
数据采集与融合技术第四次作业
数据采集与融合技术第四次作业
| 学号 | 102202124 |
| 姓名 | 阿依娜孜·赛日克 |
| 本次作业gitee链接 | https://gitee.com/ayinazi/crawl_project/tree/master/作业4 |
作业背景与目标
本次作业聚焦于数据采集与融合技术领域,通过三项任务深入考察对相关技术的掌握程度,旨在全面提升我们在 Selenium 框架运用、数据库交互以及数据采集流程等方面的专业技能,为后续深入学习数据处理与分析奠定坚实基础。
一、Selenium 数据爬取实战
(一)股票数据爬取
在本次作业中,首先使用 Selenium 框架对东方财富网的股票数据进行爬取。以下是主要代码:
# 定义板块对应的URL和名称列表
board_urls = [
("http://quote.eastmoney.com/center/gridlist.html#hs_a_board", "沪深A股"),
("http://quote.eastmoney.com/center/gridlist.html#sh_a_board", "上证A股"),
("http://quote.eastmoney.com/center/gridlist.html#sz_a_board", "深证A股")
]
# 循环爬取各个板块数据
for board_url, board_name in board_urls:
driver.get(board_url)
# 等待页面加载
try:
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, "//table")))
except TimeoutException:
print(f"{board_name} 页面加载超时")
continue
# 提取数据
rows = driver.find_elements(By.XPATH, "//table/tbody/tr")
for row in rows:
cells = row.find_elements(By.TAG_NAME, "td")
if cells:
# 提取并存储数据到数据库
stock_data = {
'code': cells[1].text,
'name': cells[2].text,
'latest_price': cells[4].text,
'change_degree': cells[5].text.replace('%', '').strip(),
'change_amount': cells[6].text,
'count': cells[7].text.replace('万', '').strip(),
'money': cells[8].text,
'zfcount': cells[9].text.replace('%', '').strip(),
'highest': cells[10].text,
'lowest': cells[11].text,
'today': cells[12].text,
'yestoday': cells[13].text
}
# 转换为适当的数据类型
try:
stock_data['change_degree'] = float(stock_data['change_degree']) / 100
stock_data['zfcount'] = float(stock_data['zfcount']) / 100
# 处理成交量,将万转换为实际数值
stock_data['count'] = float(stock_data['count']) * 10000
# 处理成交额,将亿或万转换为实际数值
if '亿' in stock_data['money']:
stock_data['money'] = float(stock_data['money'].replace('亿', '').strip()) * 100000000
elif '万' in stock_data['money']:
stock_data['money'] = float(stock_data['money'].replace('万', '').strip()) * 10000
else:
stock_data['money'] = float(stock_data['money'])
except ValueError as e:
print(f"{board_name} 数据转换错误: {stock_data}, 错误: {e}")
continue
# 插入数据到MySQL
insert_query = """
INSERT INTO stocks (code, name, latest_price, change_degree, change_amount, count, money, zfcount, highest, lowest, today, yestoday)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
try:
mycursor.execute(insert_query, (
stock_data['code'], stock_data['name'], stock_data['latest_price'],
stock_data['change_degree'],
stock_data['change_amount'], stock_data['count'],
stock_data['money'], stock_data['zfcount'],
stock_data['highest'], stock_data['lowest'],
stock_data['today'], stock_data['yestoday']
))
mydb.commit()
except mysql.connector.Error as err:
print(f"{board_name} 插入数据时出错: {err}")
mydb.rollback()
运行结果:
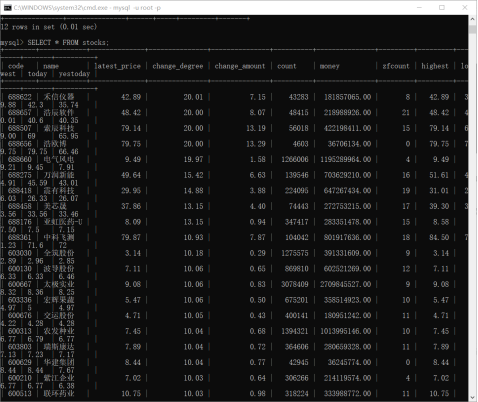
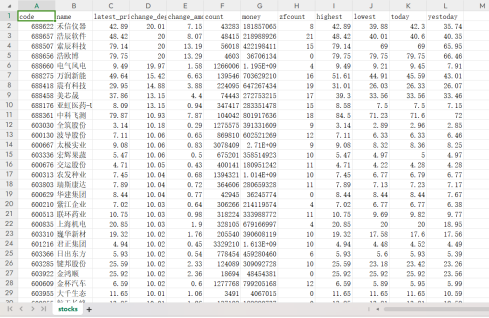
(二)MOOC 课程资源爬取
同样使用 Selenium 对中国 mooc 网课程资源进行爬取。代码如下:
class moocDB:
def openDB(self):
self.con = sqlite3.connect("mooc.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("CREATE TABLE mooc (Num VARCHAR(16), Name VARCHAR(16), School VARCHAR(16), Teacher VARCHAR(16), Team VARCHAR(16), Person VARCHAR(16), Jindu VARCHAR(16),")
except sqlite3.OperationalError:
self.cursor.execute("DELETE FROM mooc")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, count, name, school, teacher, team, person, jindu, jianjie):
print(f"Inserting record {count}: Name={name}, School={school}, Teacher={teacher}, Team={team}, Person={person}, Jindu={jindu}, Jianjie={jianjie}")
self.cursor.execute("INSERT INTO mooc (Num, Name, School, Teacher, Team, Person, Jindu, Jianjie) VALUES (?,?,?,?,?,?,?,?)",
(count, name, school, teacher, team, person, jindu, jianjie))
def export_to_csv(self, csv_path):
# 导出数据库数据到 CSV 文件
self.cursor.execute("SELECT * FROM mooc")
rows = self.cursor.fetchall()
# 写入 CSV 文件
with open(csv_path, mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Num', 'Name', 'School', 'Teacher', 'Team', 'Person', 'Jindu', 'Jianjie']) # Header
writer.writerows(rows)
print(f"Data exported to {csv_path}")
def login():
login_button = browser.find_element(By.XPATH, '//a[@class="f-f0 navLoginBtn"]')
login_button.click()
frame = browser.find_element(By.XPATH, '//div[@class="ux-login-set-container"]/iframe')
browser.switch_to.frame(frame)
inputUserName = browser.find_element(By.XPATH, '//div[@class="u-input box"][1]/input')
inputUserName.send_keys("15909018227")
inputPasswd = browser.find_element(By.XPATH, '//div[@class="inputbox"]/div[2]/input[2]")
inputPasswd.send_keys("20020925Aa.")
login_button = browser.find_element(By.XPATH, '//*[@id="submitBtn"]')
login_button.click()
time.sleep(5)
def next_page():
next_button = browser.find_element(By.XPATH, '//li[@class="ux-pager_btn ux-pager_btn__next"]/a')
next_button.click()
def start_spider(moocdb):
browser.get(url)
count = 0
for i in range(2):
WebDriverWait(browser, 1000).until(EC.presence_of_all_elements_located((By.ID, "j-courseCardListBox")))
time.sleep(random.randint(3, 6))
browser.execute_script('document.documentElement.scrollTop=0')
for link in browser.find_elements(By.XPATH, '//div[@class="u-clist f-bgw f-cb f-pr j-href ga-click"]'):
count += 1
try:
name = link.find_element(By.XPATH, './/span[@class=" u-course-name f-thide"]').text
except:
name = 'none'
try:
school = link.find_element(By.XPATH, './/a[@class="t21 f-fc9"]').text
except:
school = 'none'
try:
teacher = link.find_element(By.XPATH, './/a[@class="f-fc9"]').text
except:
teacher = 'none'
try:
team = link.find_element(By.XPATH, './/span[@class="f-fc9"]').text
except:
team = 'none'
try:
person = link.find_element(By.XPATH, './/span[@class="hot"]').text
except:
person = 'none'
try:
jindu = link.find_element(By.XPATH, './/span[@class="txt"]').text
except:
jindu = 'none'
try:
jianjie = link.find_element(By.XPATH, './/span[@class="p5 brief f-ib f-f0 f-cb"]').text
except:
jianjie = 'none'
moocdb.insert(count, name, school, teacher, team, person, jindu, jianjie)
next_page()
login()
运行结果:保存为 csv 文件
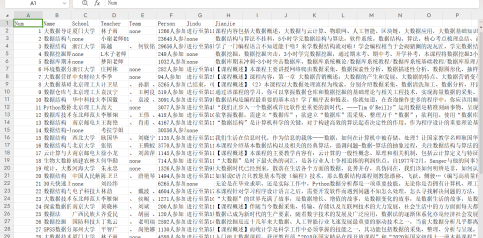
二、大数据实验探索
(一)华为云大数据实验关键步骤
在华为云大数据实时分析处理实验中,按照实验手册完成了一系列任务。
-
环境搭建:成功开通了 MapReduce 服务,这为后续的大数据处理提供了基础环境支持。
![]()
![]()
![]()
-
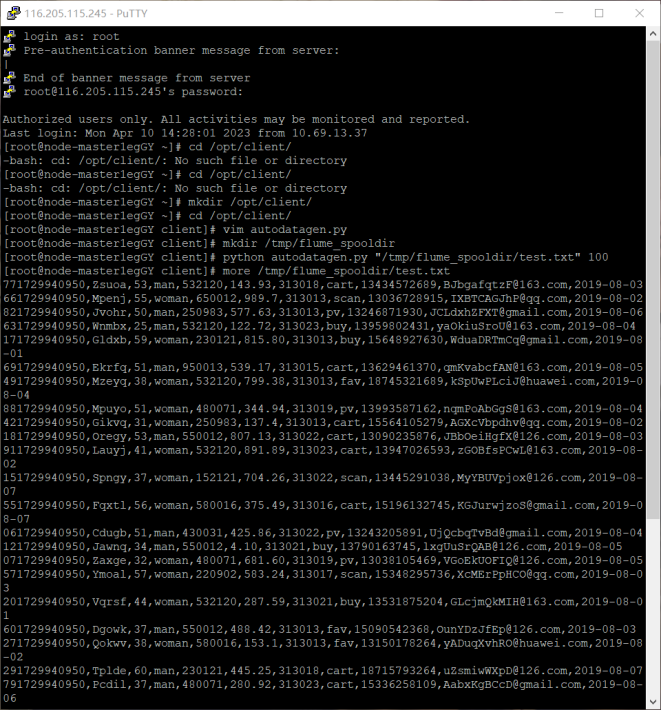
任务一:python 脚本生成测试数据:
![]()
-
任务二:配置 Kafka:对 Kafka 进行了配置,设置了相关的主题、生产者和消费者参数,确保数据能够在不同组件之间高效地传输和处理。
![]()
![]()
![]()
-
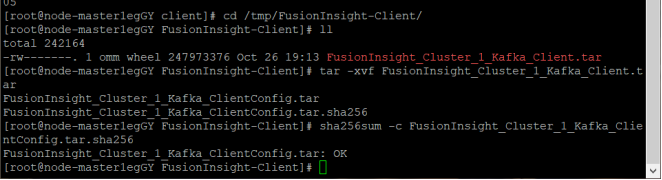
任务三:安装 Flume 客户端:在相应的环境中安装了 Flume 客户端,为数据采集做好准备。
![]()
![]()
![]()
-
任务四:配置 Flume 采集数据:根据实验要求,配置了 Flume 的数据源、通道和接收器,使得 Flume 能够准确地采集 Python 脚本生成的测试数据,并将其传输到指定的目的地,如 Kafka 主题。
![]()
![]()
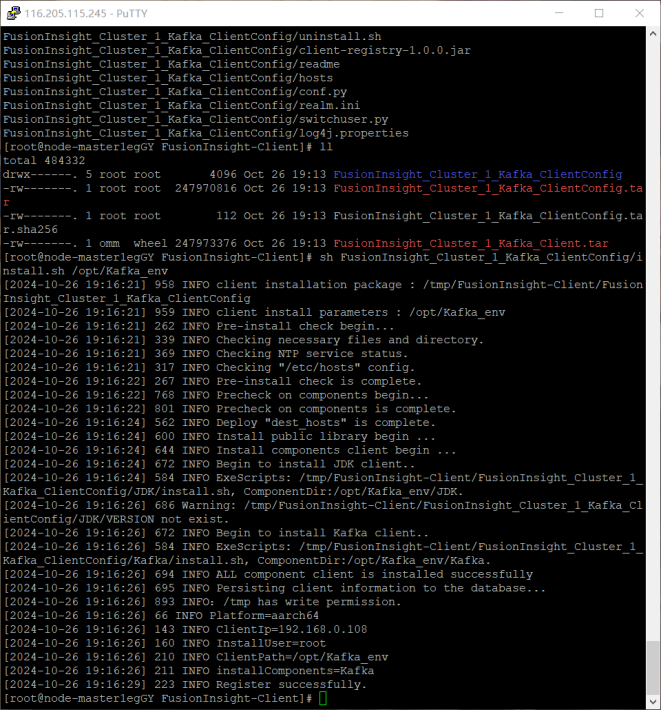
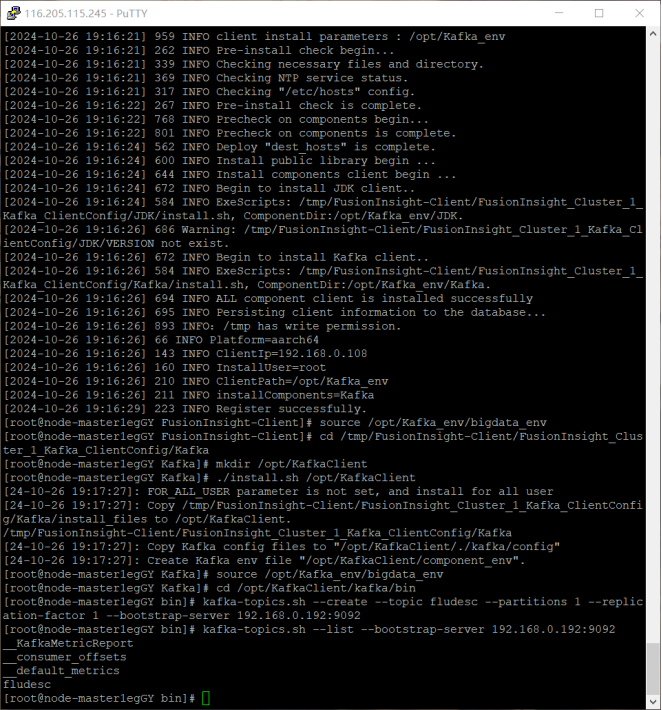
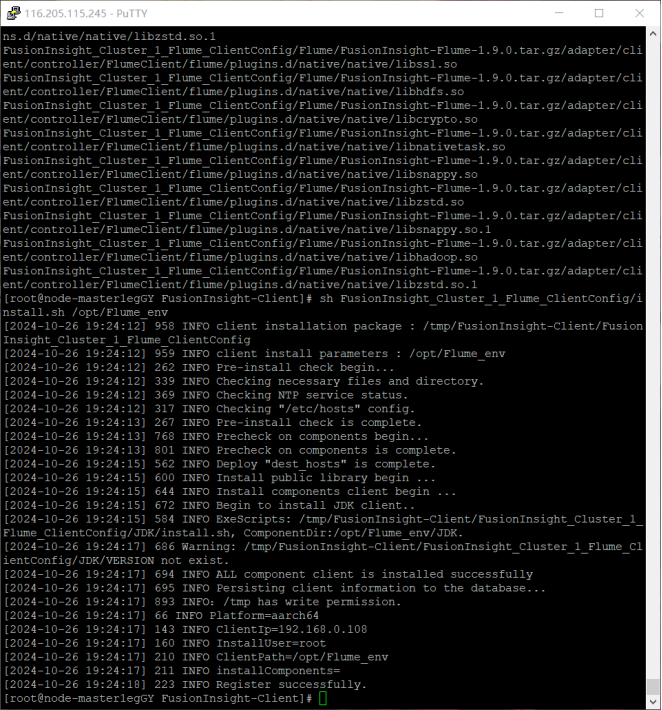
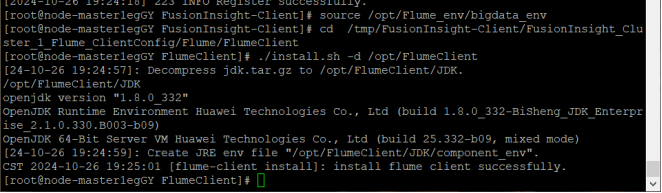

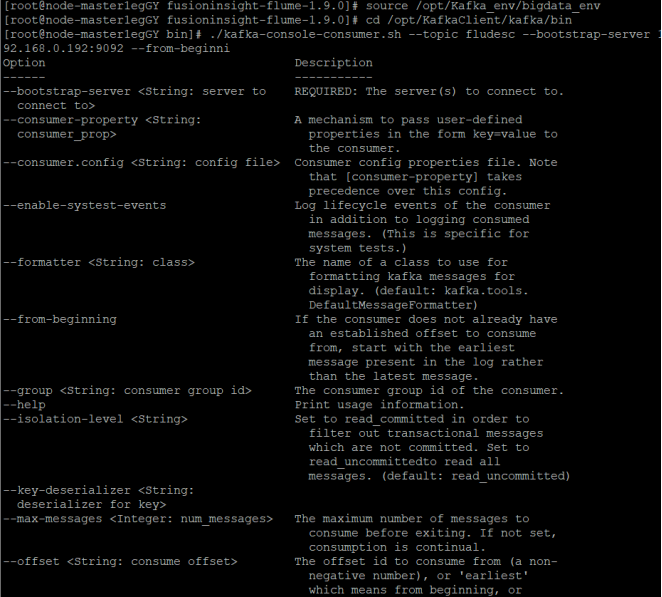
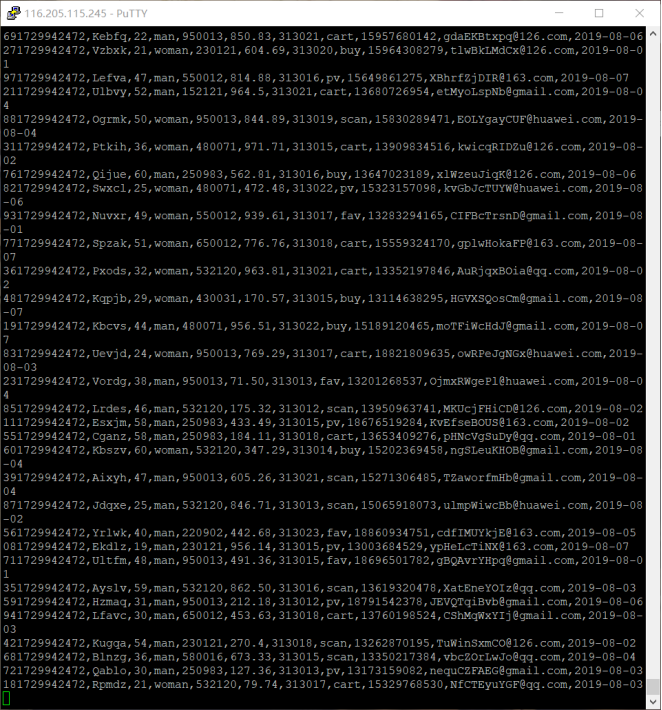
在整个实验过程中,每一个步骤都紧密相连,从数据生成到最终的采集,构建了一个完整的数据处理流程的前端部分。
(二)作业心得
通过本次作业,我对 Selenium 框架有了更深入的理解和掌握。在爬取股票数据和 MOOC 课程资源时,深刻体会到了 Selenium 查找 HTML 元素的强大功能,尤其是在处理动态网页和 Ajax 数据时,它能够有效地获取到完整的数据信息。同时,在与 MySQL 数据库结合使用过程中,也进一步熟悉了数据库的操作流程,包括表的创建、数据的插入和事务的处理等。
在大数据实验方面,从环境搭建到各个任务的完成,让我对大数据处理的流程有了初步的认识。了解到数据在不同组件之间的流转和处理方式,明白了每个环节的重要性。例如,Python 脚本生成测试数据为整个实验提供了基础数据,而 Kafka 和 Flume 的配置则确保了数据能够在分布式环境中稳定地传输和采集。这不仅拓宽了我的技术视野,也让我意识到在大数据领域还有很多知识需要深入学习和探索。在未来的学习和实践中,我将继续努力,提升自己在数据处理和分析方面的能力,更好地应对复杂的数据处理任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号