最优化-梯度下降算法-前向传播-反向传播
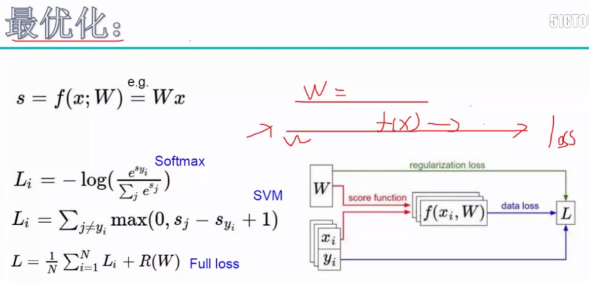
一、前向传播:通过一组w参数得到一组得分值f(x),再做e^x再归一化,再到Loss值。
Bachsize是一次取2的整数倍数(32,64,128)张图片做一次迭代
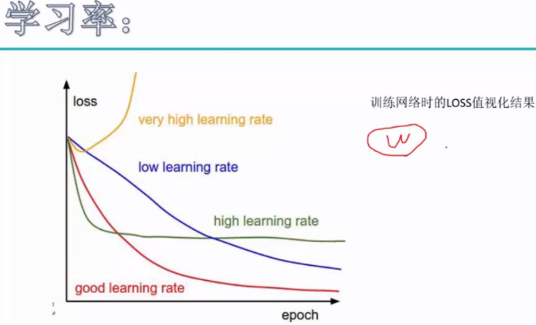
学习率:过大会来回震荡,找不到最小值;太小,迭代次数过大,效率低。
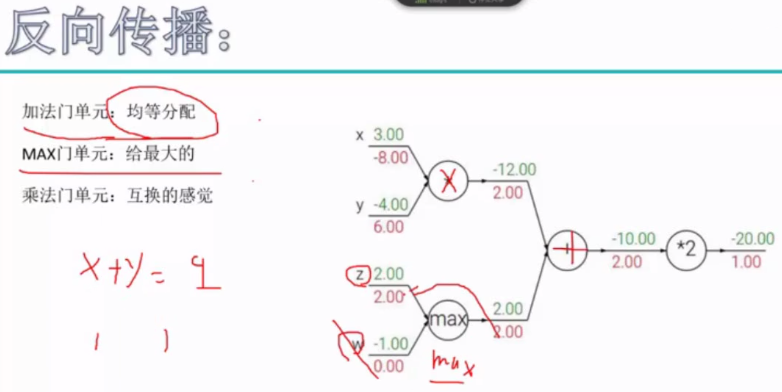
二、反向传播
由Loss值一步一步往回传,更新权重参数。
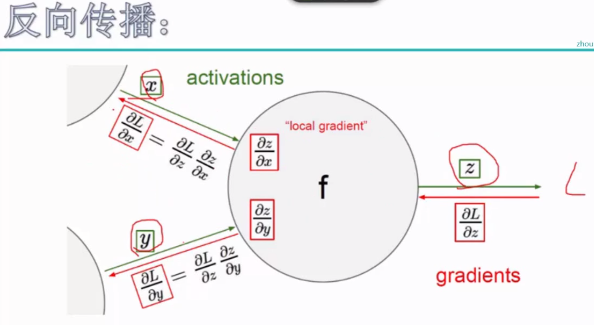
先算z对L的贡献,一步一步地向前求偏导。
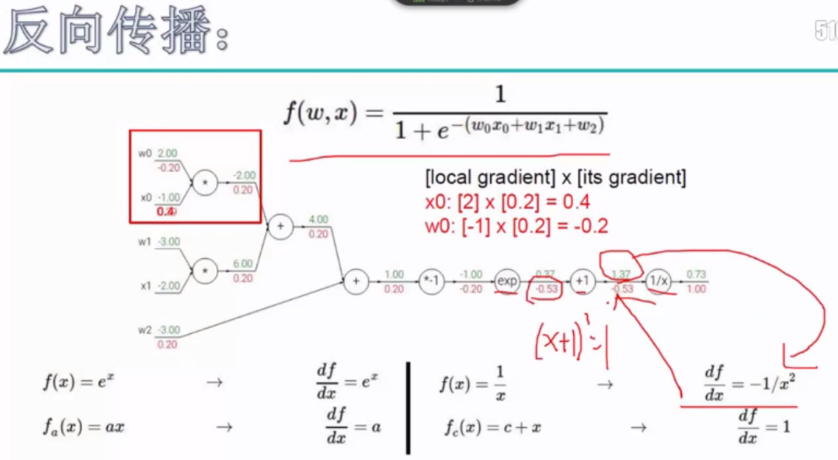

三种门单元:
一、前向传播:通过一组w参数得到一组得分值f(x),再做e^x再归一化,再到Loss值。
Bachsize是一次取2的整数倍数(32,64,128)张图片做一次迭代
学习率:过大会来回震荡,找不到最小值;太小,迭代次数过大,效率低。
二、反向传播
由Loss值一步一步往回传,更新权重参数。
先算z对L的贡献,一步一步地向前求偏导。
三种门单元:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号