
UDP数据报
一、UDP的概述(User Datagram Protocol,用户数据报协议)
UDP是传输层的协议,功能即为在IP的数据报服务之上增加了最基本的服务:复用和分用以及差错检测。
UDP提供不可靠服务,具有TCP所没有的优势:
-
UDP无连接,时间上不存在建立连接需要的时延。空间上,TCP需要在端系统中维护连接状态,需要一定的开销。此连接装入包括接收和发送缓存,拥塞控制参数和序号与确认号的参数。UCP不维护连接状态,也不跟踪这些参数,开销小。空间和时间上都具有优势。
举个例子:DNS如果运行在TCP之上而不是UDP,那么DNS的速度将会慢很多。
HTTP使用TCP而不是UDP,是因为对于基于文本数据的Web网页来说,可靠性很重要。
同一种专用应用服务器在支持UDP时,一定能支持更多的活动客户机。 -
分组首部开销小**,TCP首部20字节,UDP首部8字节。
-
UDP没有拥塞控制,应用层能够更好的控制要发送的数据和发送时间,网络中的拥塞控制也不会影响主机的发送速率。某些实时应用要求以稳定的速度发送,能容 忍一些数据的丢失,但是不能允许有较大的时延(比如实时视频,直播等)
-
UDP提供尽最大努力的交付,不保证可靠交付。所有维护传输可靠性的工作需要用户在应用层来完成。没有TCP的确认机制、重传机制。如果因为网络原因没有传送到对端,UDP也不会给应用层返回错误信息
-
UDP是面向报文的,对应用层交下来的报文,添加首部后直接乡下交付为IP层,既不合并,也不拆分,保留这些报文的边界。对IP层交上来UDP用户数据报,在去除首部后就原封不动地交付给上层应用进程,报文不可分割,是UDP数据报处理的最小单位。
正是因为这样,UDP显得不够灵活,不能控制读写数据的次数和数量。比如我们要发送100个字节的报文,我们调用一次sendto函数就会发送100字节,对端也需要用recvfrom函数一次性接收100字节,不能使用循环每次获取10个字节,获取十次这样的做法。 -
UDP常用一次性传输比较少量数据的网络应用,如DNS,SNMP等,因为对于这些应用,若是采用TCP,为连接的创建,维护和拆除带来不小的开销。UDP也常用于多媒体应用(如IP电话,实时视频会议,流媒体等)数据的可靠传输对他们而言并不重要,TCP的拥塞控制会使他们有较大的延迟,也是不可容忍的
二、UDP的首部格式
UDP数据报分为首部和用户数据部分,整个UDP数据报作为IP数据报的数据部分封装在IP数据报中,UDP数据报文结构如图所示:

UDP首部有8个字节,由4个字段构成,每个字段都是两个字节,
1.源端口: 源端口号,需要对方回信时选用,不需要时全部置0.
2.目的端口:目的端口号,在终点交付报文的时候需要用到。
3.长度:UDP的数据报的长度(包括首部和数据)其最小值为8(只有首部)
4.校验和:检测UDP数据报在传输中是否有错,有错则丢弃。
该字段是可选的,当源主机不想计算校验和,则直接令该字段全为0.
当传输层从IP层收到UDP数据报时,就根据首部中的目的端口,把UDP数据报通过相应的端口,上交给应用进程。
如果接收方UDP发现收到的报文中的目的端口号不正确(不存在对应端口号的应用进程0,),就丢弃该报文,并由ICMP发送“端口不可达”差错报文给对方。
UDP校验
在计算校验和的时候,需要在UDP数据报之前增加12字节的伪首部,伪首部并不是UDP真正的首部。只是在计算校验和,临时添加在UDP数据报的前面,得到一个临时的UDP数据报。校验和就是按照这个临时的UDP数据报计算的。伪首部既不向下传送也不向上递交,而仅仅是为了计算校验和。这样的校验和,既检查了UDP数据报,又对IP数据报的源IP地址和目的IP地址进行了检验。
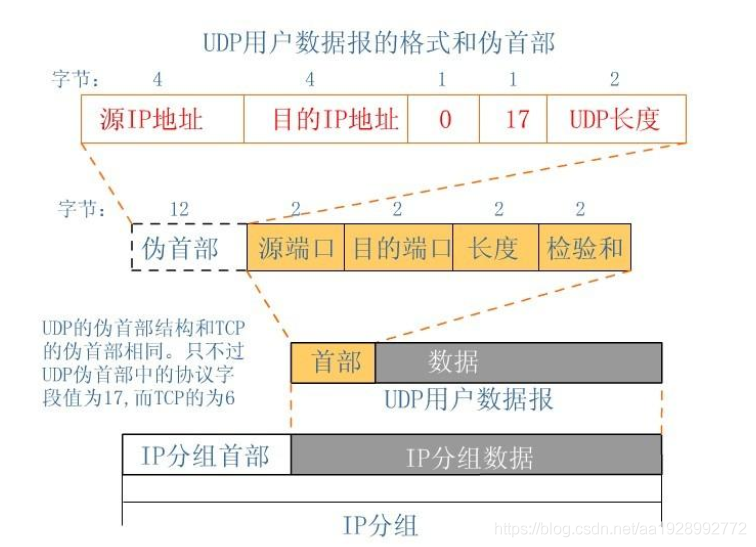
UDP校验和的计算方法和IP数据报首部校验和的计算方法相似,都使用二进制反码运算求和再取反,但不同的是:IP数据报的校验和之检验IP数据报和首部,但UDP的校验和是把首部和数据部分一起校验。
发送方,首先是把全零放入校验和字段并且添加伪首部,然后把UDP数据报看成是由许多16位的子串连接起来,若UDP数据报的数据部分不是偶数个字节,则要在数据部分末尾增加一个全零字节(此字节不发送),接下来就按照二进制反码计算出这些16位字的和。将此和的二进制反码写入校验和字段。在接收方,把收到得UDP数据报加上伪首部(如果不为偶数个字节,还需要补上全零字节)后,按二进制反码计算出这些16位字的和。当无差错时其结果全为1,。否则就表明有差错出现,接收方应该丢弃这个UDP数据报。
注意:
1.校验时,若UDP数据报部分的长度不是偶数个字节,则需要填入一个全0字节,但是次字节和伪首部一样,是不发送的。
2.如果UDP校验和校验出UDP数据报是错误的,可以丢弃,也可以交付上层,但是要附上错误报告,告诉上层这是错误的数据报。
3.通过伪首部,不仅可以检查源端口号,目的端口号和UDP用户数据报的数据部分,还可以检查IP数据报的源IP地址和目的地址。
这种差错检验的检错能力不强,但是简单,速度快
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
在如何封装一个数据包上,是一个非常细致的问题,而利用UDP协议来封装的话,是比较简单,让我们一步步来分析典型的TCP/IP协议。一般来说一个典型的一个数据包,包括以太网MAC头+网络层IP数据头+传输层UDP头+要传输的数据。让我们一层层来看看这些数据头是如何构成的。
1、以太网MAC头
一般情况下,以太网MAC头由14个字节构成,12个自己的MAC地址+上层协议的标识符。举个例子
如果你要发送的目标MAC位00:1d:09:10:d1:9c,而你的MAC地址为01:60:6e:11:02:0f,上层一般都是网络层,即为IP层,IP层的标识符为0x8000,那么你的以太网MAC头就为
00 1d 09 10 d1 9c 01 60 6e 11 02 0f 80 00.
下面是更详细的解释,引用http://blog.csdn.net/louiswang2009/archive/2010/05/04/5554524.aspx这片博客。
8字节的前导用于帧同步,CRC域用于帧校验。这些用户不必关心其由网卡芯片自动添加。目的地址和源地址是指网卡的物理地址,即MAC地址,具有唯一性。帧类型或协议类型是指数据包的高级协议,如 0x0806表示ARP协议,0x0800表示IP协议等。
2、网络层IP头
0x45, 0x00, IPlenght_h, IPlenght_l,
0x00, 0x00, 0x00, 0x00, 0x80, 0x11,
IPchecksum4, IPchecksum5,
IPsource_1, IPsource_2, IPsource_3, IPsource_4,IPdestination_1, IPdestination_2, IPdestination_3, IPdestination_4
上面是一个简单的ip头的例子,下面一个个的来解释啊!
0x45,其中的高位0x4,表示的是版本号,ipv4的意思,而后面低字节5表示的是指明IPv4协议包头长度的字节数包含多少个32位,这里是5,也就是说协议头是5*4=20个字节的大小。
0x00,定义IP封包在传送过程中要求的服务类型,如果所有4bit均为0,那么就意味着是一般服务,具体如下:
◆000..... (Routine): 过程字段,占3位。设置了数据包的重要性,取值越大数据越重要,取值范围为:0(正常)~ 7(网络控制)
◆...0....(Delay):延迟字段 ,占1位,取值:0(正常)、1(期特低的延迟)
◆....0...(Throughput):流量字段,占1位。取值:0(正常)、1(期特高的流量)
◆.....0..(Reliability) :可靠性字段,占1位。取值:0(正常)、1(期特高的可靠性)
◆…..0.(ECN-Capable Transport):显式拥塞指示传输字段,占1位。由源端设置,以显示源端节点的传输协议是支持ECN(Explicit Cogestion Notifica tion,显式拥塞指示)的。取值:0(不支持ECN)、1(支持ECN)
◆.......0(Congestion Experienced):拥塞预警字段,占1位。取值:0(正常,不拥塞)、1(拥塞)
IPlenght_h, IPlenght_l,表示的是包总长度=IP头长度+UDP头长度+数据长度,最后讲长度分为高8位和低8位。
0x00, 0x00,是上面的标志位,16个字节。每一个IP封包都有一个16位的唯一识别码。当程序产生的数据要通过网络传送时都会被拆散成封包形式发送,当封包要进行重组的时候这个ID就是依据了。
0x00, 0x00这16位是由两部分组成,包括3bit的标记位和13bit的分段偏移量。
这是当封包在传输过程中进行最佳组合时使用的3个bit的识别记号。占3位。
◆000(Reserved Fragment):保留分段。当此值为0的时候表示目前未被使用。
◆.0.(Don't Fragment):不分段。当此值为0的时候表示封包可以被分段,如果为1则不能被分割。
◆..0( More Fragment):更多分段。当上一个值为0时,此值为0就示该封包是最後一个封包,如果为1则表示其後还有被分割的封包。
IP协议头格式规定当封包被分段之后,由于网路情况或其它因素影响其抵达顺序不会和当初切割顺序一至,所以当封包进行分段的时候会为各片段做好定位记录,以便在重组的时候就能够
对号入座。值为多少个字节,如果封包并没有被分段,则FO值为“0"。 占13位。
0x80表示生存时间。生存时间字段设置了数据报可以经过的最多路由器数,表示数据包在网络上生存多久。TTL的初始值由源主机设置(通常为32或64),一旦经过一个处理它的路由器,它的值就减去1。当该字段的值为0时,数据报就被丢弃,并发送ICMP消息通知源主机。这样当封包在传递过程中由於某些原因而未能抵达目的地的时候就可以避免其一直充斥在网路上面。占8位。
0x11表示的是传输层的协议。如下表所示:
IPchecksum4, IPchecksum5这两个是头校验和的高8位和低8位。
指IPv4数据报包头的校验和。这个数值用来检错用的,用以确保封包被正确无误的接收到。当封包开始进行传送后,接收端主机会利用这个检验值会来检验余下的封包,如果一切无误就会发出确认信息表示接收正常。与UDP和TCP协议包头中的校验和作用是一样的。占16位。
首部检验和字段是根据IP首部计算的检验和码,不对首部后面的数据进行计算。ICMP、IGMP、UDP和TCP协议在它们各自的首部中均含有同时覆盖首部和数据检验和码。
IP协议头格式规定了:计算一份数据报的IP检验和,首先把检验和字段置为0。然后,对首部中每个16位进行二进制反码求和(整个首部看成是由一串16位的字组成),结果存在检验和字段中。当接收端收到一份IP数据报后,同样对首部中每个16 位进行二进制反码的求和。由于接收方在计算过程中包含了发送方存在首部中的检验和,因此,如果首部在传输过程中没有发生任何差错,那么接收方计算的结果应该为全1。如果结果不是全1(即检验和错误),那么IP就丢弃收到的数据报。但是不生成差错消息,由上层去发现丢失的数据报并进行重传。
ICMP、IGMP、UDP和TCP都采用相同的检验和算法,尽管TCP和UDP除了本身的首部和数据外,在IP首部中还包含不同的字段。由于路由器经常只修改TTL字段(减1),因此当路由器转发一份消息时可以增加它的检验和,而不需要对IP整个首部进行重新计算。
IPsource_1, IPsource_2, IPsource_3, IPsource_4,IPdestination_1, IPdestination_2, IPdestination_3, IPdestination_4这两个就表示了源IP和目标IP。
3、UDP数据头
0x04, 0x00,0x04, 0x00, lenght_h, lenght_l, 0x00, 0x00
0x04, 0x00表示的是UDP的源端口,这里为1024;
0x04, 0x00表示的是UDP的目标端口,这里为1024;
lenght_h, lenght_l,为整个数据包的长度,包括MAC头+ip头+UDP头+校验位。
0x00, 0x00这些是UDP协议的选项和填充位。
这两个选项较少使用,只有某些特殊的封包需要特定的控制才会利用到。这些选项通常包括:
◆安全和处理限制:用于军事领域
◆记录路径:让每个路由器都记下它的IP地址
◆时间戳:让每个路由器都记下它的IP地址和时间
◆宽松的源站选路:为数据报指定一系列必须经过的IP地址
◆严格的源站选路:与宽松的源站选路类似,但是要求只能经过指定的这些地址,不能经过其他的地址。
以上这些选项很少被使用,而且并非所有的主机和路由器都支持这些选项。
总结:
上面是对一个UDP封装数据的总结,便于以后更好的记忆。
----------------------------------------------------------------------------------------------------
所谓的ASCII和16进制都只是概念上的东西,在计算机中通通是二进制
转换应该是输出的转换,同样是一个数,在计算机内存中表示是一样的,只是输出不一样
ASCII是针对字符的编码,几乎是键盘上的字符的编码。下面是一张ASCII和16进制的对应表:
| ASCII与16进制转换 | |||||||
| ASCII | 16进制 | ASCII | 16进制 | ASCII | 16进制 | ASCII | 16进制 |
| NUL | 00H | DLE | 10H | SP | 20H | 0 | 30H |
| SOH | 01H | DC1 | 11H | ! | 21H | 1 | 31H |
| STX | 02H | DC2 | 12H | " | 22H | 2 | 32H |
| ETX | 03H | DC3 | 13H | # | 23H | 3 | 33H |
| EOT | 04H | DC4 | 14H | $ | 24H | 4 | 34H |
| ENQ | 05H | NAK | 15H | % | 25H | 5 | 35H |
| ACK | 06H | SYN | 16H | & | 26H | 6 | 36H |
| BEL | 07H | ETB | 17H | ' | 27H | 7 | 37H |
| BS | 08H | CAN | 18H | ( | 28H | 8 | 38H |
| HT | 09H | EM | 19H | ) | 29H | 9 | 39H |
| LF | 0AH | SUB | 1AH | * | 2AH | : | 3AH |
| VT | 0BH | ESC | 1BH | + | 2BH | ; | 3BH |
| FF | 0CH | FS | 1CH | , | 2CH | < | 3CH |
| CR | 0DH | GS | 1DH | _ | 2DH | = | 3DH |
| SO | 0EH | RS | 1EH | . | 2EH | > | 3EH |
| SI | 0FH | US | 1FH | / | 2FH | ? | 3FH |
| ASCII | 16进制 | ASCII | 16进制 | ASCII | 16进制 | ASCII | 16进制 |
| @ | 40H | P | 50H | 、 | 60H | p | 70H |
| A | 41H | Q | 51H | a | 61H | q | 71H |
| B | 42H | R | 52H | b | 62H | r | 72H |
| C | 43H | S | 53H | c | 63H | s | 73H |
| D | 44H | T | 54H | d | 64H | t | 74H |
| E | 45H | U | 55H | e | 65H | u | 75H |
| F | 46H | V | 56H | f | 66H | v | 76H |
| G | 47H | W | 57H | g | 67H | w | 77H |
| H | 48H | X | 58H | h | 68H | x | 78H |
| I | 49H | Y | 59H | i | 69H | y | 79H |
| J | 4AH | Z | 5AH | j | 6AH | z | 7AH |
| K | 4BH | [ | 5BH | k | 6BH | { | 7BH |
| L | 4CH | \ | 5CH | l | 6CH | ㄧ | 7CH |
| M | 4DH | ] | 5DH | m | 6DH | } | 7DH |
| N | 4EH | ↑ | 5EH | n | 6EH | ~ | 7EH |
| O | 4FH | ← | 5FH | o | 6FH | DEL | 7FH |
关于这张表,主要是键盘上的键值字符在计算机中的二进制存储,为了方便,转化成的16进制表示。
所以,45的ASCII表示就是4的ASCII表示和5的ASCII表示联结起来的。
每个ASCII字符转化成16进制是两位的16进制数,同样,把16进制数转化成ASCII时是两位一起转化成一个ASCII字符,然后把他们联结起来。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
UDP数据分析
问题:护网结束后从离职同事手上接过一项目,开发反馈对方接收不到我们这边的发过去的告警数据信息(UDP)
1.查看网络连通 ;
2.测试端口连通 nc -vuz <目标服务器 IP> <待测试端口>
v:详细信息
u:UDP协议
z:不发送数据
3.抓包:tcpdump -i any -vv -A udp and host <目标服务器 IP>
简单测试连通性正常
但对方确实收不到包;无法登陆对方服务器;于是弄一台外省机器模拟UDP通信测试
192.168.109.138 模拟为UDP服务端,监听UDP端口1162,
[root@hywang-138 ~]# nc -ulp 1162
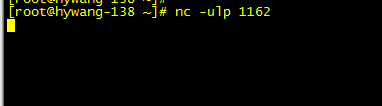
现在客户端模拟通信,nc -u 192.168.109.138 1162

并抓包查看
[root@localhost ~]# tcpdump -i any -vv -A udp port 1162 and host 192.168.109.138

此时客户端开始发送数据测试:

此时服务端会收到数据:

抓包会看到对应数据

说明,我们服务器发送数据是正常的;
然后看看服务端给回数据是否正常
此时服务端手动回一条数据:

客户端可以看见
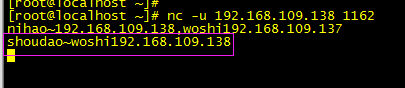
抓包数据可以看见

故判断是对方防火墙问题,协助解决问题
