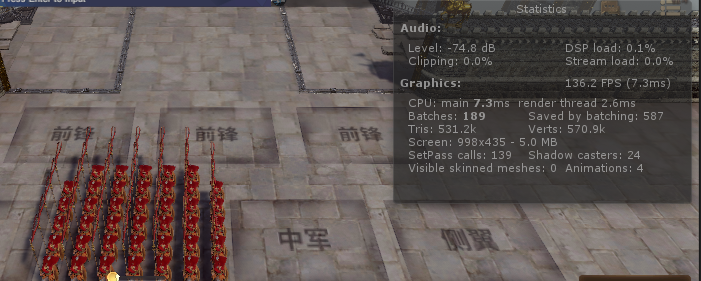
这是最初的,189dc。
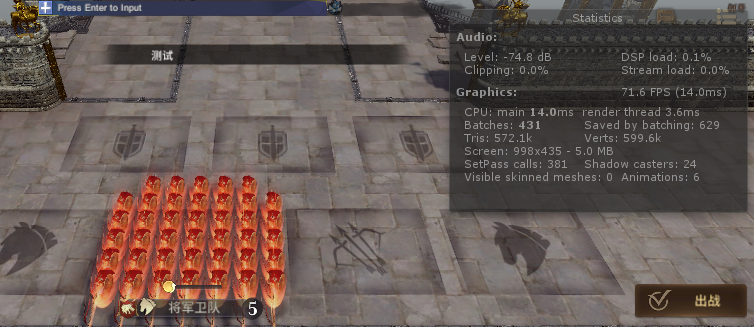
80个特效时的dc,431dc,大概特效240个dc,一个fx3个dc。
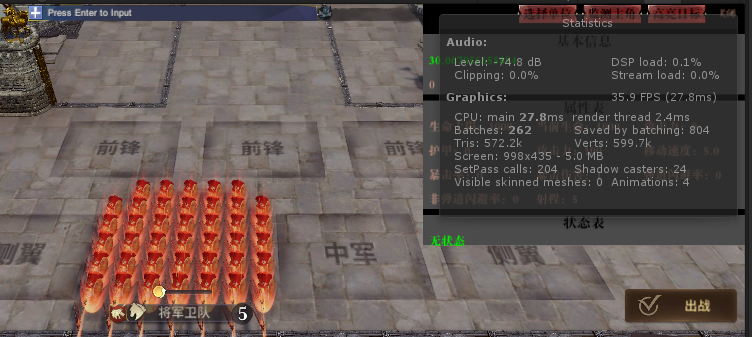
优化后的,特效大概70个dc,而且这里不小心开了右边的debug UI,多了一些dc,反正差不多优化后一个特效不到一个dc吧。效果还是不错的~
最后,提供两篇参考资料:
