【学习记录】Golang
内容大部分来自大佬博客Go 语言设计与实现
基础
Q:rune 和 byte
A:rune是用来区分字符值和整数值的
- byte 等同于int8,即一个字节长度,常用来处理ascii字符
- rune 等同于int32,即4个字节长度,常用来处理unicode或utf-8字符
slice
Q:slice与数组区别
A:数组是一种具有固定长度的基本数据结构,一旦创建了它的长度就不允许改变。而slice是一个引用类型,它自身也是个结构体。len表示可用元素数量,cap表示容量。当向slice中追加元素时,在容量不足时会自动扩容
Q:slice底层
A: slice底层就是数组,运行时表示 reflect.SliceHeader
-
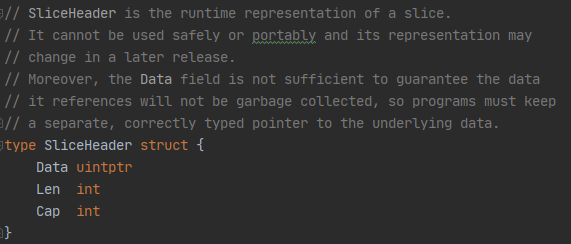
- Data 指向数组的指针
- Len 当前切片长度
- Cap 当前切片容量,既Data数组大小
Q:slice扩容机制
A:
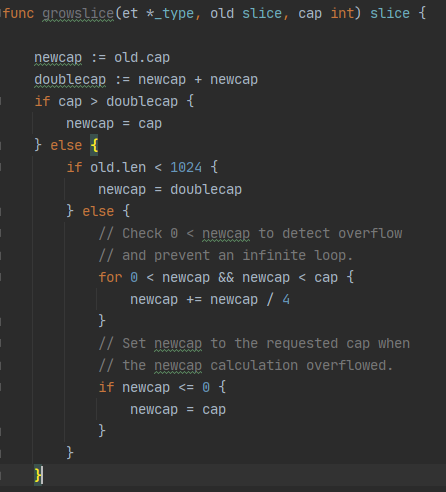
- 如果期望容量大于当前容量的两倍,就会使用期望容量
- 当前切片长度小于1024就会将容量翻倍
- 如果切片长度大于1024就会每次增加25%的容量,直到新容量大于期望容量
- 然后根据切片中的元素大小对齐内存。
- append追加操作促发扩容
- 如果不赋值给原来的切片,会创建一个新的数组,将原来的元素拷贝过去,完成后写入新数据
- 如果赋值给原来的切片,处理逻辑差不多,但是Go编译器会进行优化,不会产生数据拷贝
指针
Q:new和make的区别
A:
- make的作用是初始化内置的数据结构如slice,map,channel。
- make([]int,0) 返回一个
reflect.SliceHeader结构体 - make(map[int]bool,0) 返回一个指向
runtime.hmap结构体的指针 - make(chan int,1) 返回一个指向
runtime.hchan结构体的指针
- make([]int,0) 返回一个
- new的作用是根据传入的类型分配一片内存空间并返回指向这片内存空间的指针
Q:值传递和引用传递
A:Go选择了传值的方式,无论是传递基本类型,结构体还是指针都会对传递的参数进行拷贝
- 传值:函数调用时会对参数进行拷贝,被调用方和调用方两者持有不相关的两份数据
- 传引用:函数调用时会传递参数的指针,被调用方和调用方两者持有相同的数据,任意一方修改都会影响另外一方
Hash
hmap结构体
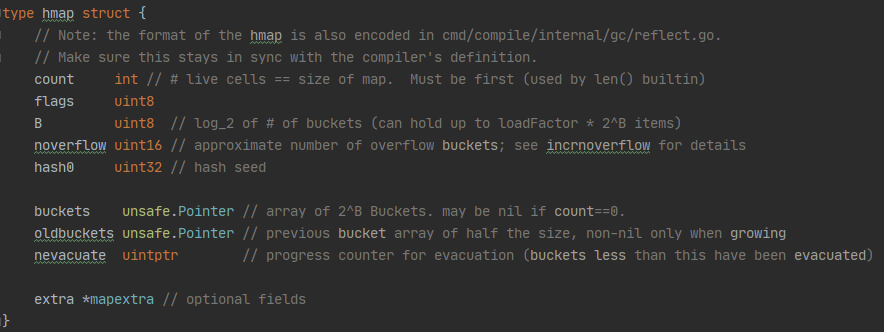
count 表示当前哈希表中的元素数量
B表示当前哈希表的buckets数量
hash0 哈希种子,哈希结果引入随机性
oldbuckets 哈希扩容时用于保存之前的buckets字段,大小是当前buckets的一半
Q:哈希过程
A:
- 开放地址法:依次探测和比较数组中的元素以判断目标键值对是否存在于哈希表中
- 当向哈希表中写入新数据时,如果发生了冲突,就将键值对写入到下一个索引不为空的位置
- 查找时,从索引的位置开始线性探测数组,找到目标键值对或者空内存就意味着这一次查询操作的结束
- 拉链法:数组+链表,部分加入红黑树提高效率。
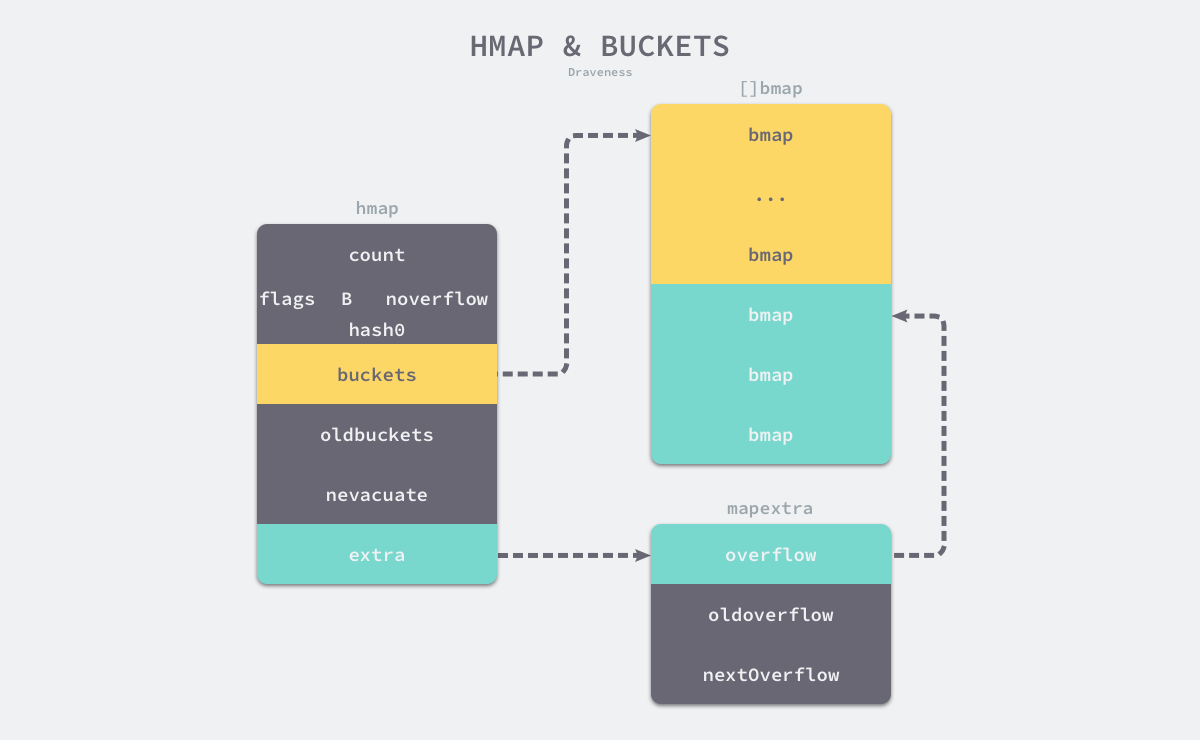
Q:哈希桶
A:

-
每个bmap可以存8个键值对,当单个桶装满的时候就会用extra.nextOverflow中桶存储溢出的数据。
-
tophash存储了键的哈希的高8位,通过比较不同的键的hash高8位可以减少访问键值对次数以提高性能。
-
随着哈希存储的数据逐渐增多,我们会扩容哈希表或者使用额外的桶存储溢出的数据,不会让单个桶中的数据超过8个,创建过多的溢出桶最终也会导致哈希的扩容。
-
bmap在编译时会重新构建结构
type bmap struct { topbits [8]uint8 keys [8]keytype values [8]valuetype pad uintptr overflow uintptr }
Q: map 线程安全
A: 通过 使用mutex保证线程安全,或者使用sync.map
Q: sync.map与map的区别,怎么实现的
A:


- 无须初始化,直接声明即可。
- sync.Map 不能使用 map 的方式进行取值和设置等操作,而是使用 sync.Map 的方法进行调用,Store 表示存储,Load 表示获取,Delete 表示删除。
- 使用 Range 配合一个回调函数进行遍历操作,通过回调函数返回内部遍历出来的值,Range 参数中回调函数的返回值在需要继续迭代遍历时,返回 true,终止迭代遍历时,返回 false。
runtime
同步原语与锁
Mutex

- Mutex状态

默认所有状态位为0,
-
locked:锁的锁定状态
-
woken:从正常模式被唤醒
-
starving:锁进入饥饿状态
-
waitersCount:锁上等待的G个数
-
Mutex有两种模式
- 正常模式:锁的等待者会按照先进先出的顺序获取锁,
- 饥饿模式:互斥锁会直接交给等待队列最前面的G。新的G在该状态下不能获取锁,也不会进入自旋状态,会在队列末尾等待。
- 正常模式下的互斥锁能够提供更换的性能,饥饿模式能避免G由于陷入等待无法获取锁而造成高尾延迟
-
Mutex 实现了 Locker 接口的两个方法,使用
Mutex.Lock加锁,Mutex.Unlock解锁 -
Lock
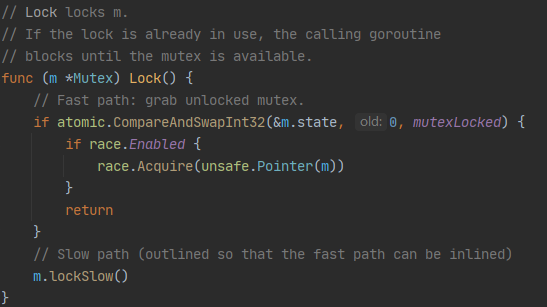
加锁时,如果锁状态locked为1会调用lockSlow进入自旋等待锁的释放,使用CAS修改锁状态。
-
自旋是一种多线程同步机制,当前的进程在进入自旋的过程中会一直保存CPU的占用,直到满足某个条件。在多喝CPU上,自旋可以避免G的切换。
-
互斥锁只能在普通状态下才能进入自旋
-
需要运行在多cpu上,当前G为了获取该锁进入自旋的次数小于4,当前机器上至少存在一个正在运行的处理器P并且处理的运行队列为空。
-
流程
- 如果互斥锁处于初始化状态,会通过置位 mutexLocked 加锁;
- 如果互斥锁处于 mutexLocked 状态并且在普通模式下工作,会进入自旋,执行 30 次 PAUSE 指令消耗 CPU 时间等待锁的释放;
- 如果当前 Goroutine 等待锁的时间超过了 1ms,互斥锁就会切换到饥饿模式;
- 互斥锁在正常情况下会通过 runtime.sync_runtime_SemacquireMutex 将尝试获取锁的 Goroutine 切换至休眠状态,等待锁的持有者唤醒;
- 如果当前 Goroutine 是互斥锁上的最后一个等待的协程或者等待的时间小于 1ms,那么它会将互斥锁切换回正常模式;
-
CAS(Compare And Swap)
- 无锁是一种乐观的策略,它假设线程访问共享资源不会发生冲突,所以不需要加锁,因此线程将不断执行,不需要停止。一旦碰到冲突,就重试当前操作直到没有冲突为止。
- 无锁的策略使用一种叫做比较交换的技术(CAS Compare And Swap)来鉴别线程冲突,一旦检测到冲突产生,就重试当前操作直到没有冲突为止。
- 算法思路:V (准备要被更新的变量) 是共享变量,我们拿着自己准备的这个E (期望的值),去跟V去比较,如果E == V ,说明当前没有其它线程在操作,所以,我们把N (新值) 这个值 写入对象的 V 变量中。如果 E != V ,说明我们准备的这个E,已经过时了,所以我们要重新准备一个最新的E ,去跟V 比较,比较成功后才能更新V的值为N。
- 无锁操作即CAS操作天生免疫死锁
- CAS操作是一条CPU的原子指令,所以不会有线程安全问题。
-
Unlock
- 使用 直接设置状态为为0,快速解锁
- 流程
- 当互斥锁已经被解锁时,调用 sync.Mutex.Unlock 会直接抛出异常;
- 当互斥锁处于饥饿模式时,将锁的所有权交给队列中的下一个等待者,等待者会负责设置 mutexLocked 标志位;
- 当互斥锁处于普通模式时,如果没有 Goroutine 等待锁的释放或者已经有被唤醒的 Goroutine 获得了锁,会直接返回;在其他情况下会通过 sync.runtime_Semrelease 唤醒对应的 Goroutine;
RWMutex
读写互斥锁,不限制资源的并发读,但是读写,写写无法并行执行
- 结构体
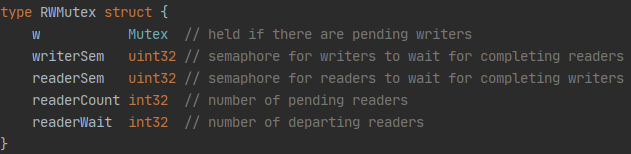
w 复用互斥锁提供的能力
writerSem 和 readerSem 分别用于写等待读和读等待写
readerCount 当前正在执行的读操作数量
readerWait 表示当写操作被阻塞时等待的读操作个数
-
写锁
- 调用 sync.RWMtuex.Lock 方法获取锁
- 调用w.Lock方法阻塞后续的写操作
- 将 readerCount 置为负数阻塞后续读操作
- 如果有其他G持有读锁,当前G会进入休眠等待所有读操作完成。
- 调用 sync.RWMtuex.Unlock 方法释放锁
- 将 readerCount 变回正数,释放读锁
- 通过for循环释放所有因为读锁而陷入等待的G
- 调用w.Unlock释放写锁
- 调用 sync.RWMtuex.Lock 方法获取锁
-
读锁
- 调用 sync.RWMutex.RLock, 该方法会通过 atomic.AddInt32 将 readerCount + 1
- 如果该方法返回负数,代表其他Goroutine获得了写锁,当前G会陷入休眠等待锁的释放
- 如果非负数,就成功返回
- 调用 sync.RWMutex.RUnlock, 该方法会通过 atomic.AddInt32 将 readerCount - 1
- 如果返回值 >= 0 读锁直接解锁成功
- 如果返回值 < 0 有一个正在执行的写锁操作,会通过函数调用减少readerWait,并在所有读操作被释放之后触发写操作的信号量 writerSem ,调度器会唤醒尝试获取写锁的Goroutine
- 调用 sync.RWMutex.RLock, 该方法会通过 atomic.AddInt32 将 readerCount + 1
Channel
不要通过共享内存的方式进行通信,而是应该通过通信的方式共享内存。
Channel收发操作都采用了先进先出的设计
- 先从Channel读取数据的Goroutine会先接收到数据
- 先向Channel发送数据的Goroutine会得到先发送数据的权力
Channel底层
type hchan struct {
qcount uint // total data in the queue
dataqsiz uint // size of the circular queue
buf unsafe.Pointer // points to an array of dataqsiz elements
elemsize uint16
closed uint32
elemtype *_type // element type
sendx uint // send index
recvx uint // receive index
recvq waitq // list of recv waiters
sendq waitq // list of send waiters
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex
}
type waitq struct {
first *sudog
last *sudog
}
-
结构体中的五个字段
qcount、dataqsiz、buf、sendx、recv构建底层的循环队列:qcount— Channel 中的元素个数;dataqsiz— Channel 中的循环队列的长度;buf— Channel 的缓冲区数据指针;sendx— Channel 的发送操作处理到的位置;recvx— Channel 的接收操作处理到的位置;
-
elemsize和elemtype分别表示当前 Channel 能够收发的元素类型和大小 -
sendq和recvq存储了当前 Channel 由于缓冲区空间不足而阻塞的 Goroutine 列表 -
发送数据
- 向通道内发送数据的几种情况
- 如果当前 Channel 的
recvq上存在已经被阻塞的 Goroutine,那么会直接将数据发送给当前 Goroutine 并将其设置成下一个运行的 Goroutine; - 如果 Channel 存在缓冲区并且其中还有空闲的容量,我们会直接将数据存储到缓冲区
sendx所在的位置上; - 如果不满足上面的两种情况,会创建一个
runtime.sudog结构并将其加入 Channel 的sendq队列中,当前 Goroutine 也会陷入阻塞等待其他的协程从 Channel 接收数据;
- 如果当前 Channel 的
- 发送数据的过程中包含几个会触发 Goroutine 调度的时机:
- 发送数据时发现 Channel 上存在等待接收数据的 Goroutine,立刻设置处理器的
runnext属性,但是并不会立刻触发调度; - 发送数据时并没有找到接收方并且缓冲区已经满了,这时会将自己加入 Channel 的
sendq队列并调用runtime.goparkunlock触发 Goroutine 的调度让出处理器的使用权;
- 发送数据时发现 Channel 上存在等待接收数据的 Goroutine,立刻设置处理器的
- 向通道内发送数据的几种情况
-
接收数据
- 从 Channel 中接收数据时可能会发生的五种情况
- 如果 Channel 为空,那么会直接调用
runtime.gopark挂起当前 Goroutine; - 如果 Channel 已经关闭并且缓冲区没有任何数据,
runtime.chanrecv会直接返回; - 如果 Channel 的
sendq队列中存在挂起的 Goroutine,会将recvx索引所在的数据拷贝到接收变量所在的内存空间上并将sendq队列中 Goroutine 的数据拷贝到缓冲区; - 如果 Channel 的缓冲区中包含数据,那么直接读取
recvx索引对应的数据; - 在默认情况下会挂起当前的 Goroutine,将
runtime.sudog结构加入recvq队列并陷入休眠等待调度器的唤醒;
- 如果 Channel 为空,那么会直接调用
- 从 Channel 接收数据时,会触发 Goroutine 调度的两个时机:
- 当 Channel 为空时;
- 当缓冲区中不存在数据并且也不存在数据的发送者时;
- 从 Channel 中接收数据时可能会发生的五种情况
-
通道关闭
当 Channel 是一个空指针或者已经被关闭时,Go 语言运行时都会直接崩溃并抛出异常:
Goroutine
底层实现
为什么goroutine比线程更轻量
调度器
历史
0.x 单线程调度器 GM模型
1.0 多线程调度器
- 调度器和锁是全局资源,所有的调度状态都是中心化存储的,锁竞争问题严重;
- 线程需要经常互相传递可运行的 Goroutine,引入了大量的延迟;
- 每个线程都需要处理内存缓存,导致大量的内存占用并影响数据局部性;
- 系统调用频繁阻塞和解除阻塞正在运行的线程,增加了额外开销;
1.1 任务窃取调度器
- 在当前的 G-M 模型中引入了处理器 P,增加中间层;
- 在处理器 P 的基础上实现基于工作窃取的调度器;
- 当前处理器本地的运行队列中不包含 Goroutine 时,会触发工作窃取,从其它的处理器的队列中随机获取一些 Goroutine
1.2 ~ 至今 抢占式调度器
GMP模型
构成
-
G — 表示 Goroutine,它是一个待执行的任务;
-
M — 表示操作系统的线程,它由操作系统的调度器调度和管理;
-
P — 表示处理器,它可以被看做运行在线程上的本地调度器;
-
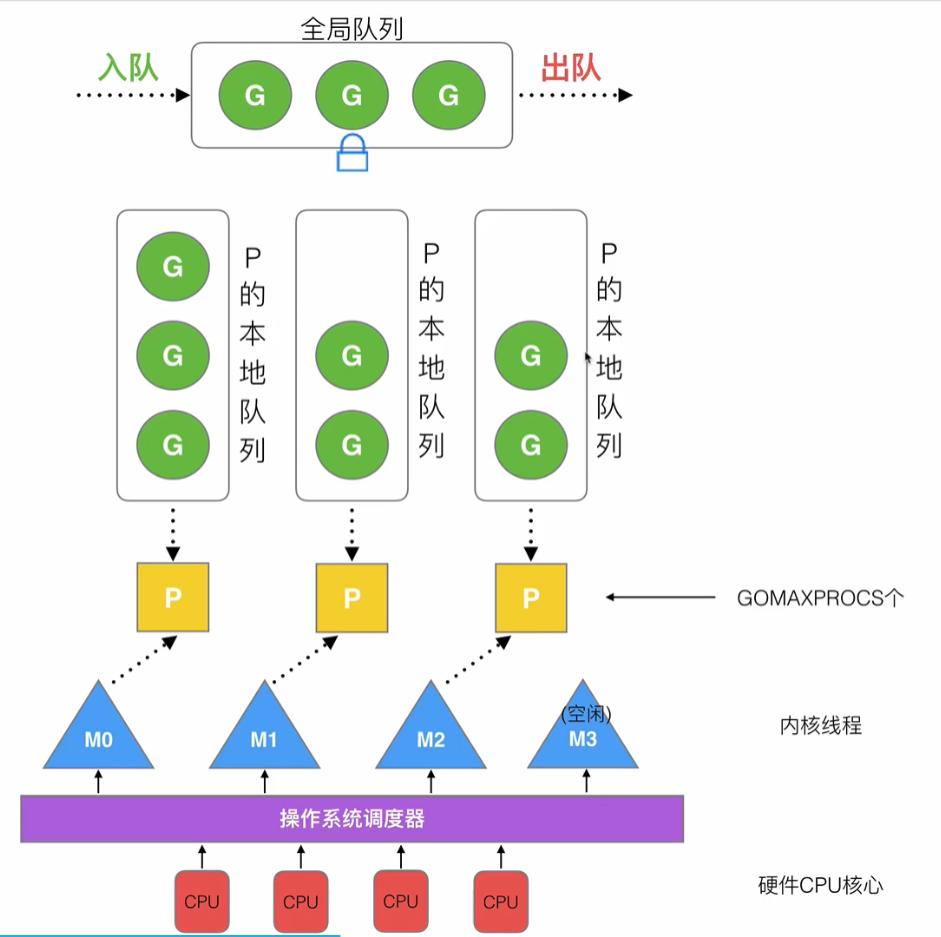
全局队列 — 存放等待运行的G
-
本地队列 — 存放等待运行的G(最多256个G)
-
P列表 — 程序启动时创建,最多有GOMAXPROCS个(可配置)
-
M列表 — 当前操作系统分配到当前G0程序的内核线程数,有一个M阻塞则会创建一个新的M,如果有空闲就会回收。
G
Goroutine 是 Go 语言调度器中待执行的任务,它在运行时调度器中的地位与线程在操作系统中差不多,但是它占用了更小的内存空间,也降低了上下文切换的开销。
Goroutine 只存在于 Go 语言的运行时,它是 Go 语言在用户态提供的线程,作为一种粒度更细的资源调度单元,如果使用得当能够在高并发的场景下更高效地利用机器的 CPU。
Goroutine运行时使用私有结构体runtime.g表示,这个私有结构体非常复杂,总共包含 40 多个用于表示各种状态的成员变量。
type g struct {
// 栈相关
stack stack // 当前 Goroutine 的栈内存范围
stackguard0 uintptr // 用于调度器抢占式调度
// 抢占相关
preempt bool // 抢占信号
preemptStop bool // 抢占时将状态修改成 `_Gpreempted`
preemptShrink bool // 在同步安全点收缩栈
// defer panic
_panic *_panic // 最内侧的 panic 结构体
_defer *_defer // 最内侧的延迟函数结构体
m *m // 当前 Goroutine 占用的线程,可能为空
sched gobuf // Goroutine 的状态
atomicstatus uint32 // 存储 Goroutine 的调度相关的数据
...
}
type gobuf struct {
sp uintptr // 栈指针
pc uintptr // 程序计数器
g guintptr // 持有 runtime.gobuf 的 Goroutine
ret sys.Uintreg // 系统调用的返回值
...
}
状态
| 状态 | 描述 |
|---|---|
_Gidle |
刚刚被分配并且还没有被初始化 |
_Grunnable |
没有执行代码,没有栈的所有权,存储在运行队列中 |
_Grunning |
可以执行代码,拥有栈的所有权,被赋予了内核线程 M 和处理器 P |
_Gsyscall |
正在执行系统调用,拥有栈的所有权,没有执行用户代码,被赋予了内核线程 M 但是不在运行队列上 |
_Gwaiting |
由于运行时而被阻塞,没有执行用户代码并且不在运行队列上,但是可能存在于 Channel 的等待队列上 |
_Gdead |
没有被使用,没有执行代码,可能有分配的栈 |
_Gcopystack |
栈正在被拷贝,没有执行代码,不在运行队列上 |
_Gpreempted |
由于抢占而被阻塞,没有执行用户代码并且不在运行队列上,等待唤醒 |
_Gscan |
GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存在 |
M
M 是操作系统线程。调度器最多可以创建 10000 个线程,但是其中大多数的线程都不会执行用户代码(可能陷入系统调用),最多只会有 GOMAXPROCS 个活跃线程能够正常运行。
默认情况下,运行时会将 GOMAXPROCS 设置成当前机器的核数,我们也可以在程序中使用runtime.GOMAXPROCS来改变最大的活跃线程数。
默认的设置不会频繁触发操作系统的线程调度和上下文切换,所有的调度都会发生在用户态,由 Go 语言调度器触发,能够减少很多额外开销。
一个四核机器会创建四个活跃的操作系统线程,每一个线程都对应一个运行时中的 runtime.m结构体
type m struct {
// goroutine 相关
g0 *g // 持有调度栈的 Goroutine
curg *g // 当前线程上运行的用户 Goroutine
// 处理器相关
p puintptr // 持有调度栈的 Goroutine
nextp puintptr // 持有调度栈的 Goroutine
oldp puintptr // 持有调度栈的 Goroutine
... // 还包含大量与线程状态、锁、调度、系统调用有关的字段
}
- g0 是一个运行时中比较特殊的 Goroutine,它会深度参与运行时的调度过程,包括 Goroutine 的创建、大内存分配和 CGO 函数的执行。
- 每次启动一个M,都会第一个创建的goroutine
- 仅用于负责调度的G
- 不指向任何可执行的函数
- 每个M都有自己的G0
- 在调用或系统调用时会使用M切换到G0来调度
P
调度器中的处理器 P 是线程和 Goroutine 的中间层,它能提供线程需要的上下文环境,也会负责调度线程上的等待队列,通过处理器 P 的调度,每一个内核线程都能够执行多个 Goroutine,它能在 Goroutine 进行一些 I/O 操作时及时让出计算资源,提高线程的利用率。
因为调度器在启动时就会创建 GOMAXPROCS 个处理器,所以 Go 语言程序的处理器数量一定会等于 GOMAXPROCS,这些处理器会绑定到不同的内核线程上。
type p struct {
m muintptr // 线程与处理器之间的关系
runqhead uint32 // 处理器持有的运行队列
runqtail uint32 // 处理器持有的运行队列
runq [256]guintptr // 处理器持有的运行队列
runnext guintptr // 线程下一个需要执行的 Goroutine。
... // 包括与性能追踪、垃圾回收和计时器相关的字段
}
| 状态 | 描述 |
|---|---|
_Pidle |
处理器没有运行用户代码或者调度器,被空闲队列或者改变其状态的结构持有,运行队列为空 |
_Prunning |
被线程 M 持有,并且正在执行用户代码或者调度器 |
_Psyscall |
没有执行用户代码,当前线程陷入系统调用 |
_Pgcstop |
被线程 M 持有,当前处理器由于垃圾回收被停止 |
_Pdead |
当前处理器已经不被使用 |
创建 G
先从处理器的 gFree 列表中查找空闲的 Goroutine,如果不存在空闲的 Goroutine,会通过 runtime.malg 创建一个栈大小足够的新结构体。
将 fn 函数的所有参数对应的内存空间整块拷贝到栈上
设置新的 Goroutine 结构体的参数,包括栈指针、程序计数器并更新其状态到 _Grunnable 并返回
初始化结构体( 获取新的G )
- 从 Goroutine 所在处理器的
gFree列表或者调度器的sched.gFree列表中获取- 当处理器的 Goroutine 列表为空时,会将调度器持有的空闲 Goroutine 转移到当前处理器上,直到
gFree列表中的 Goroutine 数量达到 32; - 当处理器的 Goroutine 数量充足时,会从列表头部返回一个新的 Goroutine;
- 当处理器的 Goroutine 列表为空时,会将调度器持有的空闲 Goroutine 转移到当前处理器上,直到
- 调用
runtime.malg生成一个新的runtime.g并将结构体追加到全局的 Goroutine 列表allgs中。- 调用
runtime.malg初始化新的 G 结构,如果申请的堆栈大小大于 0,这里会通过runtime.stackalloc分配 2KB 的栈空间
- 调用
运行队列
runtime.runqput会将 Goroutine 放到运行队列上,这既可能是全局的运行队列,也可能是处理器本地的运行队列
func runqput(_p_ *p, gp *g, next bool) {
...
}
- 当
next为true时,将 Goroutine 设置到处理器的runnext作为下一个处理器执行的任务; - 当
next为false并且本地运行队列还有剩余空间时,将 Goroutine 加入处理器持有的本地运行队列; - 当处理器的本地运行队列已经没有剩余空间时就会把本地队列中的一部分 Goroutine 和待加入的 Goroutine 通过
runtime.runqputslow添加到调度器持有的全局运行队列上;
处理器本地的运行队列是一个使用数组构成的环形链表,它最多可以存储 256 个待执行任务
调度循环
调度器启动后调用runtime.schedule进入调度循环
func schedule() {
_g_ := getg()
top:
var gp *g
var inheritTime bool
if gp == nil {
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
if gp == nil {
gp, inheritTime = runqget(_g_.m.p.ptr())
}
if gp == nil {
gp, inheritTime = findrunnable()
}
execute(gp, inheritTime)
}
- schedule函数查找待执行的 Goroutine
- 为了保证公平,当全局运行队列中有待执行的 Goroutine 时,通过
schedtick保证有一定几率会从全局的运行队列中查找对应的 Goroutine (避免全局队列中的G被饿死,不过这个情况的概率较小) - 从处理器本地的运行队列中查找待执行的 Goroutine, runget方法
- 如果前两种方法都没有找到 Goroutine,会通过
runtime.findrunnable进行阻塞地查找 Goroutine;- 从本地运行队列、全局运行队列中查找;
- 从网络轮询器中查找是否有 Goroutine 等待运行;
- 通过
runtime.runqsteal尝试从其他随机的处理器中窃取待运行的 Goroutine,该函数还可能窃取处理器的计时器; - 当前函数一定会返回一个可执行的 Goroutine,如果当前不存在就会阻塞等待。
- 为了保证公平,当全局运行队列中有待执行的 Goroutine 时,通过
由 runtime.execute 执行获取的 Goroutine,做好准备工作后,它会通过 runtime.gogo将 Goroutine 调度到当前线程上。
触发调度
运行时会在线程启动 runtime.mstart和 Goroutine 执行结束 runtime.goexit0触发调度
运行时触发调度的几个路径:
- 主动挂起
- 系统调用
- 调用前准备工作
- 禁止线程上发生的抢占,防止出现内存不一致的问题;
- 保证当前函数不会触发栈分裂或者增长;
- 保存当前的程序计数器 PC 和栈指针 SP 中的内容;
- 将 Goroutine 的状态更新至
_Gsyscall; - 将 Goroutine 的处理器和线程暂时分离并更新处理器的状态到
_Psyscall; - 释放当前线程上的锁;
- 调用结束后恢复工作为当前 Goroutine 重新分配资源
- 路径1
- 如果 Goroutine 的原处理器处于
_Psyscall状态,会直接调用wirep将 Goroutine 与处理器进行关联; - 如果调度器中存在闲置的处理器,会调用
runtime.acquirep使用闲置的处理器处理当前 Goroutine;
- 如果 Goroutine 的原处理器处于
- 路径2 将当前 Goroutine 切换至
_Grunnable状态,并移除线程 M 和当前 Goroutine 的关联- 当我们通过
runtime.pidleget获取到闲置的处理器时就会在该处理器上执行 Goroutine - 在其它情况下,我们会将当前 Goroutine 放到全局的运行队列中,等待调度器的调度
- 当我们通过
- 路径1
- 调用前准备工作
- 协作式调度
- 系统监控
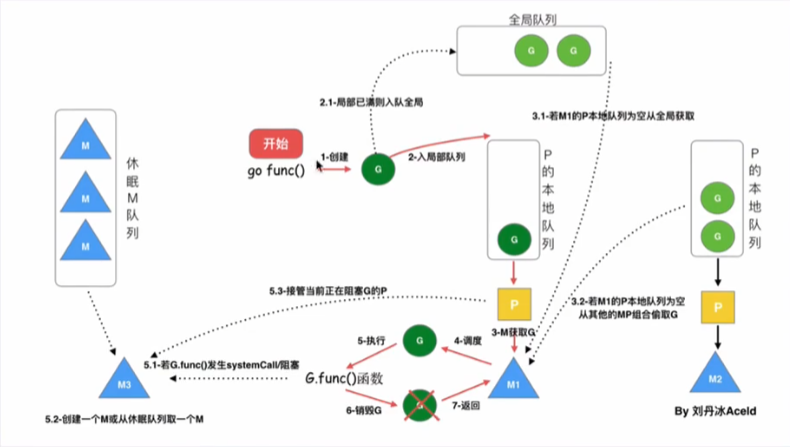
Q: 协程的调度
A:
- 全局G任务队列会和各个本地G任务队列按照一定的策略互相交换(满了,则把本地队列的一半送给全局队列)
- P是用一个全局数组(256)来保存的,并且维护着一个全局的P空闲链表
- 调度
- 创建一个G对象,加入到本地队列或者全局队列
- 如果还有空闲的P,则创建一个M
- M会启动一个底层线程,循环执行能找到的G任务
- G任务的执行顺序是,先从本地队列找,本地没有则从全局队列找(一次性转移(全局G个数/P个数)个,再去其它P中找(一次性转移一半)
- goroutine是按照抢占式调度的,一个goroutine最多执行10ms就会换作下一个

内存管理
对象大小
| 类别 | 大小 |
|---|---|
| 微对象 | (0 , 16B) |
| 小对象 | [16B , 32KB] |
| 大对象 | (32KB , +∞) |
绝大多数对象都是32KB以下
多级缓存
- 内存管理单元:内存管理的基本单元 runtime.mspan
- 线程缓存:与线程上的处理器一一绑定,主要用来缓存用户程序申请的微对象,每一个线程缓存持有68 * 2个 mspan
- 中心缓存:内存分配器的中心缓存,访问中心缓存中的内存管理单元需要使用互斥锁,同时持有两个 runtime.spanSet 分别存储包含空闲对象和不包含空闲对象的内存管理单元
- 页堆:mheap结构体,该结构体包含两组重要字段,一个是全局中心缓存列表central,一个是管理堆区内存区的arenas
线程缓存属于每一个独立的线程,可以满足绝大多数的内存分配需求。当线程缓存不能满足时,使用中心缓存作为补充,32KB以上的大对象,内存分配器会选择页堆直接分配大内存
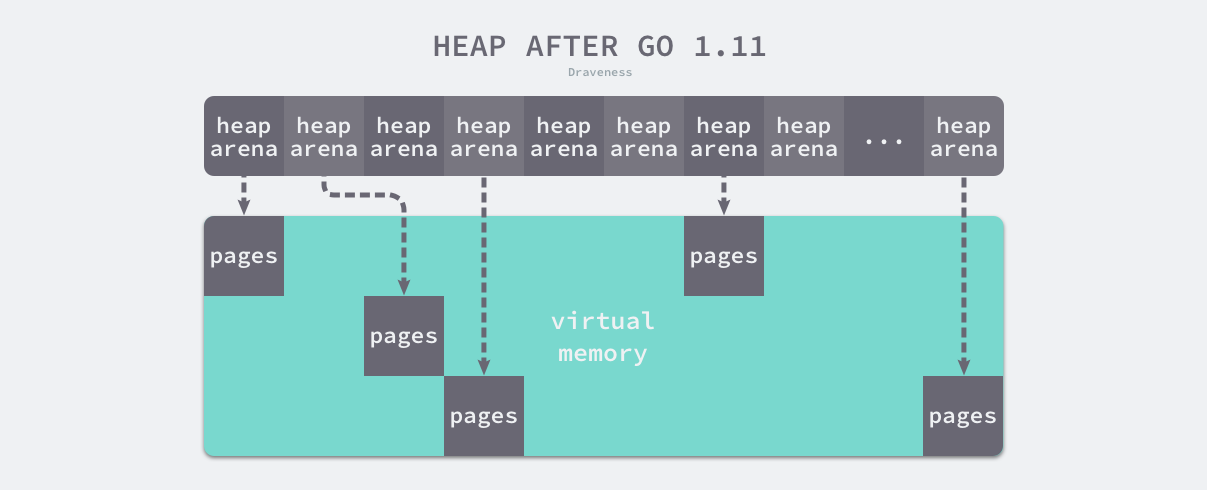
虚拟内存布局
1.10以前 堆区的内存空间都是连续的,1.11 GO使用稀疏的堆内存空间替代了连续的内存
每一个 heaparena 管理64MB的内存空间
内存分配
- 微对象,先使用微型内存分配器,再依次尝试线程缓存,中心缓存和堆分配内存
- 微型内存分配器:分配较小的字符串以及逃逸的临时变量,分配器可以将多个较小的内存分配请求合入同一个内存块,只有当内存块中的所有对象都需要被回收时,整片内存才可能被回收
- 小对象,依次尝试线程缓存,中心缓存和堆分配内存
- 大对象,直接在堆上分配内存
栈空间分配
栈区的内存一般由编译器自动分配和释放。go 使用BP和SP两个栈寄存器,分别储存了栈的基址指针和栈顶指针。BP和SP之间的内存就是当前函数的调用栈。
栈区内存都是从高地址向低地址扩展的,索引申请和释放栈内存时只需要修改SP寄存器的值。
逃逸分析
不需要分配到堆上的对象分配到了栈上 - 浪费内存空间
需要分配到堆上的对象分配到了栈上 - 悬挂指针,影响内存安全
Go 语言编译器使用逃逸分析决定哪些变量应该在栈上分配,哪些变量应该在堆上分配。
- 指向栈对象的指针不能存在于栈中
- 指向栈对象的指针不能在栈对象回收后存活
Q:内存逃逸
A:
执行逃逸分析命令go build -gcflags="-m" main.go
内存逃逸是指原本应该被存储在栈上的变量,因为一些原因被存储到了堆上。
- 指针逃逸 - 方法返回局部变量指针,就形成变量逃逸
- 栈空间不足逃逸 - 当切片长度扩大到10000时就会逃逸,实际上当栈空间不足以存放当前对象或无法判断当前切片长时会将对象分配到堆中
- 动态类型逃逸 - 编译期间很难确定其参数的具体类型,也能产生逃逸度
- 闭包引用对象逃逸 - 原本属于局部变量,由于闭包的引用,不得不放到堆上,以致产生逃逸
- 跨协程引用对象逃逸 - 原本属于A协程的变量,通过指针传递给B协程使用,产生逃逸
内存分配,什么分配在堆上,什么分配在栈上
垃圾回收
演进过程
- v1.0 — 完全串行的标记和清除过程,需要暂停整个程序;
- v1.1 — 在多核主机并行执行垃圾收集的标记和清除阶段;
- v1.3 — 运行时基于只有指针类型的值包含指针的假设增加了对栈内存的精确扫描支持,实现了真正精确的垃圾收集
- 将
unsafe.Pointer类型转换成整数类型的值认定为不合法的,可能会造成悬挂指针等严重问题;
- 将
- v1.5 — 实现了基于三色标记清扫的并发垃圾收集器
- 大幅度降低垃圾收集的延迟从几百 ms 降低至 10ms 以下;
- 计算垃圾收集启动的合适时间并通过并发加速垃圾收集的过程;
- v1.6 — 实现了去中心化的垃圾收集协调器;
- 基于显式的状态机使得任意 Goroutine 都能触发垃圾收集的状态迁移;
- 使用密集的位图替代空闲链表表示的堆内存,降低清除阶段的 CPU 占用
- v1.7 — 通过并行栈收缩将垃圾收集的时间缩短至 2ms 以内
- v1.8 — 使用混合写屏障将垃圾收集的时间缩短至 0.5ms 以内
- v1.9 — 彻底移除暂停程序的重新扫描栈的过程
- v1.10 — 更新了垃圾收集调频器(Pacer)的实现,分离软硬堆大小的目标
- v1.12 — 使用新的标记终止算法简化垃圾收集器的几个阶段
- v1.13 — 通过新的 Scavenger 解决瞬时内存占用过高的应用程序向操作系统归还内存的问题
- v1.14 — 使用全新的页分配器优化内存分配的速度
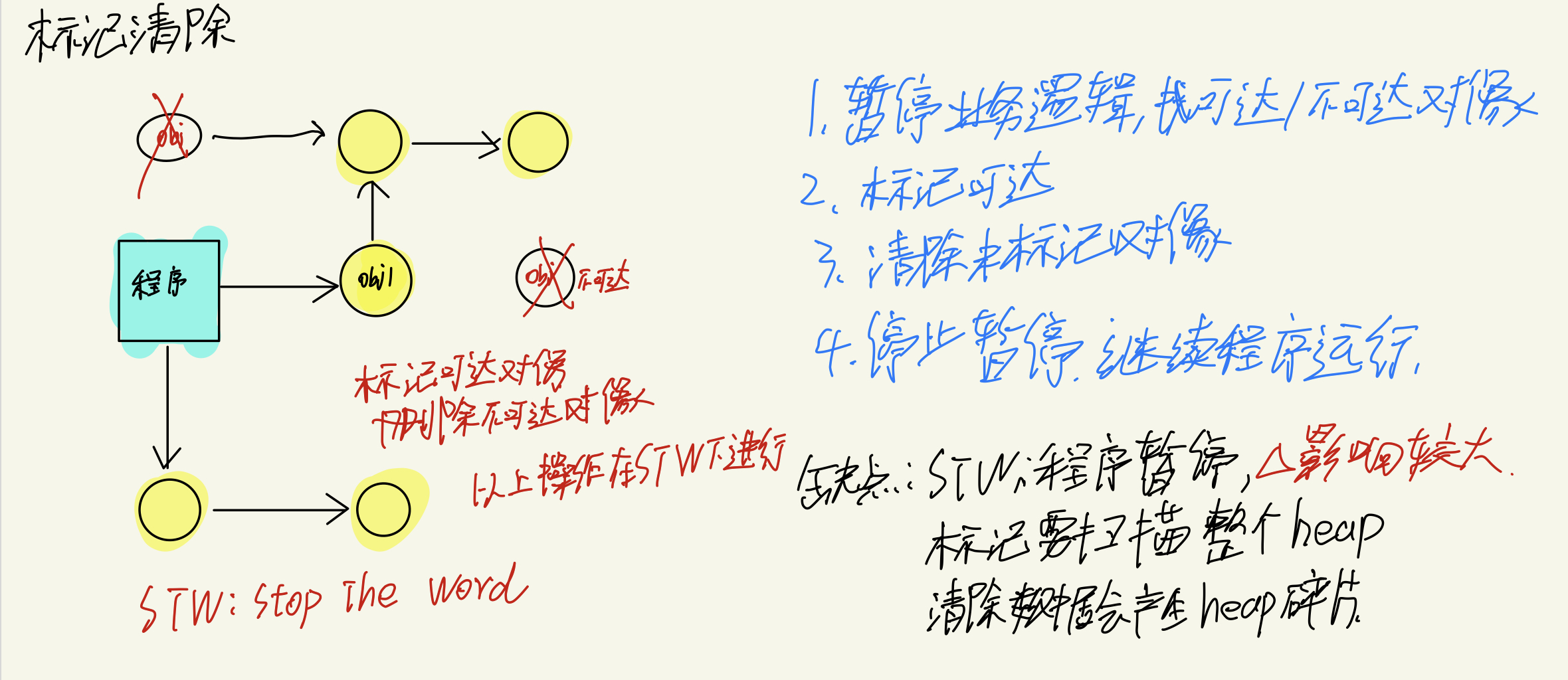
标记清除
标记:从根对象出发查找并标记堆中所有可达的存活对象
清除:遍历堆中所有对象,回收未被标记的垃圾对象并将回收的内存加入空闲链表
三色标记
- 将所有对象标记为白色
- 遍历根目录,把第一个白色节点标记为灰色
- 遍历灰色节点,将可达的对象从白色变为灰色,遍历之后的灰色,标记为黑色,重复直到没有灰色对象。
- 收集所有白色对象
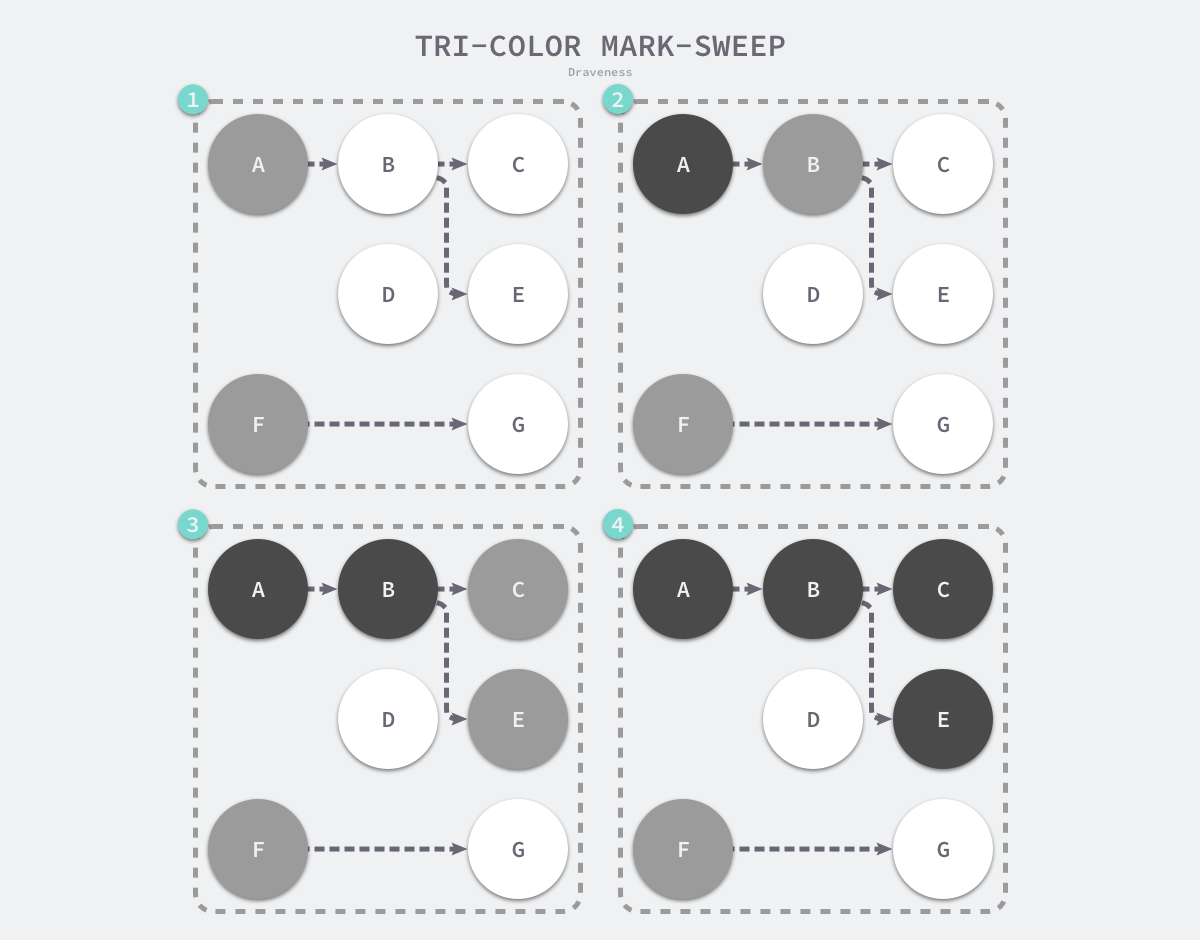
三色标记结束后的堆,只有黑色的存活对象和白色的垃圾对象。
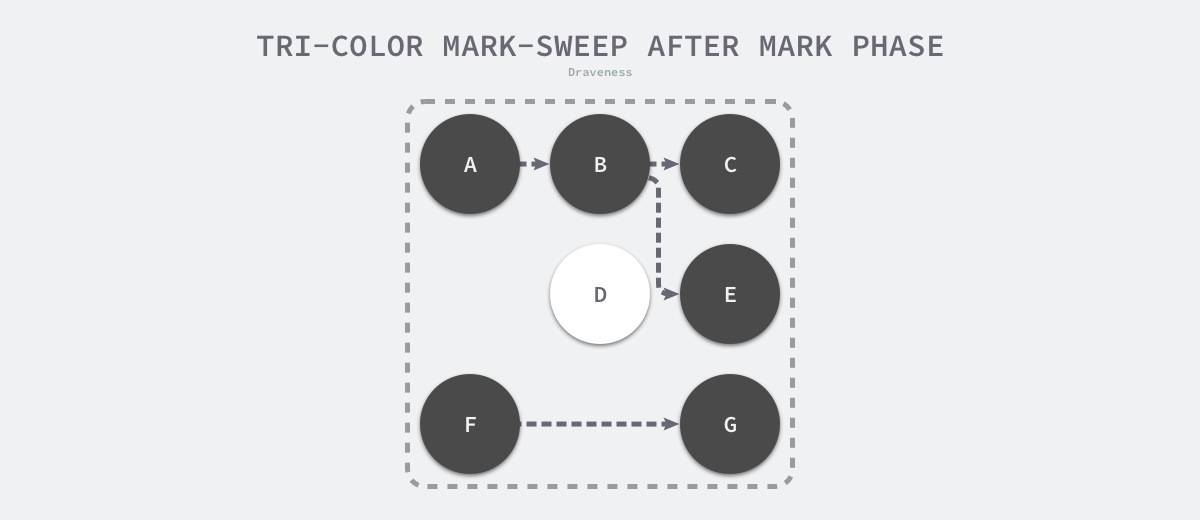
但是三色标记清除算法还是需要STW的,比如在三色标记执行时
-
如果一个白色对象被挂在黑色对象下。(条件1)
-
这个白色对象的上游灰色对象,同时丢失了指向白色对象的指向。(条件2)
-
这个时候白色对象被黑色对象指向,但是因为缺失了灰色对象的指向,所以不会在被标记为灰色
-
回收时就可能造成对象的丢失。

本来不应该被回收的对象却被回收了,这就是悬挂指针。为了尽量减少STW于是引入了屏障技术。
屏障
内存屏障技术是一种屏障指令,它可以让 CPU 或者编译器在执行内存相关操作时遵循特定的约束。
为了保证三色标记算法的正确性,需要达成两种三色不变性:
- 强三色不变性:不允许黑色对象直接指向白色对象。(破坏条件1)
- 弱三色不变性:黑色对象可以指向白色对象,但是该白色对象的上游链路必须存在灰色对象。(破坏条件2)
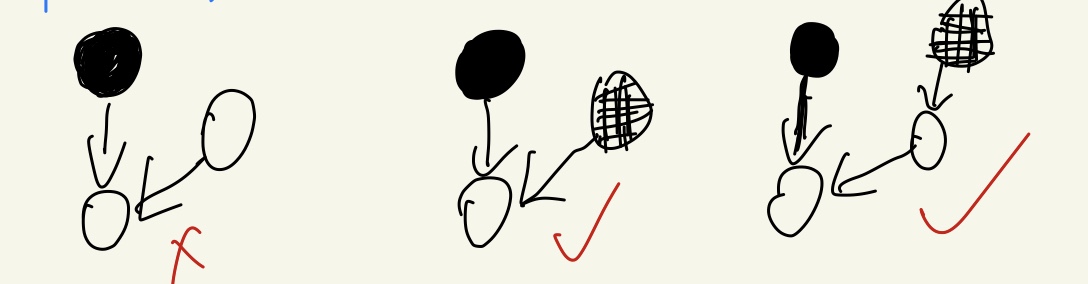
上图分别展示了遵循强三色不变性和弱三色不变性的堆内存,遵循上述两个不变性中的任意一个,我们都能保证垃圾收集算法的正确性,而屏障技术就是在并发或者增量标记过程中保证三色不变性的重要技术。
屏障分为读屏障和写屏障,因为读屏障需要在读操作加入代码片段,对用户程序的性能影响很大,所以大多数是使用写屏障保证三色不变色
写屏障
- 插入写屏障:对象被引用时触发,在A对象引用B对象时,B对象会被标记为灰色(满足强三色不变性)
- 缺点:因为栈上的对象在垃圾收集中也会被认为是根对象,所以为了保证内存的安全,写屏障必须为栈上的对象增加写屏障或者在标记阶段完成重新对栈上的对象进行扫描,这两种方法各有各的缺点,前者会大幅度增加写入指针的额外开销,后者重新扫描栈对象时需要暂停程序
- 删除写屏障:引用被删除时触发,在老对象的引用被删除时,将白色的老对象涂成灰色.(满足弱三色不变性)
- 缺点:回收精度低。
混合写屏障
Go 语言在 v1.8 组合 插入写屏障 和 删除写屏障 构成了如下所示的混合写屏障,该写屏障会将被覆盖的对象标记成灰色并在当前栈没有扫描时将新对象也标记成灰色,在垃圾收集的标记阶段,我们还需要将创建的所有新对象都标记成黑色,防止新分配的栈内存和堆内存中的对象被错误地回收,因为栈内存在标记阶段最终都会变为黑色,所以不再需要重新扫描栈空间。
具体操作:
- GC开始将栈上的对象全部扫描标记为黑色
- GC期间,任何在栈上创建的新对象,均为黑色
- 被删除的对象标记为灰色
- 被添加的对象标记为灰色
垃圾收集的多个阶段:
- 清理终止阶段;
- 暂停程序,所有的处理器在这时会进入安全点(Safe point);
- 如果当前垃圾收集循环是强制触发的,我们还需要处理还未被清理的内存管理单元;
- 标记阶段;
- 将状态切换至
_GCmark、开启写屏障、用户程序协助(Mutator Assists)并将根对象入队; - 恢复执行程序,标记进程和用于协助的用户程序会开始并发标记内存中的对象,写屏障会将被覆盖的指针和新指针都标记成灰色,而所有新创建的对象都会被直接标记成黑色;
- 开始扫描根对象,包括所有 Goroutine 的栈、全局对象以及不在堆中的运行时数据结构,扫描 Goroutine 栈期间会暂停当前处理器;
- 依次处理灰色队列中的对象,将对象标记成黑色并将它们指向的对象标记成灰色;
- 使用分布式的终止算法检查剩余的工作,发现标记阶段完成后进入标记终止阶段;
- 将状态切换至
- 标记终止阶段;
- 暂停程序、将状态切换至
_GCmarktermination并关闭辅助标记的用户程序; - 清理处理器上的线程缓存;
- 暂停程序、将状态切换至
- 清理阶段;
- 将状态切换至
_GCoff开始清理阶段,初始化清理状态并关闭写屏障; - 恢复用户程序,所有新创建的对象会标记成白色;
- 后台并发清理所有的内存管理单元,当 Goroutine 申请新的内存管理单元时就会触发清理;
- 将状态切换至
触发时间
- 后台运行定时检查和垃圾收集(2分钟)
- 用户程序手动触发垃圾收集
- 调用时会阻塞调用方直到当前垃圾收集循环完成,在垃圾收集期间也可能会通过 STW 暂停整个程序
- 申请内存时根据堆大小触发垃圾收集
- 微、小、大三类对象创建都有可能触发新的垃圾收集循环
- 当前线程的内存管理单元中不存在空闲空间时,创建微对象和小对象需要调用
runtime.mcache.nextFree从中心缓存或者页堆中获取新的管理单元,在这时就可能触发垃圾收集; - 当用户程序申请分配 32KB 以上的大对象时,一定会构建
runtime.gcTrigger结构体尝试触发垃圾收集;
- 当前线程的内存管理单元中不存在空闲空间时,创建微对象和小对象需要调用
- 微、小、大三类对象创建都有可能触发新的垃圾收集循环
context
上下文 context.Context Golang 中用来设置截止日期,同步信号,传递请求相关值的结构体
type Context interface {
// 返回context被取消的时间,也就是完成工作的截止时间
Deadline() (deadline time.Time, ok bool)
// 返回一个Channel,这个Channel会在当前工作完成或者上下文被取消后关闭,多次调用返回同一个Channel
Done() <-chan struct{}
// 返回context结束的原因,只会在Done方法对应的Channel关闭时返回非空的值
// 1. 如果context被取消 返回 Canceled 错误
// 2. 如果context超时,返回 DeadlineExceeded错误
Err() error
// 从context中获取键对应的值
Value(key interface{}) interface{}
}
如果上层 goroutine 因为某种原因执行失败时,下层 goroutine 由于没有接收到这个信号,会继续工作。使用 context 就可以在下层及时停掉无用的工作以减少额外资源的消耗
一些方法
context.Backgroud 上下文默认值,所有上下文都应该由他衍生出来。context.TODO 与Backgroud 差不多,仅在不确定用那种上下文时使用
context.WithCancel 能够从 context 中衍生出一个新的子上下文并返回用于取消该上下文的函数,一旦我们执行返回的取消函数,当前上下文和他的子上下文都会被取消,所有 Goroutine 都会收到该信号。
context.WithDeadline 传入截止时间
context.WithTimeout 传入 duration,WithTimeout 内部就是直接调用WithDeadline
other
依赖管理历史
Q:go的执行顺序
A:
- 按顺序导入所有被main包引用的其他包,然后再每个包中执行如下②③④流程。
- 如果该包又导入了其他包,则从第一步开始递归执行,但是每一个包只会被导入一次。
- 然后以相反的顺序在每个包中初始化常量和变量,如果该包含有init函数的话,则调用该函数。
- 在完成这一切之后,main也执行同样的过程,最后调用main函数开始执行程序。
什么是面向对象
go 是如何实现继承的
