
Redis 基本数据类型以及在C#中的使用
Redis 基本数据类型以及在C#中的使用
我在这里只记录点基本内容,不会写太深入的内容
C# 使用的是 ServiceStack.Redis ,通过 NuGet 安装
操作 JSON 使用 Newtonsoft.Json
基本的代码
连接数据库就一句:using IRedisClient client = new RedisClient("192.168.0.1", 6379, "");,所有的数据库操作都是通过这个 client 对象来使用
因为 ServiceStack.Redis 没有注解,所以我会把常用的函数给标注出来
这个构造器有这么些个重载
public RedisClient();
public RedisClient(string host);
public RedisClient(RedisEndpoint config);
public RedisClient(Uri uri);
public RedisClient(string host, int port);
public RedisClient(string host, int port, string password = null, long db = 0);
host:redis 数据库所在的主机的 IP 地址port:redis 数据库使用的端口号password:redis 数据库连接密码db:redis 的序号,0 ~ 15
string
key - value
三种编码方式:
- int 编码:保存long 型的64位有符号整数
- raw 编码:保存长度大于44字节的字符串
- embstr 编码:保存长度小于等于44字节的字符串
这里的 44 字节,在 redis 3.0 版本之前是39字节
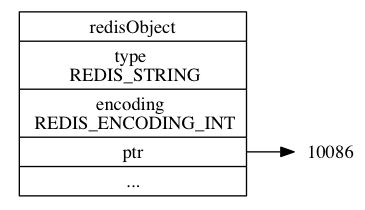
int 编码就是这样
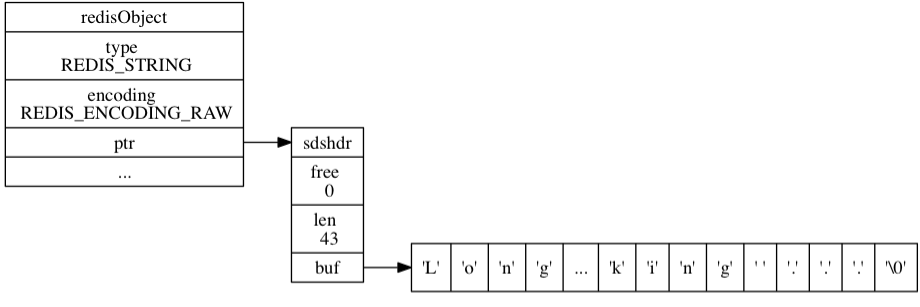
raw 编码长这样,开辟两次内存空间,一次是 sdshdr 内存空间,一次是 sdshdr 中的 buf[] 中的数据空间,释放内存也是两次,效率较低
embstr 编码,开辟一次内存空间,释放内存也是一次
embstr 编码是只读的,如果需要对其修改,Redis 内部会将其修改为 raw 编码之后再操作

struce sdshdr 结构体长这样:
int len:buf[]中已占用空间的长度int free:buf[]中剩余可用空间的长度char buf[]:数据空间
注意:
编码一旦升级(int–>embstr–>raw),即使后期再把字符串修改为符合原编码能存储的格式时,编码也不会回退
少用 string 类型,因为开辟空间的时候会帮我们预留空间,空间不够就会换到新的内存空间,预留的空间会更大,浪费存储空间
代码操作
/// <summary>
/// 新增 key 和 value
/// 如果 key 存在,则新增失败
/// </summary>
/// <typeparam name="T">一般直接使用 string</typeparam>
/// <param name="key">键</param>
/// <param name="value">值</param>
/// <returns></returns>
bool Add<T>(string key, T value);
/// <summary>
/// 新增 key 和 value,并设置过期时间
/// 如果 key 存在,则新增失败
/// </summary>
/// <typeparam name="T">一般直接使用 string</typeparam>
/// <param name="key">键</param>
/// <param name="value">值</param>
/// <param name="expiresAt">过期时间</param>
/// <returns></returns>
bool Add<T>(string key, T value, DateTime expiresAt);
/// <summary>
/// 新增 key 和 value,并设置持续时间
/// 如果 key 存在,则新增失败
/// </summary>
/// <typeparam name="T">一般直接使用 string</typeparam>
/// <param name="key">键</param>
/// <param name="value">值</param>
/// <param name="expiresIn">持续时间</param>
/// <returns></returns>
bool Add<T>(string key, T value, TimeSpan expiresIn);
/// <summary>
/// 设置 key 和 value
/// Set,直接替换值
/// </summary>
/// <typeparam name="T">一般直接使用 string</typeparam>
/// <param name="key">键</param>
/// <param name="value">值</param>
/// <returns></returns>
bool Set<T>(string key, T value);
/// <summary>
/// 设置 key 和 value,并设置过期时间
/// Set,直接替换值
/// </summary>
/// <typeparam name="T">一般直接使用 string</typeparam>
/// <param name="key">键</param>
/// <param name="value">值</param>
/// <param name="expiresAt">过期时间</param>
/// <returns></returns>
bool Set<T>(string key, T value, DateTime expiresAt);
/// <summary>
/// 设置 key 和 value,并设置持续时间
/// Set,直接替换值
/// </summary>
/// <typeparam name="T">一般直接使用 string</typeparam>
/// <param name="key">键</param>
/// <param name="value">值</param>
/// <param name="expiresIn">时间间隔,持续时间</param>
/// <returns></returns>
bool Set<T>(string key, T value, TimeSpan expiresIn);
/// <summary>
/// 通过 key 读取 value
/// 一般不建议使用这个方法,因为读取出来的字符串带双引号
/// </summary>
/// <param name="key">键</param>
/// <returns></returns>
string GetValue(string key);
/// <summary>
/// 通过 key 读取 value
/// 推荐使用,帮助我们做了反序列化,不带双引号读取
/// </summary>
/// <typeparam name="T">一般直接使用 string</typeparam>
/// <param name="key">键</param>
/// <returns></returns>
T Get<T>(string key);
/// <summary>
/// 批量新增 key 和 value
/// </summary>
/// <param name="map">Dictionary 对象</param>
void SetAll(Dictionary<string, string> map);
/// <summary>
/// 通过 key 的集合批量读取 value
/// </summary>
/// <typeparam name="T">一般直接使用 string</typeparam>
/// <param name="keys">key 的集合</param>
/// <returns></returns>
IDictionary<string, T> GetAll<T>(IEnumerable<string> keys);
/// <summary>
/// 在原有 key 的 value 值之后追加 value、
/// 可以直接追加,因为没有就是 ""
/// </summary>
/// <param name="key">键</param>
/// <param name="value">值</param>
/// <returns></returns>
long AppendToValue(string key, string value);
/// <summary>
/// 获取 key 对应的 value,然后设置新的 value
/// </summary>
/// <param name="key">键</param>
/// <param name="value">值</param>
/// <returns></returns>
string GetAndSetValue(string key, string value);
/// <summary>
/// key 对应的 value 自增,然后返回结果
/// 结果可以为负数
/// </summary>
/// <param name="key">键</param>
/// <param name="amount">自增的数量</param>
/// <returns></returns>
long Increment(string key, uint amount);
/// <summary>
/// key 对应的 value 自增,然后返回结果
/// 结果可以为负数
/// </summary>
/// <param name="key">键</param>
/// <param name="count">自增的数量</param>
/// <returns></returns>
long IncrementValueBy(string key, int count);
/// <summary>
/// key 对应的 value 自减,然后返回结果
/// 结果可以为负数
/// </summary>
/// <param name="key">键</param>
/// <param name="amount">自减的数量</param>
/// <returns></returns>
long Decrement(string key, uint amount);
/// <summary>
/// key 对应的 value 自减,然后返回结果
/// 结果可以为负数
/// </summary>
/// <param name="key">键</param>
/// <param name="count">自减的数量</param>
/// <returns></returns>
long DecrementValueBy(string key, int count);
关于 Add 和 Set 的区别:
- Add:新增的时候,先判断,如果 key 存在,则新增失败;如果不存在,则新增成功
- Set:直接替换值
Get 和 GetValue 的区别:
- Get:帮助我们做了反序列化,不带双引号读取
- GetValue:读取出来的字符串带双引号,
JsonConvert.DeserializeObject<string>(client.GetValue("key"))也可以和 Get 有相同的效果
hash
hashId - key - value
两种数据结构
- ZipList:
- 组成:
- zlbytes:ZipList 的长度
- zltail:头
- 数据内容
- zlend:尾
- 与链表类似,需要找到上一个才能找到下一个,修改值也是这样,所以长度过长会影响性能,需要使用 HashTable
- 如果 key 超过512个,增删改查较慢,使用 HashTable,512这个数值可以修改
- 如果任意一个 key 的键或值超过64字节,使用 HashTable,因为内存的问题,只要有一个数据超过64字节,其它数据也会超过64字节,64这个数值可以修改
- 组成:
- HashTable:
- 与编程语言的 HashTable 相似
代码操作
/// <summary>
/// 通过 hashId 和 value 设置一个值
/// </summary>
/// <param name="hashId"></param>
/// <param name="key"></param>
/// <param name="value"></param>
/// <returns></returns>
bool SetEntryInHash(string hashId, string key, string value);
/// <summary>
/// 通过 hashId 和 key 获取一个值
/// </summary>
/// <param name="hashId"></param>
/// <param name="key"></param>
/// <returns></returns>
string GetValueFromHash(string hashId, string key);
/// <summary>
/// 通过 hashId 批量设置 key-value
/// </summary>
/// <param name="hashId"></param>
/// <param name="keyValuePairs">key-value 键值对</param>
void SetRangeInHash(string hashId, IEnumerable<KeyValuePair<string, string>> keyValuePairs);
/// <summary>
/// 通过 hashId 批量读取 key-value 数据
/// </summary>
/// <param name="hashId"></param>
/// <returns></returns>
Dictionary<string, string> GetAllEntriesFromHash(string hashId);
/// <summary>
/// 如果我们的 hash 集合中已经存在了相同 key,则新增失败,返回 false
/// 否则可以新增成功,并返回 true
/// </summary>
/// <param name="hashId"></param>
/// <param name="key"></param>
/// <param name="value"></param>
/// <returns></returns>
bool SetEntryInHashIfNotExists(string hashId, string key, string value);
/// <summary>
/// 写入一个对象
/// </summary>
/// <typeparam name="T">引用类型</typeparam>
/// <param name="entity">引用类型的实体对象</param>
void StoreAsHash<T>(T entity);
/// <summary>
/// 通过 hashId 读取一个对象
/// </summary>
/// <typeparam name="T">引用类型</typeparam>
/// <param name="id">hashId</param>
/// <returns></returns>
T GetFromHash<T>(object id);
/// <summary>
/// 通过 hashId 读取 hash 中的 key 总数
/// </summary>
/// <param name="hashId"></param>
/// <returns></returns>
long GetHashCount(string hashId);
/// <summary>
/// 通过 hashId 读取 hash 中的所有 key
/// </summary>
/// <param name="hashId"></param>
/// <returns></returns>
List<string> GetHashKeys(string hashId);
/// <summary>
/// 通过 hashId 读取 hash 中的所有 value
/// </summary>
/// <param name="hashId"></param>
/// <returns></returns>
List<string> GetHashValues(string hashId);
/// <summary>
/// 通过 hashId 删除 hash 中指定的 key 及其 value
/// </summary>
/// <param name="hashId"></param>
/// <param name="key"></param>
/// <returns></returns>
bool RemoveEntryFromHash(string hashId, string key);
/// <summary>
/// 通过 hashId 判断 hash 是否存在 key 的数据
/// </summary>
/// <param name="hashId"></param>
/// <param name="key"></param>
/// <returns></returns>
bool HashContainsEntry(string hashId, string key);
/// <summary>
/// 通过 hashId 使 hash 的 key 对应的 value 自增
/// </summary>
/// <param name="hashId"></param>
/// <param name="key"></param>
/// <param name="incrementBy"></param>
/// <returns></returns>
long IncrementValueInHash(string hashId, string key, int incrementBy);
list
list 是一个可以重复的集合
listId - value
数据结构:
- 双向链表
代码操作
/// <summary>
/// 添加 list
/// </summary>
/// <param name="listId"></param>
/// <param name="value"></param>
void AddItemToList(string listId, string value);
/// <summary>
/// 通过 listId 从左侧向 list 添加,就是追加
/// </summary>
/// <param name="listId"></param>
/// <param name="value"></param>
void PushItemToList(string listId, string value);
/// <summary>
/// 通过 listId 从右侧向 list 添加,插队(最前边)
/// </summary>
/// <param name="listId"></param>
/// <param name="value"></param>
void PrependItemToList(string listId, string value);
/// <summary>
/// 通过 listId 获取 list 数据的个数
/// </summary>
/// <param name="listId"></param>
/// <returns></returns>
long GetListCount(string listId);
/// <summary>
/// 通过 listId 批量添加 value 数据
/// </summary>
/// <param name="listId"></param>
/// <param name="values"></param>
void AddRangeToList(string listId, List<string> values);
/// <summary>
/// 根据索引查询 listId 集合中的数据
/// 获取 listId 中索引为 startingFrom 到 endingAt 的值集合
/// </summary>
/// <param name="listId"></param>
/// <param name="startingFrom"></param>
/// <param name="endingAt"></param>
/// <returns></returns>
List<string> GetRangeFromList(string listId, int startingFrom, int endingAt);
/// <summary>
/// 通过 listId 设置 listIndex 索引处的数据
/// </summary>
/// <param name="listId"></param>
/// <param name="listIndex"></param>
/// <param name="value"></param>
void SetItemInList(string listId, int listIndex, string value);
/// <summary>
/// 先读取后移除,移除头部,并返回结果
/// </summary>
/// <param name="listId"></param>
/// <returns></returns>
string RemoveStartFromList(string listId);
/// <summary>
/// 先读取后移除,移除尾部,并返回结果
/// </summary>
/// <param name="listId"></param>
/// <returns></returns>
string RemoveEndFromList(string listId);
/// <summary>
/// 从一个 list 尾部移除一个元素,然后把这个数据添加到另一个 list 头部,并返回移动的值
/// </summary>
/// <param name="fromListId"></param>
/// <param name="toListId"></param>
/// <returns></returns>
string PopAndPushItemBetweenLists(string fromListId, string toListId);
set
set 也是一个集合,自动去重的一个集合
setId - value
两种数据结构
- intzset:
- 组成:
- 编码方式:int16,int32,int64
- 长度
- 数据内容:整型数据
- 操作方式,先使用 int16 ,如果有数据大于 int16 就全部变成 int32,int64同理
- 数值从小到大排序,折棒/二分查找
- 组成:
- HashTable:
- 存在不是整型数据的值,或者有数据超过int64,使用 HashTable
- 数据个数超过512,使用 HashTable,这个数值可以修改
代码操作
/// <summary>
/// 通过 setId 给 set 集合添加一个数据
/// </summary>
/// <param name="setId"></param>
/// <param name="item"></param>
void AddItemToSet(string setId, string item);
/// <summary>
/// 通过 setId 获取 set 集合中的数据个数
/// </summary>
/// <param name="setId"></param>
/// <returns></returns>
long GetSetCount(string setId);
/// <summary>
/// 通过 setId 给 set 集合添加多个数据
/// </summary>
/// <param name="setId"></param>
/// <param name="items"></param>
void AddRangeToSet(string setId, List<string> items);
/// <summary>
/// 通过 setId 获取 set 集合
/// </summary>
/// <param name="setId"></param>
/// <returns></returns>
HashSet<string> GetAllItemsFromSet(string setId);
/// <summary>
/// 通过 setId 从 set 集合中随机获取一个数据
/// </summary>
/// <param name="setId"></param>
/// <returns></returns>
string GetRandomItemFromSet(string setId);
/// <summary>
/// 通过 setId 从 set 集合中随机返回一个数据,并删除
/// </summary>
/// <param name="setId"></param>
/// <returns></returns>
string PopItemFromSet(string setId);
/// <summary>
/// 通过 setId 从 set 集合中删除指定的数据
/// </summary>
/// <param name="setId"></param>
/// <param name="item"></param>
void RemoveItemFromSet(string setId, string item);
/// <summary>
/// 从原来的集合,移除值到新的一个集合中去
/// </summary>
/// <param name="fromSetId"></param>
/// <param name="toSetId"></param>
/// <param name="item"></param>
void MoveBetweenSets(string fromSetId, string toSetId, string item);
/// <summary>
/// 获取多个 set 集合的交集
/// </summary>
/// <param name="setIds"></param>
/// <returns></returns>
HashSet<string> GetIntersectFromSets(params string[] setIds);
/// <summary>
/// 获取多个 set 集合的并集
/// </summary>
/// <param name="setIds"></param>
/// <returns></returns>
HashSet<string> GetUnionFromSets(params string[] setIds);
zset
zset 是一个集合,自动去重,而且多了个权重/分数的字段,从小到大排序
set - value - score
两种数据结构:
- ZipList:
- 组成:
- zlbytes:ZipList 的长度
- zltail:头
- 数据内容:数据和权重,根据权重排序
- zlend:尾
- 先找位置,再插值
- 数据个数小于等于128
- 每个数据的值不能超过64字节
- 组成:
- HashTable + SkipList
- HashTable:存储数据
- 有一个指向对应权重SkipList的指针
- SkipList:存储权重
- 有一个指向对应数据HashTable的指针
- 多层链表(最多32层,可以修改源代码),解决权重查找效率问题
- 指针解决了HashTable和SkipList内存共享问题
- HashTable:存储数据
代码操作
/// <summary>
/// 通过 setId 给 zset 集合添加一个数据
/// 没有写 score,默认最大值
/// </summary>
/// <param name="setId"></param>
/// <param name="value"></param>
/// <returns></returns>
bool AddItemToSortedSet(string setId, string value);
/// <summary>
/// 通过 setId 给 zset 集合添加一个数据,并设置权重值
/// </summary>
/// <param name="setId"></param>
/// <param name="value"></param>
/// <param name="score">权重值</param>
/// <returns></returns>
bool AddItemToSortedSet(string setId, string value, double score);
/// <summary>
/// 通过 setId 给 zset 集合添加多个数据,并设置权重值
/// </summary>
/// <param name="setId"></param>
/// <param name="values"></param>
/// <param name="score">权重值</param>
/// <returns></returns>
bool AddRangeToSortedSet(string setId, List<string> values, long score);
/// <summary>
/// 通过 setId 获取 zset 集合的数据
/// </summary>
/// <param name="setId"></param>
/// <returns></returns>
List<string> GetAllItemsFromSortedSet(string setId);
/// <summary>
/// 通过 setId 倒序获取 zset 集合的数据
/// </summary>
/// <param name="setId"></param>
/// <returns></returns>
List<string> GetAllItemsFromSortedSetDesc(string setId);
/// <summary>
/// 通过 setId 获取 zset 集合中指定开始到结束索引的数据集合
/// </summary>
/// <param name="setId"></param>
/// <param name="fromRank"></param>
/// <param name="toRank"></param>
/// <returns></returns>
List<string> GetRangeFromSortedSet(string setId, int fromRank, int toRank);
/// <summary>
/// 通过 setId 倒序获取 zset 集合中指定开始到结束索引的数据集合
/// </summary>
/// <param name="setId"></param>
/// <param name="fromRank"></param>
/// <param name="toRank"></param>
/// <returns></returns>
List<string> GetRangeFromSortedSetDesc(string setId, int fromRank, int toRank);
/// <summary>
/// 通过 setId 获取 zset 集合中指定开始到结束索引的数据集合,带权重
/// </summary>
/// <param name="setId"></param>
/// <param name="fromRank"></param>
/// <param name="toRank"></param>
/// <returns></returns>
IDictionary<string, double> GetRangeWithScoresFromSortedSet(string setId, int fromRank, int toRank);
/// <summary>
/// 通过 setId 倒序获取 zset 集合中指定开始到结束索引的数据集合,带权重
/// </summary>
/// <param name="setId"></param>
/// <param name="fromRank"></param>
/// <param name="toRank"></param>
/// <returns></returns>
IDictionary<string, double> GetRangeWithScoresFromSortedSetDesc(string setId, int fromRank, int toRank);
/// <summary>
/// 获取多个 zset 的交集
/// 相同数据的权重会相加
/// </summary>
/// <param name="intoSetId">存放交集的集合</param>
/// <param name="setIds"></param>
/// <returns>返回交集的数据个数</returns>
long StoreIntersectFromSortedSets(string intoSetId, params string[] setIds);
/// <summary>
/// 获取多个 zset 的并集
/// 相同数据的权重会相加
/// </summary>
/// <param name="intoSetId">存放并集的集合</param>
/// <param name="setIds"></param>
/// <returns>返回并集的数据个数</returns>
long StoreUnionFromSortedSets(string intoSetId, params string[] setIds);
通用的代码操作
/// <summary>
/// 给 key 设置过期时间
/// </summary>
/// <param name="key">键</param>
/// <param name="expireAt">过期时间</param>
/// <returns></returns>
bool ExpireEntryAt(string key, DateTime expireAt);
/// <summary>
/// 给 key 设置持续时间
/// </summary>
/// <param name="key">键</param>
/// <param name="expireIn">持续时间</param>
/// <returns></returns>
bool ExpireEntryIn(string key, TimeSpan expireIn);
/// <summary>
/// 获取 key 的过期时间
/// </summary>
/// <param name="key"></param>
/// <returns></returns>
TimeSpan? GetTimeToLive(string key);
/// <summary>
/// 删除当前数据库中的所有的 key
/// </summary>
void FlushDb();
注意
如果需要将引用对象放进 string、hash、list、set、zset 里面,value 就必须使用 JSON 序列化引用对象
其它数据类型
Bitmaps
redis 提供了 Bitmaps 这个“数据类型”,可以实现对位的操作,合理地使用操作位能够有效的提高内存使用率和开发效率
- Bitmaps 本身不是一种数据类型,实际上它就是字符串(key-value),但是它可以对字符串的位进行操作
- Bitmaps 单独提供了一套命令,所以在 redis 中使用 bitmaps 和使用字符串的方法不太相同。可以把 Bitmaps 想象成一个以位为单位的数组,数组的每个单元只能存储 0 和 1 ,数组的索引在 Bitmaps 中叫做偏移量
命令
setbit <key> <offset> <value>:设置 Bitmaps 中某个偏移量的值 (0 或 1)getbit <key> <offset>:获取 Bitmaps 中某个偏移量的值bitcount <key> [start] [end]:统计字符串被设置为 1 的 bit 数,start 和 end 为可选参数,表示开始位置和截止位置,单位是字节,也就是 8 个一组,这个位置也是从 0 开始bitop and/or/not/xor <destkey> [key ...]:复合操作,它可以做多个 Bitmaps 的 and(交集),or(并集),not(非),xor(异或)操作,并将结果保存在 destkey 中
实例:
每个独立用户是否访问过网站存放在 Bitmaps 中,将访问的用户记作 1 ,没有访问的用户记作 0,用偏移量作为用户的 id
设置键的第 offset 个位的值(从 0 算起),假设现在有 20 个用户,用户 id 为 1,11,15,19 的用户对网站进行了访问,那么当前 Bitmaps 初始化结果就是0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 1
统计当天访问网站的人数,可以使用日期作为 key,使用 bitcount 统计
统计多个不同日期访问网站的人数(用户可重复),可以使用 bitop 的 or 操作进行统计
统计多个不同日期访问网站的相同人数(用户不重复),可以使用 bitop 的 and 操作进行统计
缺点:
在第一次初始化 Bitmaps 时,假如偏移量(用户 id)非常大,那么整个初始化过程执行会比较慢,可能会造成 redis 的阻塞
Bitmaps 与 set 对比
假设网站有 1 亿用户,每天独立访问的用户有 5 千万,如果每天用 set 和 Bitmaps 分别存储活跃用户可以得到以下结果
- 每个用户 id 占用空间:set 64 位,Bitmaps 1 位
- 需要存储的用户量:set 5 千万,Bitmaps 1 亿
- 全部内存量:set = 64位 * 5千万 = 400MB,Bitmaps = 1位 * 1亿 = 12.5MB
如果该网站每天的独立访问用户很少,只有 10 万
- 每个用户 id 占用空间:set 64 位,Bitmaps 1 位
- 需要存储的用户量:set 10 万,Bitmaps 1 亿
- 全部内存量:set = 64位 * 10万 = 800KB,Bitmaps = 1位 * 1亿 = 12.5MB
HyperLogLog
在工作当中,我们经常会遇到与统计相关的功能需求,比如统计网站的页面访问量,可以使用 redis 的 incr 与 incrby 轻松实现
但是独立访客、独立IP数、搜索记录数等需要去重和计数的问题如何解决?这种求集合中不重复元素个数的问题称为基数问题
解决基数问题有很多种方案:
- 数据存储在 MySQL 中,使用 distinct count 计算不重复个数
- 使用 redis 提供的 hash、set、bitmaps 等数据结构来处理
以上方案结果精确,但随着数据不断增加,导致占用空间越来越大,对于非常大的数据集是不切实际的
HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或体积非常非常大时,计算基数所需的空间总是固定的,并且是很小的
在 redis 中,每个 HyperLogLog 只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会存储输入元素本身,所以 HyperLogLog 不能像 set 那样,返回输入的各个元素
什么是基数?
比如数据集{1,3,5,5,7,7,9},那么这个数据集的基数集为{1,3,5,7,9},基数(不重复元素)为 5,基数估计就是在误差可接受的范围内,快速计算基数
命令
pfadd <key> <element> [element ...]:添加指定的元素到 HyperLogLog 中,可以添加多个pfcount <key> [key ...]:计算 key 的近似基数,可以计算多个 keypfmerge <destkey> <sourcekey> [sourcekey ...]:将一个或多个 sourcekey 合并后的结果存储在另一个 destkey 中
Geospatial
redis 3.2 中增加了对 GEO 类型的支持,GEO 就是 Geographic(地理信息)。该类型就是元素的 2 维坐标,在地图上就是经纬度。redis 基于该类型,提供了经纬度设置、查询、范围查询、距离查询、经纬度Hash等常见操作
两极无法直接添加,一般会下载城市数据,直接通过程序一次性导入。
有效的经度从 -180 度到 180 度。有效的纬度从 -85.05112878度 到 85.05112878度。当坐标位置超出指定范围时,该命令将会返回一个错误。已经添加的数据是无法再次往里面添加的
命令
geoadd <key> <longitude> <latitude> <member> [longitude latitude member ...]:添加地理位置(经度,纬度,名称)geopos <key> <member> [member ...]:获得指定地区的坐标值geolist <key> <member1> <member2> [m|km|ft|mi]:获取两个位置之间的直线距离georadius <key> <longitudde> <latitude> <redius> m|km|ft|mi:以给定的经纬度为中心,找出 key 中某一 redius(半径) 内的元素
单位:
- m:表示单位米,这是默认值
- km:表示单位千米
- mi:表示单位英里
- ft:表示单位英尺
