crawlscrapy框架
crawlscrapy
-
其实他是Spider的一个子类,Spider爬虫文件中爬虫类的父类
- 子类的功能一定是多余父类的
-
作用:被用作与专业实现全站数据爬取
- 将一个页面下所有页面对应的数据进行爬取
-
基本使用:
1.创建一个工程
2.cd 工程
3.创建一个基于CrawlSpider的爬虫文件
- scrapy genspider -t crawl SpiderName www.xxx.com
4.执行工程
注意:
1.一个链接提取器对应一个规则提取器(多个链接提取器和多个规则解析器)
2.在实现深度爬取的过程中需要和scrapy.Request()结合使用
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider,Rule
class FirstSpider(CrawlSpider):
name = "first"
start_urls = ['http://www.521609.com/daxuexiaohua/']
#实例化LinkExtractor对象
#链接提取器:根据指定规则(allow参数)在页面中进行连接(url)的提取
#allow = "正则”:提取链接的规则
#link = LinkExtractor(allow=r"list3\d+\.html")
link = LinkExtractor(allow=r'') #取出网站全站的链接
#实例化一个rules对象
rules=(
#规则解析器,接受连接提取器提取的url对其进行请求!,然后根据指定规则(callback
)执行函数解析数据
Rule(link,callback="parse_item",follow=True),
)
#follow = True;
#将链接提取器 继续作用到 链接提取器提取到的页码中所对应的页面中
def parse_item(self,response):
print(response)
#后续可自行基于response实现数据解析
补充:提取的页面就是符合link中allow正则规则的url。他会自动拼接start_urls 就像那些a标签的herf属性,就像当前网页底下分页有10个a标签,他会获取a标签的网址发起请求
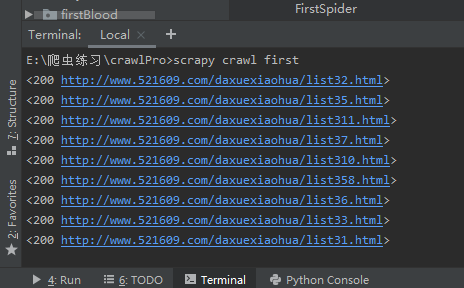
CrawlSpider深度爬取
-
通用方式:CrawlSpider+Spider实现
以下这种方法不可取,虽然可以搜索详情页,但是也只是第一页得详情页,不可取,并且存储也是个麻烦,此网站分页是动态加载的,所有导致只能搜索到2页!!
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from zhou.items import ZhouItem
class ZhoushenSpider(CrawlSpider):
name = 'zhoushen'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://wz.sun0769.com/political/index/politicsNewest?id=1&type=4&page=']
#提取页面链接
link = LinkExtractor(allow=r'id=1&page=\d+')
link_detail = LinkExtractor(allow=r'index\?id=\d+')
rules = (
Rule(link, callback='parse_item', follow=False),
Rule(link_detail,callback='parse_detail',follow=False)
)
#实现深度爬取:爬取详情页中的数据
#1.对详情页的url进行捕获
#2.对详情页的url发起请求获取数据
def parse_detail(self,response):
content = response.xpath('/html/body/div[3]/div[2]/div[2]/div[2]/pre/text()').get()
item = {}
item['content'] = content
yield item
def parse_item(self, response):
li_list = response.xpath("/html/body/div[2]/div[3]/ul[2]/li")
for i in li_list:
title = i.xpath('./span[3]/a/text()').get()
status = i.xpath('./span[2]/text()').get()
#但是实例化有实例化的好处,你在items.py中可以创建多个类来实例化,传入管道时,你可以用来判断,此item属于哪个类的,然后去进行操作,看下面的pipelines.py文件代码
# item =ZhouItem()
#以下这种写法时创建源文件人家备注,尝试了一下也可以,估计实例化items中的类也是返回的字典,所以可以这么用
item ={}
item["title"] = title.strip()
item["status"] = status.strip()
yield item
# item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
pipelines.py
实例化创建item的好处就是可以判断
class SunproPipeline(object):
def process_item(self, item, spider):
# if item.__class__.__name__ == 'SunproItem':
# title = item['title']
# status = item['status']
# print(title+':'+status)
# else:
# content = item['content']
# print(content)
print(item)
return item
但是以上深度爬取并不好,应为获取到了详情页数据但是无法跟标题绑定,因为是异步请求的
以下这种方法推荐(手动请求实现详情页的爬取)!!
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from sunPro.items import SunproItem,SunProItemDetail
class SunSpider(CrawlSpider):
name = 'sun'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://wz.sun0769.com/political/index/politicsNewest?id=1&type=4&page=']
#提取页码链接
link = LinkExtractor(allow=r'id=1&page=\d+')
# link_detail = LinkExtractor(allow=r'index\?id=\d+')
rules = (
#解析每一个页码对应页面中的数据
Rule(link, callback='parse_item', follow=False),
# Rule(link_detail,callback='parse_detail')
)
#标题&状态
# def parse_item(self, response):
# li_list = response.xpath('/html/body/div[2]/div[3]/ul[2]/li')
# for li in li_list:
# title = li.xpath('./span[3]/a/text()').extract_first()
# status = li.xpath('./span[2]/text()').extract_first()
# item = SunproItem()
# item['title'] = title
# item['status'] = status
#
# yield item
#
# #实现深度爬取:爬取详情页中的数据
# #1.对详情页的url进行捕获
# #2.对详情页的url发起请求获取数据
#
# def parse_detail(self,response):
# content = response.xpath('/html/body/div[3]/div[2]/div[2]/div[2]/pre/text()').extract_first()
# item = SunProItemDetail()
# item['content'] = content
# yield item
#问题:
#1.爬虫文件会向管道中提交两个不同形式的item,管道会接收到两个不同形式的item
#2.管道如何区分两种不同形式的item
#-在管道中判断接收到的item到底是哪个
#3.持久化存储的,目前无法将title和content进行一一匹配
def parse_item(self, response):
li_list = response.xpath('/html/body/div[2]/div[3]/ul[2]/li')
for li in li_list:
title = li.xpath('./span[3]/a/text()').extract_first()
status = li.xpath('./span[2]/text()').extract_first()
detail_url = 'http://wz.sun0769.com'+li.xpath('./span[3]/a/@href').extract_first()
item = SunproItem()
item['title'] = title
item['status'] = status
yield scrapy.Request(url=detail_url,callback=self.parse_detail,meta={'item':item})
def parse_detail(self,response):
content = response.xpath('/html/body/div[3]/div[2]/div[2]/div[2]/pre/text()').extract_first()
item = response.meta['item']
item['content'] = content
yield item
selenium在scrapy中的使用(针对详情页的动态加载)
-
爬取网易新闻中的国内,国际,军事,航空,无人机,这五个板块下所有的新闻数据
-
分析
- 首页没有动态加载的数据
- 爬取五个板块对应的url
- 每一个板块对应的页面中的新闻标题都是动态加载的
- 爬取新闻标题+详情页的url
- 每一条新闻详情页中的数据不是动态加载的
selenium在scrapy中使用流程
- 1.在爬虫类中实例化一个浏览器对象,将其作为爬虫类的一个属性
- 2.在中间件中实现浏览器自动化相关操作,将浏览器自动划到最底下
- 3.在爬虫类中重写closed(self,spider),在其内部关闭浏览器对象
spider源文件
# -*- coding: utf-8 -*- import scrapy from new.items import NewItem from selenium import webdriver class TengxunSpider(scrapy.Spider): name = 'tengxun' # allowed_domains = ['www.xxxx.com'] start_urls = ['https://news.163.com'] bro = webdriver.Chrome(executable_path='E:\爬虫练习\chromedriver.exe') model_urls = [] #每一个模块对应的url 后面中间件判断用 def parse(self, response): list = response.xpath("//*[@id='index2016_wrap']/div[1]/div[2]/div[2]/div[2]/div[2]/div/ul/li") index = [3,4,6,7,8] for i in index: model_url = list[i].xpath("./a/@href").get() self.model_urls.append(model_url) #对每一个板块内的url发请求 for url in self.model_urls: print(url) yield scrapy.Request(url=url,callback=self.parse_model) #数据解析:新闻标题+新闻详情页的url(动态加载) def parse_model(self,response): #直接对response解析新闻标题数据是无法获取该数据(动态加载的数据) #response是不满足当下需求的response,需要将其变成满足需求的response #满足需求的response就是包含了动态加载数据的response #满足需求的response和不满足的response区别在哪里? # 区别就在于响应数据不同。我们可以使用中间件将不满足需求的响应对象中的响应数据篡改成包含 # - 了动态加载数据的响应数据,将其变成满足需求的响应对象(response.text属性) div_list = response.xpath('/html/body/div/div[3]/div[4]/div[1]/div/div/ul/li/div/div') for div in div_list: title = div.xpath('./div/div[1]/h3/a/text()').extract_first() new_detail_url = div.xpath('./div/div[1]/h3/a/@href').extract_first() #这是判断当前详情页的url是否是广告 if new_detail_url: item = NewItem() item["title"] = title #对新闻详情页的url发起请求 yield scrapy.Request(url=new_detail_url,callback=self.parse_new_detail,meta={"item":item}) def parse_new_detail(self, response): # 解析新闻内容 content = response.xpath('//*[@id="endText"]/p/text()').extract() content = ''.join(content) item = response.meta['item'] item['content'] = content yield item #爬虫类父类的方法,该方法是爬虫结束最后一刻执行 def closed(self,spider): self.bro.quit()new\middlewares.py1
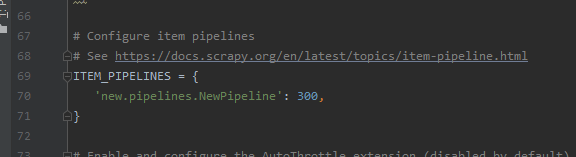
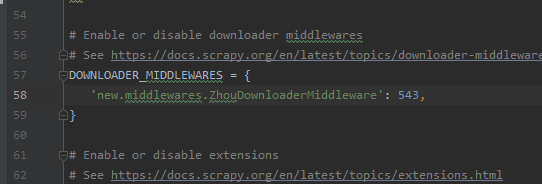
# -*- coding: utf-8 -*- # Define here the models for your spider middleware # # See documentation in: # https://docs.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals from scrapy.http import HtmlResponse #scrapy封装好的响应类 from time import sleep class ZhouDownloaderMiddleware(object): def process_request(self, request, spider): return None #拦截所有的响应对象 #整个工程发起的请求:1+5+n,相应也会有1+5+n个响应 #只有指定的5个响应对象是不满足需求的 #直接将不满足需求的5个指定的响应对象的响应数据进行篡改 def process_response(self, request, response, spider): #将拦截到的所有响应对象中指定的5个响应对象找出 if request.url in spider.model_urls: bro = spider.bro #response表示的就是指定的不满足需求的5个响应对象 #篡改响应数据:首先获取满足需求的响应数据,将其篡改到响应对象即可 #满足需求的响应数据就可以使用selenium获取 bro.get(request.url) #对五个板块发请求 sleep(2) #这是执行执行JavaScript命令 括号中的代码意思是将整个网页拉到最底部 bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') sleep(1) #捕获到了板块页面中加载出来的全部数据(包含了动态加载的数据) page_text = bro.page_source #将response.text的属性改了,在spider源文件中xpath的是自己的text属性,这样就可以获取到动态加载的数据了 # response.text = page_text # return response #另一种方法推荐! # 返回了一个新的响应对象,新的对象替换原来不满足需求的旧的响应对象 return HtmlResponse(url=request.url, body=page_text, encoding='utf-8', request=request) # 5 #url是当前请求对象对应的url return response def process_exception(self, request, exception, spider): pass别忘了settings中配置,robot,UA,LOG
- 首页没有动态加载的数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号