编程作业
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 编程作业 |
| 学号 | 20188540 |
1、作业描述和目录
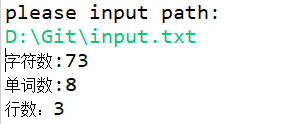
1、统计文件的字符数(对应输出第一行):
只需要统计Ascii码,汉字不需考虑
空格,水平制表符,换行符,均算字符
2、统计文件的单词总数(对应输出第二行),单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
英文字母: A-Z,a-z
字母数字符号:A-Z, a-z,0-9
分割符:空格,非字母数字符号
例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
3、统计文件的有效行数(对应输出第三行):任何包含非空白字符的行,都需要统计。
4、统计文件中各单词的出现次数(对应输出接下来10行),最终只输出频率最高的10个。
频率相同的单词,优先输出字典序靠前的单词。
例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
输出的单词统一为小写格式
然后将统计结果输出到output.txt,输出的格式如下;其中word1和word2 对应具体的单词,number为统计出的个数;换行使用'\n',编码统一使用UTF-8。
项目链接
Gitee-Java
2、psp表
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 180 | 240 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 120 | 180 |
| • Design Spec | • 生成设计文档 | 15 | 20 |
| • Design Review | • 设计复审 | 15 | 10 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 25 | 45 |
| • Design | • 具体设计 | 45 | 30 |
| • Coding | • 具体编码 | 180 | 200 |
| • Code Review | • 代码复审 | 20 | 20 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 15 | 25 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 15 | 26 |
| • Size Measurement | • 计算工作量 | 300 | 350 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 740 | 936 |
3、解题思路
(1),读取文件,利用Java I/O读入文件中的内容 bufferedreader类将数据放到缓冲区内进行操作,
(2)bufferedreader中的readline()方法是按照逐行读取同时进行累加最后输出行数
(3)用split()方法进行单词切割存放在数组中,并获取数组长度,将其中所有的单词利用toLowerCase()方法全部变成小写,判断是否视其为单词,如果视为不是单词,获取的数组长度减一,循环下去知道所有的单词都满足要求,然后输出个数
(4)取(3)中的数组遍历,判断是否为重复,统计单词频率,循环下去,最后利用filewriter写出到output.txt
4、代码规范
codestyle
5、计算机模块接口的设计与实现
int length = item.length;// 得到item的长度
FileInputStream fis = null;
try {
fis = new FileInputStream(file_path);
while ((bytes = fis.read(item, 0, length)) != -1) {
countChar += bytes;
}
定义 countChar来存储字节数,用缓冲区中的数据fileinputstream通过while循环来累加字节数,最后输出字节数
try {
fis = new FileInputStream(file_path);
isr = new InputStreamReader(fis);
br = new BufferedReader(isr);
while (br.readLine() != null) {
countLine++;
}
bufferedreader中的readline()方法是按照逐行读取同时进行累加最后输出行数
temp = temp.toLowerCase();
String[] total = temp.split(" ");// 将temp中的单词用“ ”分开
countWords = total.length;
for (int i = 0; i < total.length; i++) {
String s = total[i].toString();
if (s.length() < 4) {// 如果字符小于4个
countWords--;
} else {
for (int j = 0; j < 4; j++) {// 如果字符数大于4但是前面为数字
char c = s.charAt(j);
if (!(c >= 'a' && c <= 'z')) {
countWords--;
break;
}
}
}
}
用split()方法进行单词切割存放在数组中,并获取数组长度,将其中所有的单词利用toLowerCase()方法全部变成小写,判断是否视其为单词,如果视为不是单词,获取的数组长度减一,循环下去知道所有的单词都满足要求,然后输出个数
fis = new FileInputStream(file_path);
isr = new InputStreamReader(fis);// 文件字节输入流
br = new BufferedReader(isr);// 文件缓存输入流
while (br.read() != -1) {
temp = br.readLine();
sb.append(temp);// 将读出来的数据保存在temp中
sb.append(" ");// 添加一个空格
}
Map<String, Integer> map = new HashMap<String, Integer>();// 运用哈希排序
temp = sb.toString();
temp = temp.replaceAll("[^A-Za-z0-9]", " ");
temp = temp.toLowerCase();
StringTokenizer st = new StringTokenizer(temp, " ");// 分割字符串
while (st.hasMoreTokens()) {
String letter = st.nextToken();// 把分割好的字符串保存到letter中
int count;
if (map.get(letter) == null) {
count = 1;// 表示没有分割
} else {
count = map.get(letter).intValue() + 1;
}
map.put(letter, count);
}
Set<MySetUtil> set = new TreeSet<MySetUtil>();
for (String key : map.keySet()) {
set.add(new MySetUtil(key, map.get(key)));
}
int count = 1;
for (Iterator<MySetUtil> it = set.iterator(); it.hasNext();) {
MySetUtil msu = it.next();
boolean isWords = true;
if (msu.getKey().length() > 4) {
String s = msu.getKey();
for (int i = 0; i < 4; i++) {
char c = s.charAt(i);
if (!(c >= 'a' && c <= 'z'))// 只要是字母都已经换成小写了
{
isWords = false;
break;
}
if (isWords == true) {
result += msu.getKey() + ": " + msu.getCount() + "\n";
if (count == 10) {
break;
}
count++;
}
}
}
}
取(3)中的数组遍历,判断是否为重复,统计单词频率,循环下去,最后利用filewriter写出到output.txt
6、单元测试和性能分析

7、异常处理
1、输出时数据重复


 浙公网安备 33010602011771号
浙公网安备 33010602011771号