操作Excel文件(xlrd模块)
读取excel文件
有两种方式获取到Excel中的sheet:
-
通过索引:
sheet_by_index(0)。 -
通过sheet名称:
sheet_by_name('自动化')就是你sheet的名字 就是那个sheet1,sheet2
import xlrd 导入xlrd模块
book = xlrd.open_workbook(r'D:\Testing\zhoushen\接口测试示例.xlsx')
sheet = book.sheet_by_index(0) 获取的是索引为第一个的文件对象 就是excel底下还有个工作表1那个位置
#sheet=book.sheet_by_name("工作表1")
sheet1 sheet2 sheet3 取工作表1就是索引为0 下边第一张截图有显示
print(sheet.nrows) 获取行数 所有行 返回的是int 几行的意思
print(sheet.ncols) 获取列数 所有列 返回的也是int
获取每行的内容
for row in range(sheet.nrows):
print(sheet.row_values(row)) 列表形式

获取每列的内容
for col in range(sheet.ncols):
print(sheet.col_values(col))
# 获取指定行的内容# print(sheet.row_values(1)) 索引从0开始 这个1是第二行
将每行都和首行组成字典,存放在一个列表中
l = []
title = sheet_by_name.row_values(0)
# print(title)
for row in range(1, rows):
l.append(dict(zip(title, sheet_by_name.row_values(row))))
print(l)

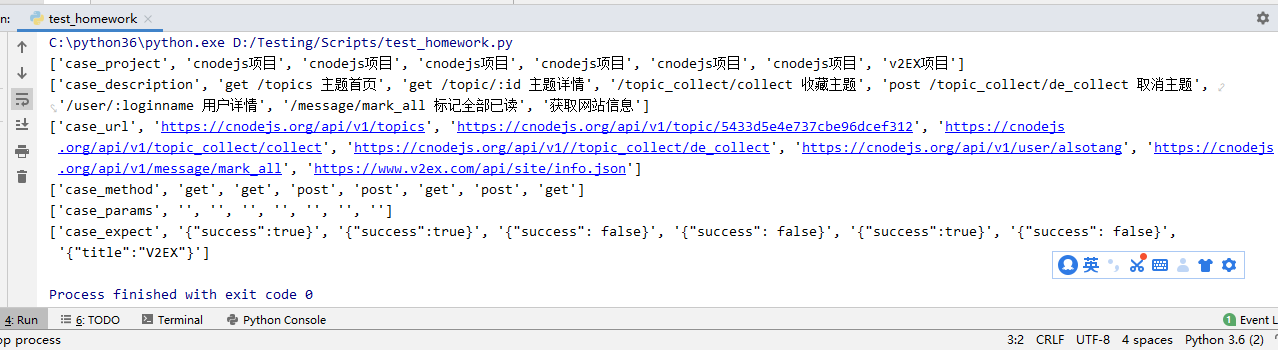
以上图片是效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号