Python内存管理机制
一、变量与对象
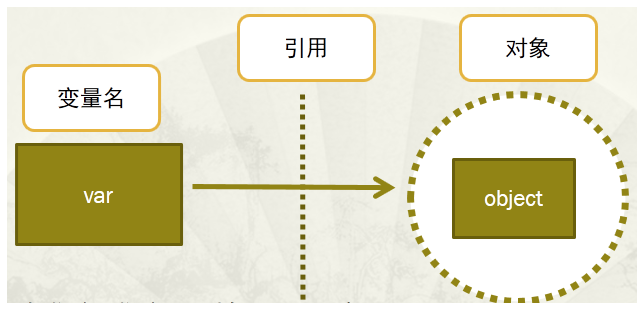
关系图如下:
-
1、变量,通过变量指针引用对象
- 变量指针指向具体对象的内存空间,取对象的值。
-
2、对象,类型已知,每个对象都包含一个头部信息(头部信息:类型标识符和引用计数器)
注意
-
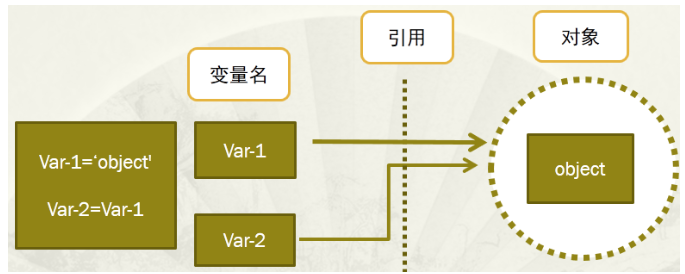
变量名没有类型,类型属于对象(因为变量引用对象,所以类型随对象),变量引用什么类型的对象,变量就是什么类型的。
In [32]: var1="洲神" In [33]: var2=var1 In [34]: id(var1) Out[34]: 139697863383968 In [35]: id(var2) Out[35]: 139697863383968 -
PS:id()是python的内置函数,用于返回对象的身份,即对象的内存地址。
In [39]: a=123
In [40]: b=a
In [41]: id(a)
Out[41]: 23242832
In [42]: id(b)
Out[42]: 23242832
In [43]: a=456 #a的引用指向别的对象,重新赋值,a变量覆盖了上面的a变量,所以a的内存地址发生改变
In [44]: id(a)
Out[44]: 33166408
In [45]: id(b)
Out[45]: 23242832
-
3、引用所指判断
通过is进行引用所指判断,is是用来判断两个引用所指的对象是否相同。
is判断的就是内存地址是否相同,而等于只是判断等号量两边的值是否相同
整数
In [46]: a=1
In [47]: b=1
In [48]: print(a is b)
True
字符串
In [49]: c="good"
In [50]: d="good"
In [51]: print(c is d)
True
列表(不可变数据类型)
In [55]: g=[]
In [56]: h=[]
In [57]: print(g is h)
False
字典
dic ={1:1}
dd={1:1}
dic is dd
False
由运行结果可知:
1、Python只缓存了整数和字符串(小数据池,代码块机制,请看我博客,小数据池那章),因此每个对象在内存中只存有一份,引用所指对象就是相同的,即使使用赋值语句,也只是创造新的引用,而不是对象本身;
2、Python没有缓存列表,字典及其他对象,可以由多个相同的对象,可以使用赋值语句创建出新的对象。
二、引用计数
-
在Python中,每个对象都有指向该对象的引用总数---引用计数
查看对象的引用计数:sys.getrefcount()
1、普通引用
In [2]: import sys
In [3]: a=[1,2,3]
In [4]: getrefcount(a)
Out[4]: 2
In [5]: b=a
In [6]: getrefcount(a)
Out[6]: 3
In [7]: getrefcount(b)
Out[7]: 3
注意:
当使用某个引用作为参数,传递给getrefcount()时,参数实际上创建了一个临时的引用。因此,getrefcount()所得到的结果,会比期望的多1。
2、容器对象
Python的一个容器对象(比如:表、词典等),可以包含多个对象。
In [12]: a=[1,2,3,4,5]
In [13]: b=a
In [14]: a is b
Out[14]: True
In [15]: a[0]=6
In [16]: a
Out[16]: [6, 2, 3, 4, 5]
In [17]: a is b
Out[17]: True
In [18]: b
Out[18]: [6, 2, 3, 4, 5]
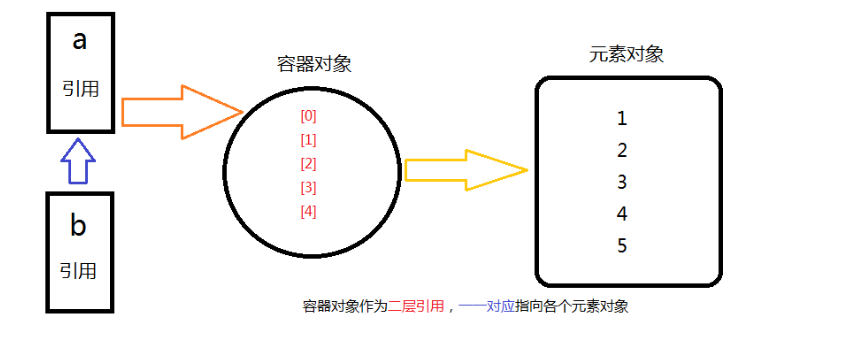
由上可见,实际上,容器对象中包含的并不是元素对象本身,是指向各个元素对象的引用。
3、引用计数增加
- 1、对象被创建
In [39]: getrefcount(123)
Out[39]: 6
In [40]: n=123
In [41]: getrefcount(123)
Out[41]: 7
- 2、另外的别人被创建
In [42]: m=n
In [43]: getrefcount(123)
Out[43]: 8
- 3、作为容器对象的一个元素
In [44]: a=[1,12,123]
In [45]: getrefcount(123)
Out[45]: 9
- 4、被作为参数传递给函数:foo(x)
4、引用计数减少
1、对象的别名被显式的销毁
In [46]: del m
In [47]: getrefcount(123)
Out[47]: 8
2、对象的一个别名被赋值给其他对象
In [48]: n=456
In [49]: getrefcount(123)
Out[49]: 7
3、对象从一个窗口对象中移除,或,窗口对象本身被销毁
In [50]: a.remove(123)
In [51]: a
Out[51]: [1, 12]
In [52]: getrefcount(123)
Out[52]: 6
4、一个本地引用离开了它的作用域,比如上面的foo(x)函数结束时,x指向的对象引用减1。
三、垃圾回收
当Python中的对象越来越多,占据越来越大的内存,启动垃圾回收(garbage collection),将没用的对象清除。
1、原理
当Python的某个对象的引用计数降为0时,说明没有任何引用指向该对象,该对象就成为要被回收的垃圾。比如某个新建对象,被分配给某个引用,对象的引用计数变为1。如果引用被删除,对象的引用计数为0,那么该对象就可以被垃圾回收。
In [74]: a=[321,123]
In [75]: del a
2、解析del
del a后,已经没有任何引用指向之前建立的[321,123],该表引用计数变为0,用户不可能通过任何方式接触或者动用这个对象,当垃圾回收启动时,Python扫描到这个引用计数为0的对象,就将它所占据的内存清空。
3、注意
1、垃圾回收时,Python不能进行其它的任务,频繁的垃圾回收将大大降低Python的工作效率;
2、Python只会在特定条件下,自动启动垃圾回收(垃圾对象少就没必要回收)
3、当Python运行时,会记录其中分配对象(object allocation)和取消分配对象(object deallocation)的次数。当两者的差值高于某个阈值时,垃圾回收才会启动。
In [93]: import gc
In [94]: gc.get_threshold() #gc模块中查看阈值的方法
Out[94]: (700, 10, 10)
阈值分析:
700即是垃圾回收启动的阈值;
每10次0代垃圾回收,会配合1次1代的垃圾回收;而每10次1代的垃圾回收,才会有1次的2代垃圾回收;
当然也是可以手动启动垃圾回收:
In [95]: gc.collect() #手动启动垃圾回收
Out[95]: 2
4、何为分代回收
Python将所有的对象分为0,1,2三代;
所有的新建对象都是0代对象;
当某一代对象经历过垃圾回收,依然存活,就被归入下一代对象。
四、内存池机制
Python中有分为大内存和小内存:(256K为界限分大小内存)
1、大内存使用malloc进行分配
2、小内存使用内存池进行分配
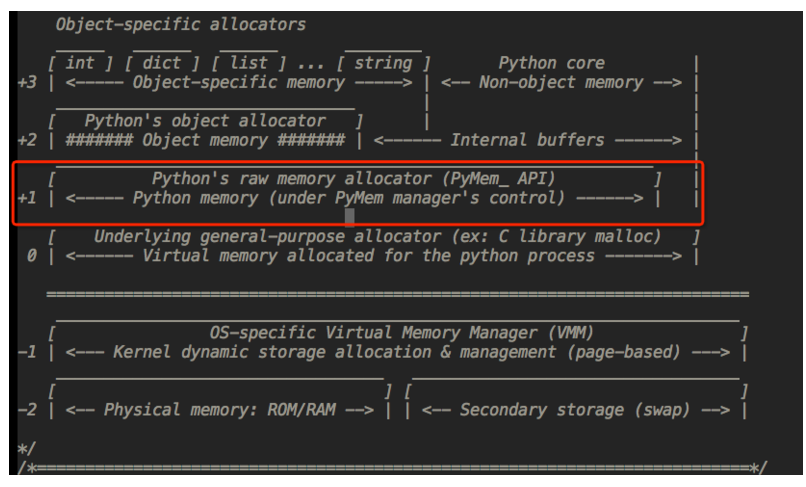
3、Python的内存池(金字塔)
第3层:最上层,用户对Python对象的直接操作
第1层和第2层:内存池,有Python的接口函数PyMem_Malloc实现-----若请求分配的内存在1~256字节之间就使用内存池管理系统进行分配,使用pymalloc实现的分配器进行分配内存,但是每次只会分配一块大小为256K的大块内存,不会调用free函数释放内存,将该内存块留在内存池中以便下次使用。
第0层:大内存-----若请求分配的内存大于256K,则使用系统的 malloc函数分配内存,free函数释放内存。
第-1,-2层:操作系统进行操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号