MySQL优化技巧
本文的内容是总结一些MySQL的常见使用技巧,以供没有DBA的团队参考。以下内容以MySQL5.5为准,如无特殊说明,存储引擎以InnoDB为准。
MySQL的特点
了解MySQL的特点有助于更好的使用MySQL,MySQL和其它常见数据库最大的不同在于存在存储引擎这个概念,存储引擎负责存储和读取数据。不同的存储引擎具有不同的特点,用户可以根据业务的特点选择适合的存储引擎,甚至是开发一个新的引擎。MySQL的逻辑架构大致如下:
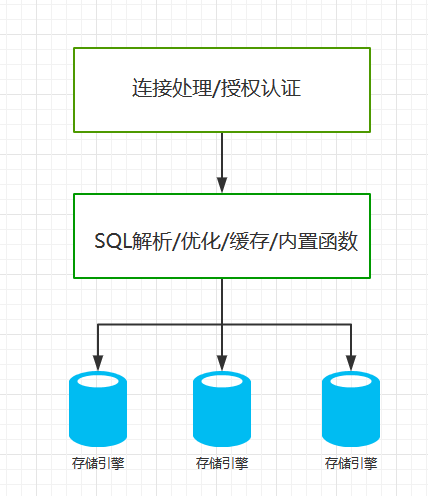
MySQL默认的存储引擎是InnoDB,该存储引擎的主要特点是:
- 支持事务处理
- 支持行级锁
- 数据存储在表空间中,表空间由一些列数据文件组成
- 采用MVVC(多版本并发控制)机制实现高并发
- 表基于主键的聚簇索引建立
- 支持热备份
其它常见存储引擎特点概述:
- MyISAM:老版本MySQL的默认引擎,不支持事务和行级锁,开发者可以手动控制表锁;支持全文索引;崩溃后无法安全恢复;支持压缩表,压缩表数据不可修改,但占用空间较少,可以提高查询性能
- Archive:只支持Insert和Select,批量插入很快,通过全表扫描查询数据
- SCV:把一个SCV文件当做一个表处理
- Memory:数据存储在内存中
还有很多,不再一一列举。
数据类型优化
选择数据类型的原则:
- 选择占用空间小的数据类型
- 选择简单的类型
- 避免不必要的可空列
占用空间小的类型更节省硬件资源,如磁盘、内存和CPU。尽量使用简单的类型,如能用int就不用char,因为后者的排序涉及到字符集的选择,比使用int复杂。可空列使用更多的存储空间,如果在可空列上创建索引,MySQL需要额外的字节做记录。创建表时,默认都是可空,容易被开发者忽视,最好是手动改为不可空,如果要存储的数据确实不会有空值的话。
整型类型
整型类型包括:
- tinyint
- smallint
- mediumint
- int
- bigint
它们分别使用8、16、24、32和64位存储数字,它们可以表示\(-2^{n-1}\)到\(2^{n-1}-1\)范围的数字,前面可以加unsigned修饰,这样可以让正数的可表示范围提高1倍,但是无法表示负数。另外,为整型指定长度没什么卵用,数据类型定下来,长度也就相应定下来了。
小数类型
- float
- double
- decimal
float和double就是通常意义上的float和double,前者使用32位存储数据,后者使用64位存储数据,和整型一样,为它们指定长度没什么卵用。
decimal类型比较复杂,支持精确计算,占用的空间也大,decimal使用每4个字节表示9个数字,如decimal(18,9)表示数字长度是18,其中小数位9个数字,整数部分9个数字,加上小数点本身,共占用9个字节。考虑到decimal占用空间较多,以及精度计算很复杂,数据量大的时候可以考虑用bigint代替之,可以在持久化和读取前对真实数据进行一些缩放操作。
字符串类型
- varchar
- char
- varbinary
- binary
- blob
- text
- 枚举
varchar类型数据实际占用空间等于字符串的长度加上1个或2个用来记录字符串长度的字节(当row-format没有被设置为fixed时),varchar很节省空间。当表中某列字符串类型的数据长度差别较大时适合使用varchar。
char的实际占用空间是固定的,当表中字符串数据的长度相差无几或很短时适合使用chart类型。
与varchar和char对应的有varbinary和binary,后者存储的是二进制字符串,和前者相比,后者大小写敏感,不用考虑编码方式,执行比较操作时更快。
需要注意的是:虽然varchar(5)和varchar(200)在存储“hello”这个字符串时使用相同的存储空间,但并不意味着将varchar的长度设置太大不会影响性能,实际上,MySQL的某些内部计算,比如创建内存临时表时(某些查询会导致MySQL自动创建临时表),会分配固定大小的空间存放数据。
blob使用二进制字符串保存大文本,text使用字符保存大文本,InnoDB会使用专门的外部存储区来存放此类数据,数据行内仅存放指向他们的指针,此类数据不宜创建索引(要创建也只能正对字符串前缀创建),不过也不会有人这么干。
如果某列字符串大量重复且内容有限,可使用枚举代替,MySQL处理枚举时维护了一个“数字-字符串”表,使用枚举可以减少很多存储空间。
时间类型
- year
- date
- time
- datetime
- timestamp
datetime存储范围是1001到9999,精确到秒。timestamp存储1970年1月1日午夜以来的秒数,可以表示到2038年。占用4个字节,是datetime占用空间的一半。timestamp表示的时间和时区有关,另外timestamp列还有个特性,执行insert或update语句时,MySQL会自动更新第一个类型为timestamp的列的数据为当前时间。很多表中都有设计有一列叫做UpdateTime,这个列使用timestamp倒是挺合适的,会自动更新,前提是系统不会使用到2038年。
主键类型的选择
尽可能使用整型,整型占用空间少,还可以设置为自动增长。尤其别使用GUID,MD5等哈希值字符串作为主键,这类字符串随机性很大,由于InnoDB主键默认是聚簇索引列,所以导致数据存储太分散。另外,InnoDB的二级索引列中默认包含主键列,如果主键太长,也会使得二级索引很占空间。
特殊类型的数据
存储IP最好使用32位无符号整型,MySQL提供了函数inet_aton()和inet_ntoa()进行IP地址的数字表示和字符串表示之间的转换。
索引优化
InnoDB使用B+树实现索引,举个例子,假设有个People,建表语句如下
CREATE TABLE `people` (
`Id` int(11) NOT NULL AUTO_INCREMENT,
`Name` varchar(5) NOT NULL,
`Age` tinyint(4) NOT NULL,
`Number` char(5) NOT NULL COMMENT '编号',
`Address` varchar(50) NOT NULL,
PRIMARY KEY (`Id`),
KEY `i_name_age_number` (`Name`,`Age`,`Number`)
) ENGINE=InnoDB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8;
插入数据:
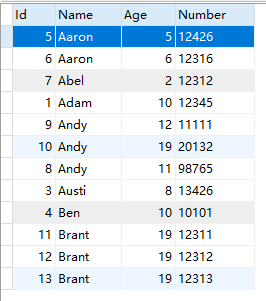
它的索引结构大致是这样的:
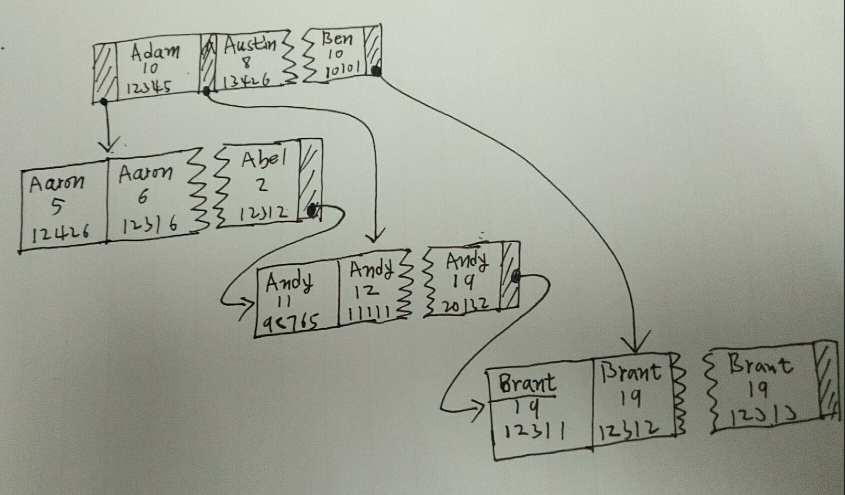
也就是说,索引列的顺序很重要,如果两行数据的Name列相同,则用Age列比较大小,如果Age列相同,则用Number列比较大小。先用第一列排序,然后是第二列,最后是第三列。
查询的使用应该尽量从左往右匹配,另外,如果左边列范围查找,右边列无法使用索引;还有就是不能隔列查询,否则后面的索引也无法使用到。如以下几个SQL是正面范例:
- SELECT * from people where
Name='Abel' and Age = 2 AND Number = 12312 - SELECT * from people where
Name='Abel' - SELECT * from people where
Namelike 'Abel%' - SELECT * from people where
Name= 'Andy' and Age BETWEEN 11 and 20 - SELECT * from people ORDER BY NAME
- SELECT * from people ORDER BY NAME, Age
- SELECT * from people GROUP BY
Name
以下几个SQL是反面范例:
- SELECT * from people where Age = 2
- SELECT * from people where NAME like '%B'
- SELECT * from people where age = 2
- SELECT * from people where NAME = 'ABC' AND number = 3
- SELECT * from people where NAME like 'B%' and age = 22
一个使用Hash值创建索引的技巧
如果表中有一列存储较长字符串,假设名字为URL,在此列上创建的索引比较大,有个办法可以缓解:创建URL字符串的数字哈希值的索引。再新建一个字段,比如叫做URL_CRC,专门放置URL的哈希值,然后给这个字段创建索引,查询时这样写:
select * from t where URL_CRC = 387695885 and URL = 'www.baidu.com'
如果数据量比较多,为防止哈希冲突,可自定义哈希函数,或用MD5函数返回值的一部分作为哈希值:
SELECT CONV(RIGHT(MD5('www.baidu.com'),16), 16, 10)
前缀索引
如果字符串列存储的数据较长,创建的索引也很大,这时可以使用前缀索引,即:只针对字符串前几个字符做索引,这样可以缩短索引的大小,不过,显然,此类索引在执行order by和group by时不起作用。
创建前缀索引时选择前缀长度很重要,在不破坏原来数据分布的情况下尽可能选择较短的前缀。举个例子,如果如果大部分字符串是以"abc"开头,那么如果限定前缀索引长度为4,索引值会包含太多的重复的"abcX"。
多列索引
上面提到的“People”上创建的索引即为多列索引,多列索引往往比多个单列索引更好。
- 对多个索引进行and查询时,应该创建多列索引,而不是多个单列索引
- 可以试试这样写的效果:
select * from t where f1 = 'v1' and f2 <> 'v2' union all select * from t where f2 = 'v2' and f1 <> 'v1'
多列索引的顺序很重要,通常,不考虑排序和分组查询时,应该把选择性(选择性是指某表索引列不同数据的个数/总行数。选择性高意味着重复数据少)大的列放到前面。但也有例外,如果能确认某些查询是频繁执行的,则应该优先照顾这些查询的选择性,比如,如果上面的People表中Name的选择性大于Age,查询语句应该这样写:
select * from people where name = 'xxx' and age = xx
Name列放了索引中的左侧比较合适,但是如果某个SQL执行的评率最高,比如
select * from people where name = 'xxx' and age = 20,
当age=20的记录在数据库中非常少时,反而把age放到索引列的左端效率更高。把age放了索引左端可能对其它age不等于20的查询来说不公平,如果不能确定age=20是最非常频繁的查询条件,还是要综合考虑,把name放了左侧合适。
聚簇索引
聚簇索引是一种数据存储结构,InnoDB在主键的索引的叶子节点中直接保存了数据行,而不是像二级索引那样只是保存了索引列的值和所指向行的主键值。由于这个特性,一个表只能有一个聚簇索引。如果一个表没有定义主键也没有定义具有唯一索引的列,那么InnoDB会生成一个隐藏列,并且在此列设为聚簇索引列。
覆盖索引
简单地说,某些查询只需要查询索引列,那么就不用再根据索引B树节点记录的主键ID进行二次查询了。
重复索引和冗余索引
如果重复在某列创建索引,并不会带来任何好处,只有坏处,应该尽量避免。比如给主键创建唯一索引和普通索引就是多于的,因为InnoDB的主键默认就是聚簇索引了。
冗余索引和重复索引不同,比如某个索引是(A,B),另一个索引是(A),这叫冗余索引,前者可以代替后者,后者不可以代替前者的作用。但是(A,B)和(B)以及(A,B)和(B,A)不算冗余索引,起作用谁也代替不了谁。
如果一个表中已经存在索引(A),现在又想创建索引(A,B),那么只需扩展就的索引就可以,没有必要创建新的索引。需要注意的是如果已经存在索引(A),那么也没有必要在创建索引(A,ID),其中ID指主键,因为索引A默认已经包含了主键了,也算是冗余主键。
但是,有时候,冗余索引也是可取的,假设已经存在索引(A),将其扩展为(A,B)后,因为B列是一个很长的类型,导致用A单独查询时没有以前快了,这时可以考虑新创建索引(A,B)。
不使用的索引
不使用的索引徒然增加insert、update和delete的效率,应该及时删除
索引使用总结
索引的三星原则:
- 索引将查询相关的记录按顺序放在一起则得一星
- 索引中的数据顺序和查询结果的排序一致则得一星
- 索引中包含了查询所需要的全部列则得一星
第一个条原则的意思是where条件中查询的顺序和索引是一致的,就是前面说的从左到右使用索引。
索引不是万能的,当数据量巨大时,维护索引本身也是耗费性能的,应该考虑分区分表存储。
查询优化
查询慢的原因
是否向数据库请求了多余的行
比如应用程序只需要10条数据,但是却向数据库请求了所有的数据,在显示在UI上之前抛弃了大部分数据。
是否向数据库请求了多余的列
比如应用程序只需要展现5列,但却通过select * from 把全部的列都查了出来
是否重复多次执行了相同的查询
应用程序是否可以考虑一次查询然后缓存,后面的用到时可以使用第一次查询出来的记录。
MySQL是否在扫描额外的记录
通过查看执行计划可以大概了解需要扫描的记录数,如果这个数字超出了预期,尽可能通过添加索引、优化SQL(就是本节的重点),或者改变表结构(如新增一个单独的汇总表,专门供某个语句查询用)来解决。
重构查询的方式
- 将一个复杂的查询分解成多个简单的查询
- 将大的查询切分成小的查询,每次查询功能一样,只完成一小部分
- 分解关联查询。可以将一个大的关联查询改成分别查询若干个表,然后在应用程序代码中处理
杂七杂八
优化count()
Count有两个作用,一是统计指定的列或表达式,二是统计行数。如果参数传入一列名或者是一个表达式,那么count会统计所有结果不为NULL的行数,如果参数是*,那么count会统计所有行数。这里有一个传表达式的例子:
SELECT count(name like 'B%') from people
- 可以使用近似值优化来代替count(),如执行计划中的行数。
- 索引覆盖扫描
- 增加汇总表
- 增加内存缓存系统记录数据条数
关联查询的优化
- MySQL优化器关联表查询是这样进行的,比如有两个表A和B通过c列关联,MySQL会遍历A表,然后根据遍历到的c列的值去B表中查找数据。综上所述,通常,如无只需要给B表的c列加上索引即可
- 确保order by和group by涉及到的列只属于一个表,这样才有可能发挥索引的作用
优化子查询
对于MySQL5.5及以下版本,尽量用连接代替子查询。
优化group by、distinct
如果可能,尽量对主键施加这两种操作。
优化limit
比如有SQL
SELECT * from sa_stockinfo ORDER BY StockAcc LIMIT 400, 5
MySQL优化器会查找405行所有列数据然后丢弃400。如果能利用覆盖索引查询则不必查询出这么多列,先修改为:
SELECT * FROM sa_stockinfo i JOIN (SELECT StockInfoID FROM sa_stockinfo ORDER BY StockAcc LIMIT 400,5)t ON i.StockInfoID = t.StockInfoID
StockAcc上建有索引,该查询会利用索引覆盖,较快找出符合条件的主键,然后在做联合查询,在数据量大的时候效果明显。
优化union
如无必要,一定要用关键字 union all,这样MySQL把数据放到临时表时不会再做唯一性验证
判断某条记录是否存在
通常的做法是
select count(*) from t where condition
最好这样写:
SELECT IFNULL((SELECT 1 from tableName where condition LIMIT 1),0)
参考书
-
《高性能MySQL》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号