http1.1保持keepalive
想要保活http的keepalive就需要在keepalive的时间内发http,tcp的keepalive可能会小于http的keepalive,但是在http的keepalive时间内tcp都是存活的。
在keepalive心跳内是通讯状态(ESTAB)
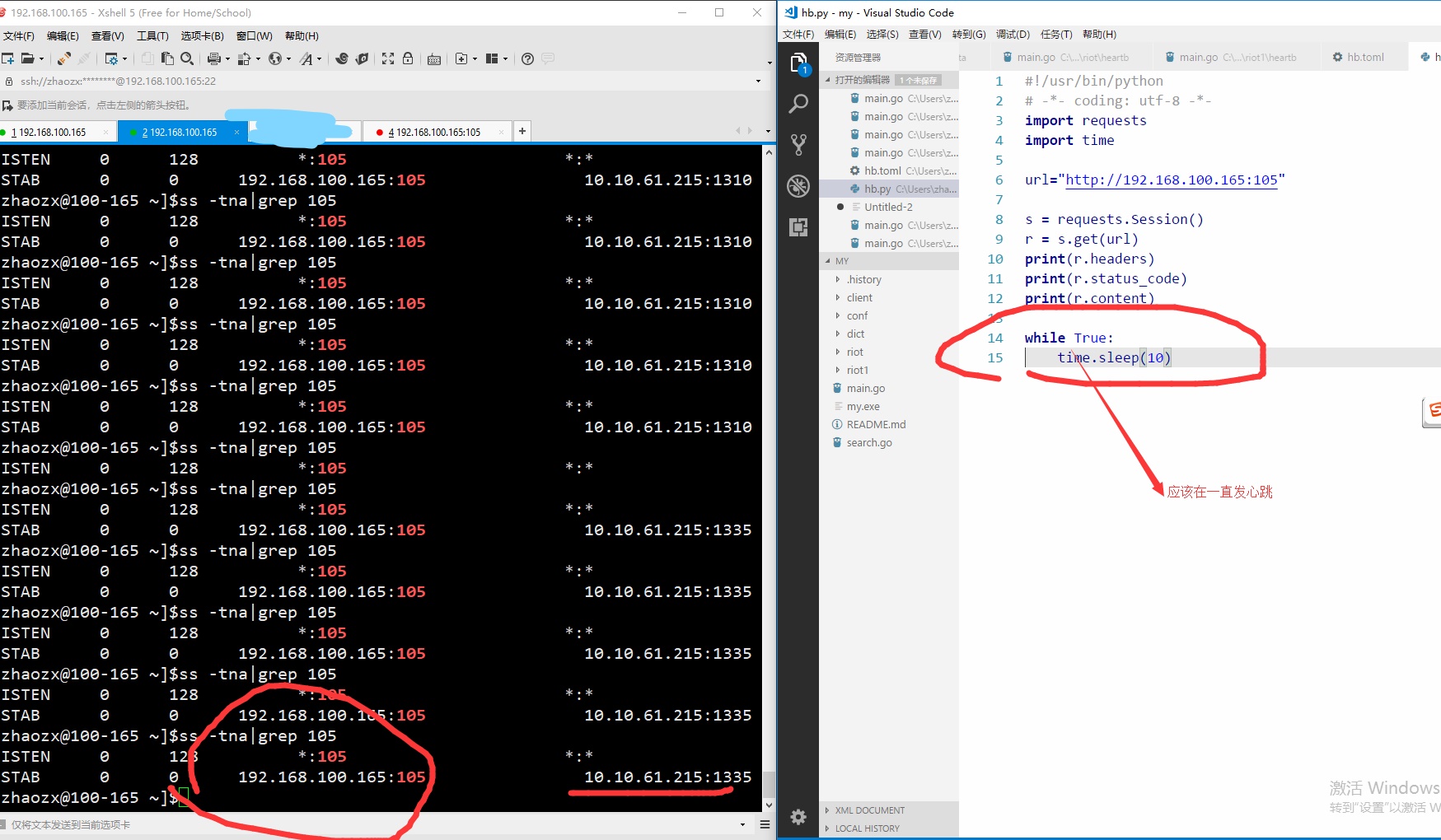
在keepalive心跳外是服务器想要关闭状态(FIN-WAIT-2)
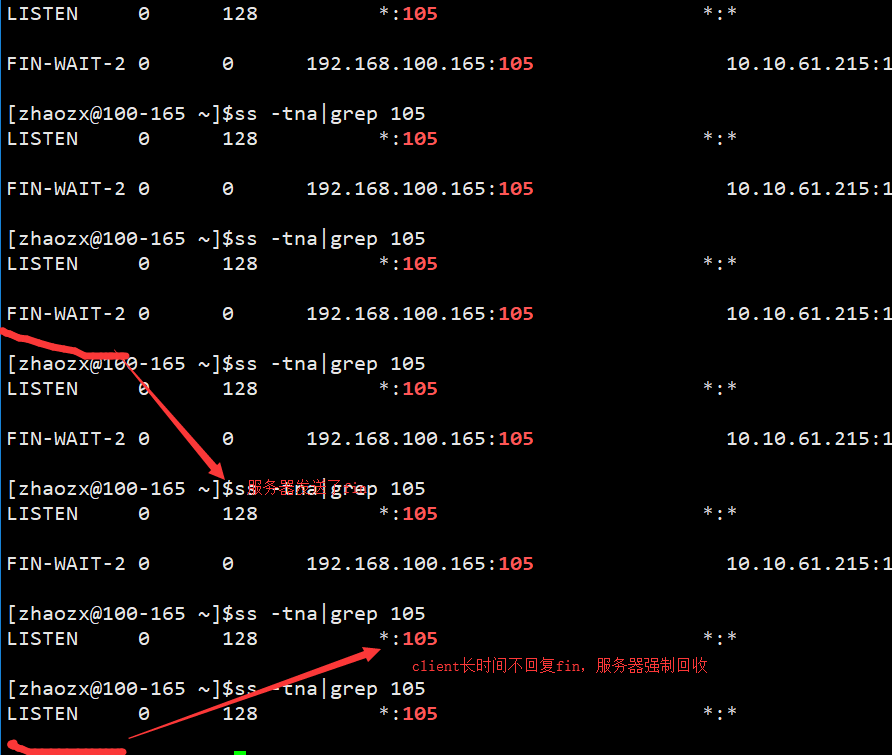
FIN_WAIT_2状态:服务端关闭,但客户端没有关闭。
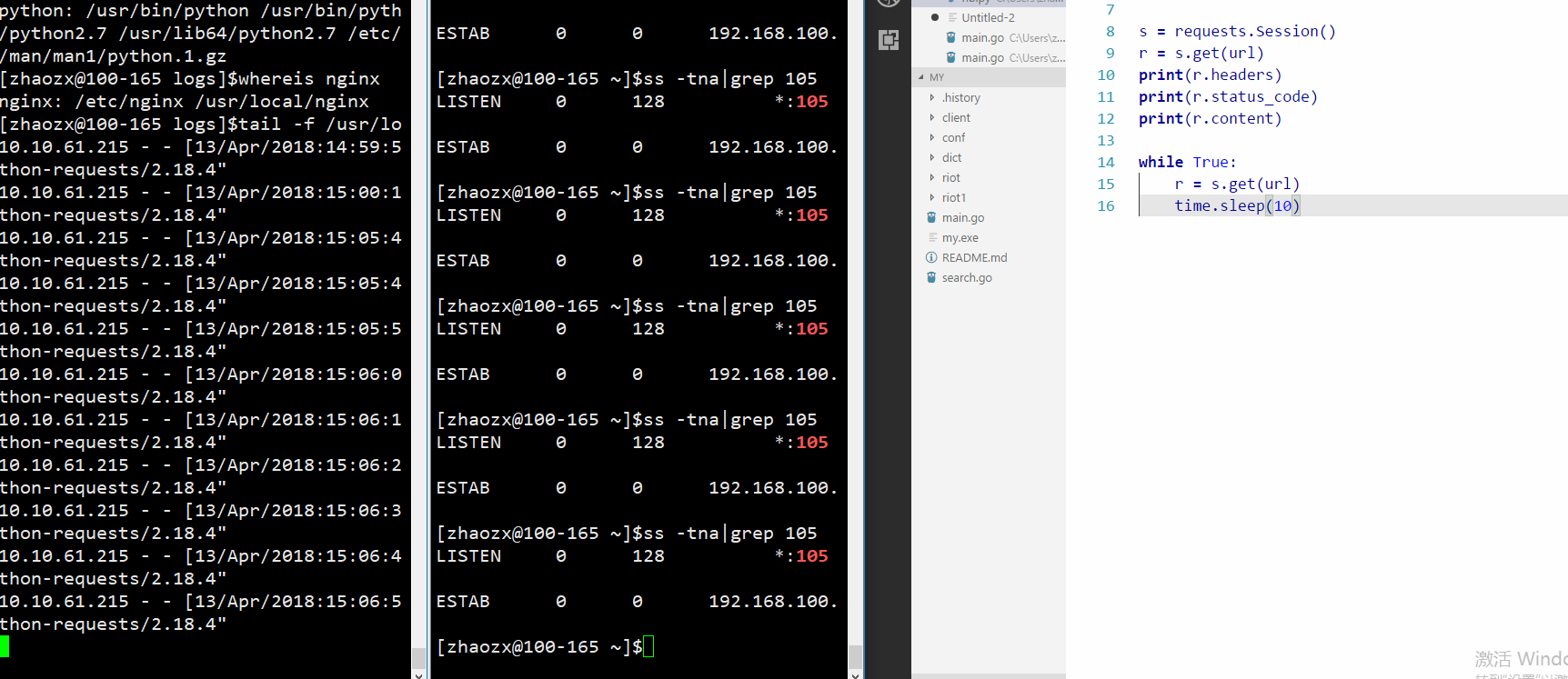
从下面的图片中可以看到python的request库的确可以复用http1.1的conncetion
下面的这个地方应该是chrome为了加快网络资源加载同时使用多个session(上限好像是4)来加载资源,它没有做资源的个数的处理即在资源多余1的时候才使用多个session。
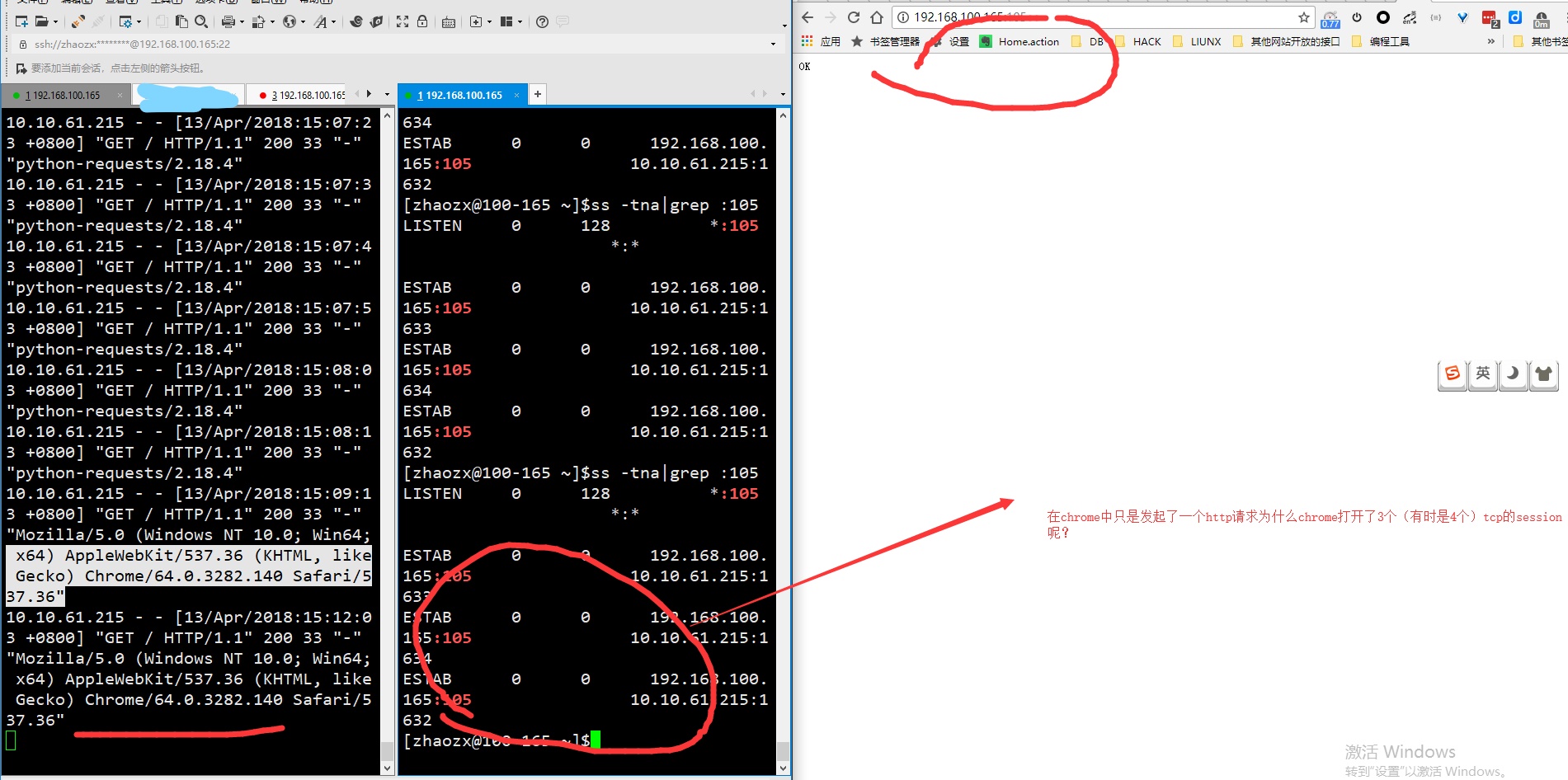
从下面的代码来看,最多是可能有6个session的(我自己测试的结果是最多只有6个session)。可能也做了一些处理。
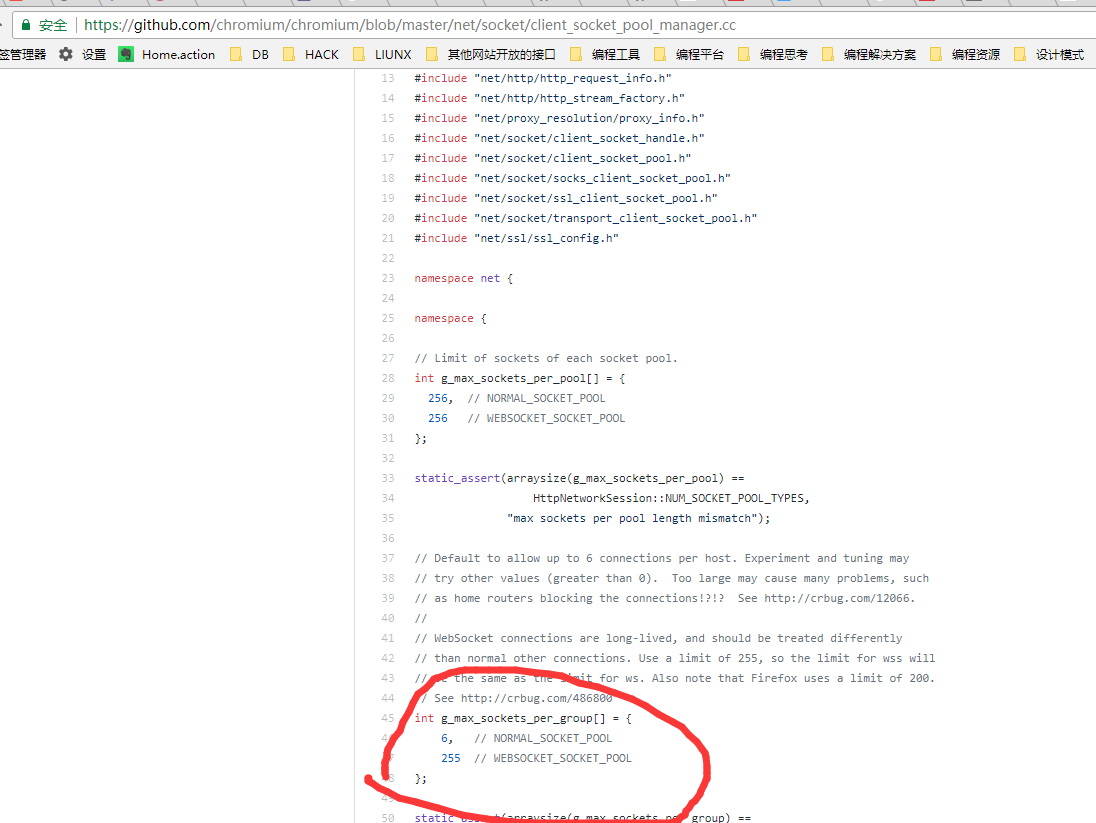
总结:
HTTP1.1 over TCP的一些分析。
关联场景:网页上的抢购(over HTTP)。
防止抢购建议:抢购的IP与页面的IP分开,抢购的IP的防火墙在目标时间段外禁止connection。在抢购的IP上关闭keepalive是消耗资源的操作,不建议关闭keepalive。
抢购建立:抢购开始前保活session,while的时间可能是tcp的keepalive时间(需要确认)。
下面是wireshare的抓包分析:
浏览器上分析:
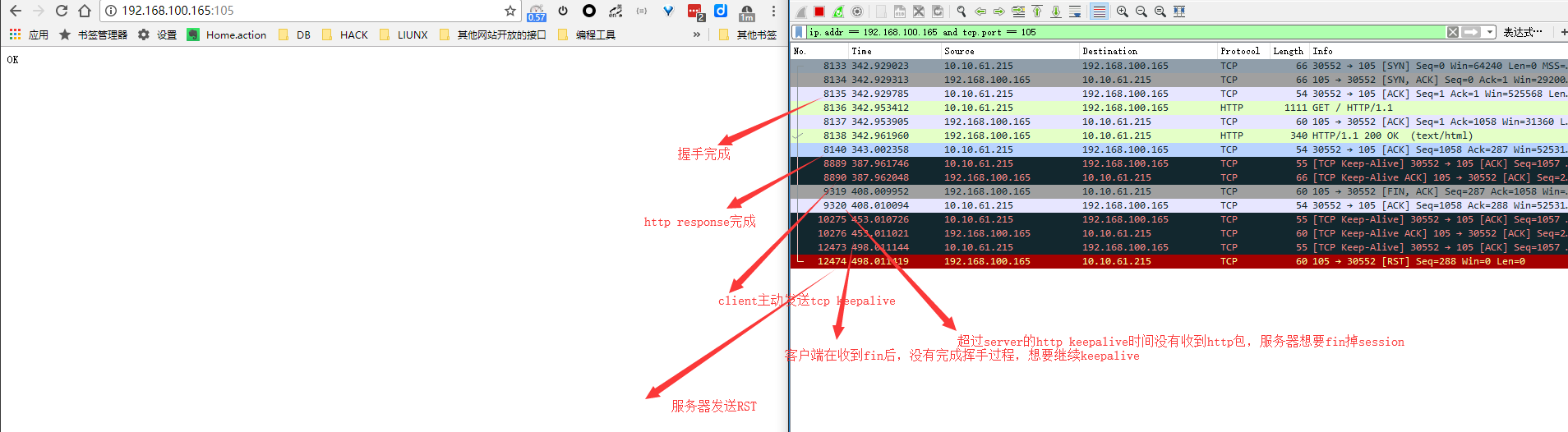
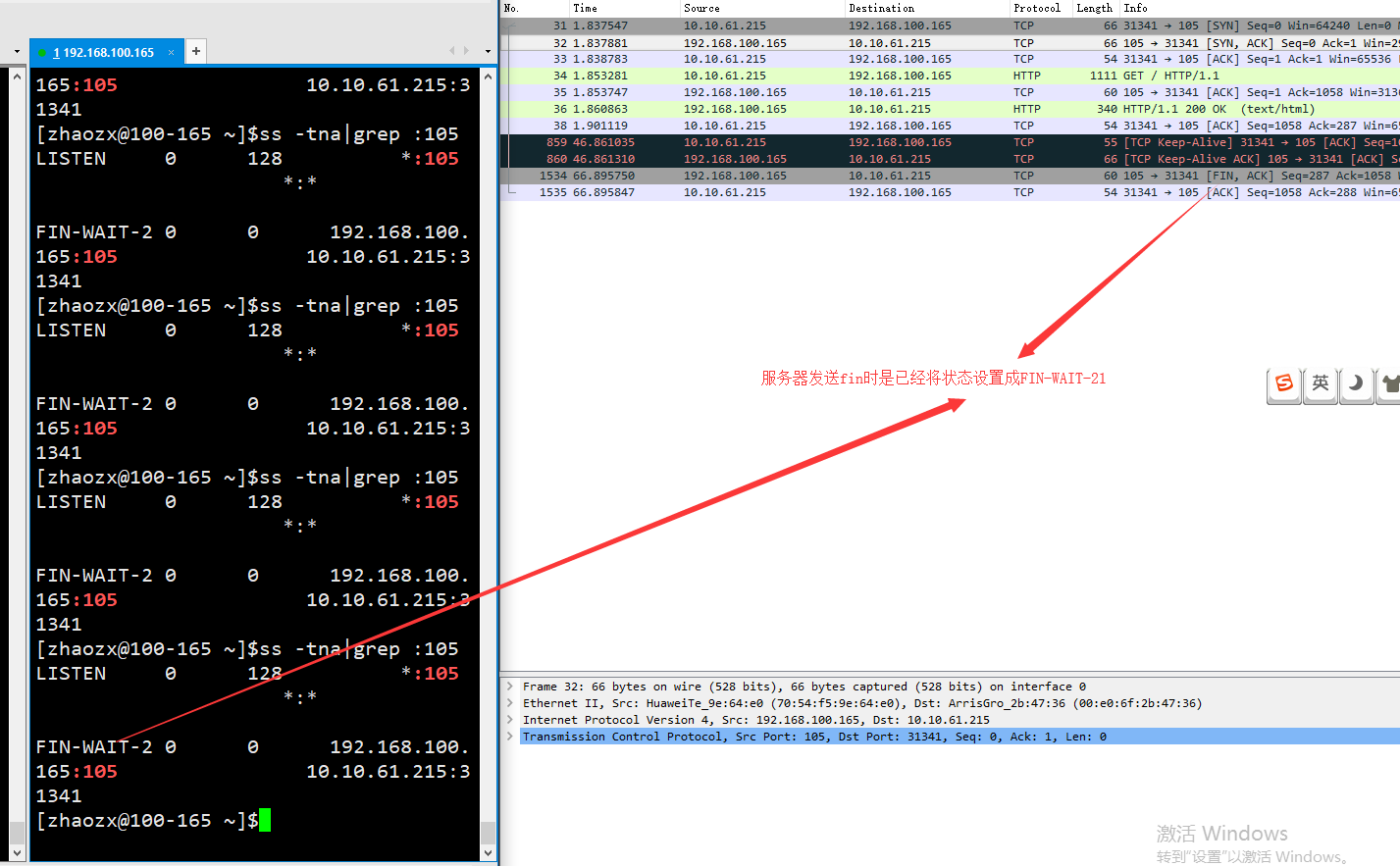
服务器发送FIN之后就等待client发送fin,但是client发送的是keepalive,这导致没有完成挥手。服务器在处于FIN-WAIT-2状态一段时间后直接关闭了session。此时client无论发送什么包给server,server的回复都是RST。
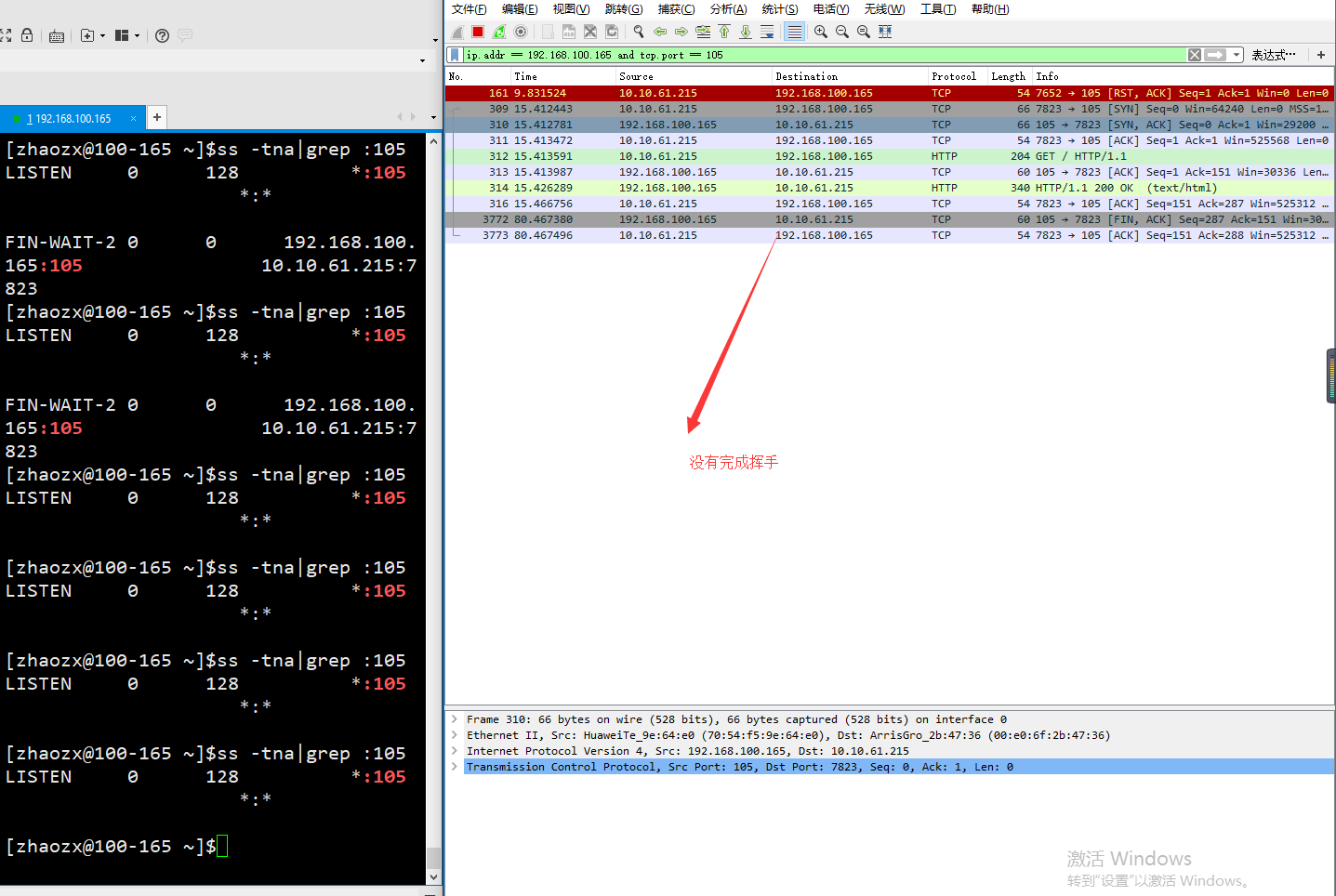
requests的抓包分析,可以看到requests没有发送tcp的keepalive心跳:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号