


Redis 搭建集群
Redis 搭建集群
我在这里只记录点基本内容,不会写太深入的内容
问题
容量不够,redis 如何进行扩容?
增加 redis 服务器,通过集群解决容量不够的问题
并发写操作,redis 如何分摊?
使用集群负担写操作的压力
主从模式、薪火相传、主机宕机,都可能导致 ip 地址发生变化,应用程序中配置需要修改对应的主机地址、端口等信息?
redis 3.0 之前使用代理主机来解决,redis 3.0 中提供了解决方案,就是无中心化集群配置
代理主机方式:
客户端通过代理服务器去访问服务,比如用户、商品、订单等服务,每个服务都有从服务器,代理主机也有从服务器
无中心化集群:
每个服务都有从服务器,但是任何服务器都可以作为集群的入口,将服务直接转移给另外的服务
概念
redis 集群实现了对 redis 的水平扩容,即启动 N 个 redis 节点,将整个数据库分布存储在这 N 个节点中,每个节点存储总数据的 1/N
redis 集群通过分区(partition)来提供一定长度的可用性(availability),即使集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令请求
搭建 redis 集群
我们使用六台服务器搭建 redis 集群,当然,肯定是用一台机器的不同端口来模拟
步骤:
- 在 redis/bin 目录创建一个文件夹,例如 cluster
- 我们需要六个 redis 配置,端口号分别为:6379、6380、6381、6389、6390、6391,
6379、6380、6381是主服务器,6389、6390、6391是从服务器 - 配置基本信息,配置文件名都是 redis_端口号.conf
include cluster/redis.conf:这是基本的redis配置文件pidfile /var/run/redis_端口号.pidport 端口号dbfilename "dump_端口号.rdb"cluster-enabled yes:打开集群模式cluster-config-file nodes_端口号.conf:设定节点配置文件名cluster-node-timeout 15000:设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换
- 启动六个 redis 服务:打开三个终端,到 redis/bin 目录,启动三台 redis 服务器(你也可以给这个命令配置一个环境变量)
./redis-server cluster/redis_6379.conf./redis-server cluster/redis_6380.conf./redis-server cluster/redis_6381.conf./redis-server cluster/redis_6389.conf./redis-server cluster/redis_6390.conf./redis-server cluster/redis_6391.conf
- 将六个节点合成一个集群,组合之前,确保所有 redis 实例启动后,nodes_端口号.conf 文件都生成正常(这个 node 文件在 redis 的 data 目录下)
- 旧版本的 redis 版本中,需要 ruby 环境
- 比较新的 redis 版本中,不需要额外工具,控制台进入 redis 源码的 src 目录下,执行命令
redis-cli --cluster create --cluster-replicas 1 ip地址:端口号 ip地址:端口号 ...,--replicas 1表示采用最简单的方式配置集群,一台主服务器,一台从服务器。如果有密码,在后面加-a 密码,或者写配置文件masterauth 密码
- 连接要采用集群策略连接,命令是
./redis-cli -c -h ip地址 -p 端口号,设置数据会自动切换到相应的主服务器,连接任意一个服务器都可以 - 通过
cluster nodes命令查看集群信息
启动六个 redis 服务器

配置集群,这里显示了集群策略,显示了哪些服务器被分配到主服务器,哪些被分配到从服务器
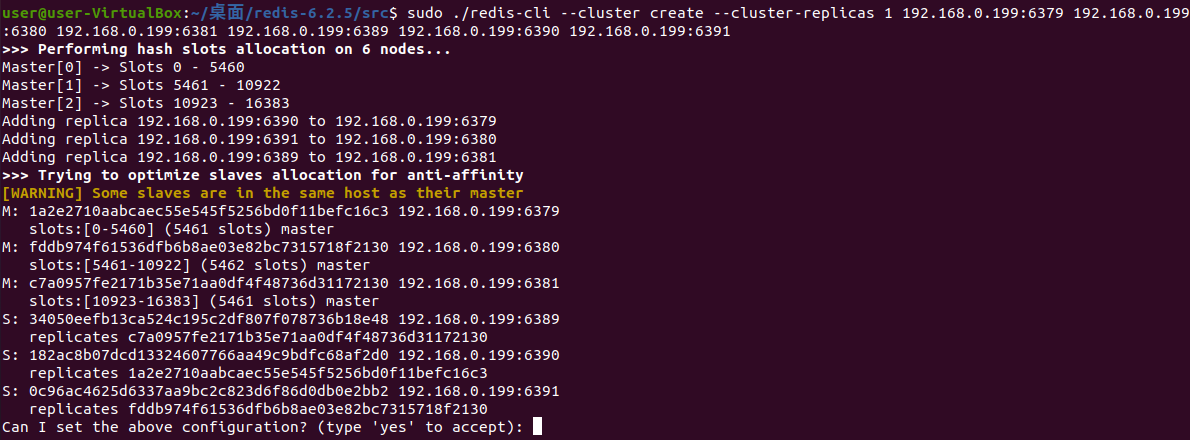
输入 yes 之后就开始创建集群了,注意,我这里分配的主从没有对齐,变成了 6379--6390、6380--6391、6381--6389,不过这都无所谓,我们继续
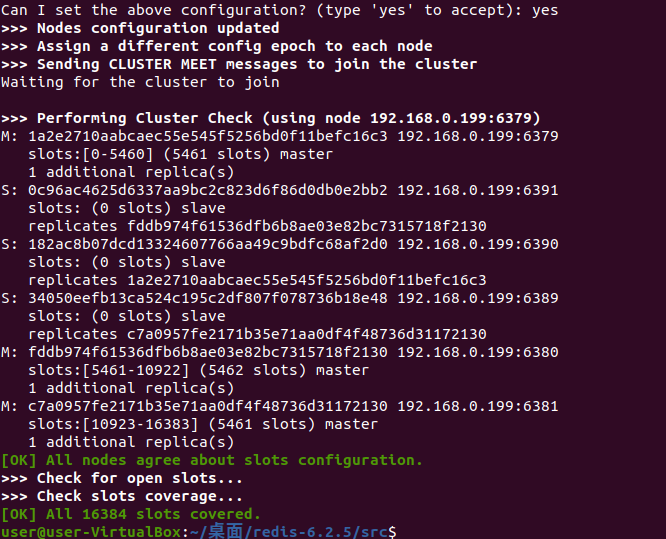
集群操作
redis cluster 如何分配这六个节点?
一个集群至少要有三个主节点
选项 --cluster-replicas 1 表示我们希望为集群中的每个主节点创建一个从节点
分配原则尽量保证每个主数据库运行在不同的ip地址,每个从数据库和主数据库不在一个ip地址上
再看一下 slots

[OK] All 16384 slots covered,什么是 slots?
一个 redis 集群包含 16384 个插槽(hash slot),数据库中的每个键都属于这 16384 个插槽的其中一个
集群使用公式 CRC16(key) % 16384 来计算键key属于哪个槽,其中 CRC16(key) 语句用于计算键key的 CRC16 校验和
集群中的每个节点负责处理一部分插槽,举个例子,如果一个集群可以有主节点,其中:
- 节点 A 负责处理 0 号至 5460 号插槽
- 节点 B 负责处理 5461 号至 10922 号插槽
- 节点 C 负责处理 10923 号至 16383 号插槽
但是集群中任意一台服务器都可以作为集群的入口,所以能互相访问到自己负责的插槽之外的数据,会直接切换到插槽对应的服务器
首先我们先用六个 redis-cli 连接对应端口的 redis 服务,一定要用集群模式连接
三个主服务器
三个从服务器
插入数据示例
set name zhangsan
插入数据会自动切换到数据插槽对应的服务器
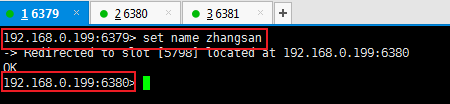
查询数据也会切换到对应的服务器
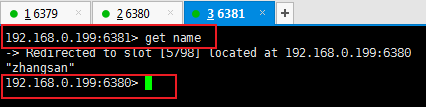
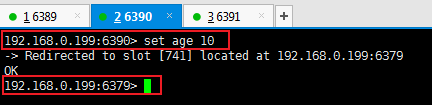
从服务器读取或写入数据也会切换过去

但是不能同时使用多条 set 命令,因为插槽算不出来,比如底下这条命令
mset name zhangsan age 20 id 0001
结果会报错

需要分组,这样就根据了组的名字去计算插槽的值
mset name{user} zhangsan age{user} 20 id{user} 0001
结果正确

查询集群中的值
cluster keyslot <key>:查询 key 对应的插槽值cluster countkeysinslot <slot>:查询 slot 的值的数量,没有就是 0 ,只能查询当前服务器负责的插槽cluster getkeysinslot <slot> <count>:返回 count 个 slot 中的 key
故障恢复
如果主节点宕机,从节点自动升为主节点
宕机的主节点重启之后,这个宕机的主节点会自动变成从节点
如果主从节点都宕机了,根据 redis.conf 的配置,cluster-require-full-coverage 为 yes ,这是默认值,那么,整个集群都宕机;而cluster-require-full-coverage 为 no ,那么该插槽的数据全部都不能使用,也无法存储
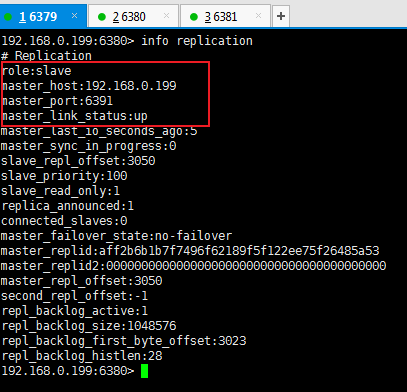
比如我们 shutdown 一个主服务器,6380 对应的从服务器是 6391
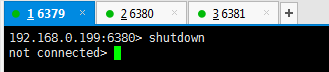
再去查看它的从服务器 6391,变成了主服务器,没有问题

再启动 6380,变成了从服务器
集群的优势
- 实现扩容
- 分摊压力
- 无中心配置相对简单
集群的缺陷
- 多键操作是不被支持的
- 多键的 redis 事务是不被支持的,lua 脚本不被支持
- 由于集群方案出现较晚,很多公司已经采用了其它的集群方案,而代理或者客户端分片的方案想要迁移至 redis cluster,需要整体迁移而不是逐步过渡,复杂度较大

