
数据采集与融合技术第一次作业
数据采集与融合技术第一次作业
本次作业的源码和数据已经上传码云:https://gitee.com/ayinazi/crawl_project/tree/master/作业1
| 描述 | 详情 |
|---|---|
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology |
| 本次作业的链接 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology/homework/13286 |
| 学号姓名 | 102202124阿依娜孜 |
在当今数字化的时代,数据采集与融合技术成为了获取和处理信息的关键手段。本博客将详细介绍我在完成数据采集与融合技术第一次作业过程中的经历、收获以及遇到的问题与解决方案。
目录
作业①:大学排名信息爬取
任务概述
在这个作业中,我们的目标是从某大学排名网站获取详细的信息,包括排名、学校名称、城市、类型以及分数等关键数据。这不仅需要我们对网页结构有深入的理解,还涉及到如何准确地提取和整理所需数据,是对我们网页解析和数据处理能力的一次考验。
代码实现
为了实现这个目标,我使用了 requests 和 BeautifulSoup 这两个强大的 Python 库。以下是具体的代码:
import requests
from bs4 import BeautifulSoup
# 给定网址
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
# 发起请求
response = requests.get(url)
response.encoding = 'utf-8' # 设置编码为utf-8
# 解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 找到排名表格
table = soup.find('table') # 根据实际网页结构可能需要调整
# 提取表格中的数据
rows = table.find_all('tr')
# 打印表头
print(f"{'排名':<5} {'学校名称':<15} {'省市':<10} {'学校类型':<10} {'总分':<5}")
# 遍历每一行,提取数据
for row in rows[1:]: # 跳过表头
cols = row.find_all('td')
if len(cols) > 0:
rank = cols[0].text.strip() # 排名
name = cols[1].text.strip() # 学校名称
city = cols[2].text.strip() # 省市
type_ = cols[3].text.strip() # 学校类型
score = cols[4].text.strip() # 总分
# 只输出中文名
print(f"{rank:<5} {name:<15} {city:<10} {type_:<10} {score:<5}")
作业结果
通过运行上述代码,我们成功地获取了大学排名信息,并以清晰的格式进行了输出。以下是部分结果的截图:

作业心得
在完成这个作业的过程中,我对 Python 网络爬虫的基础概念有了更深入的理解和掌握。
- 我学会了如何使用
requests库发送 HTTP 请求来获取网页内容,这是网络爬虫的第一步,也是获取数据的基础。 - 掌握了
BeautifulSoup库的基本用法,能够有效地解析 HTML 文档,从中提取出我们需要的数据。例如,通过定位表格元素table,再遍历表格的行和列,准确地提取出排名、学校名称等信息。 - 在数据处理方面,我学会了如何对提取的数据进行清洗和格式化,如去除字符串中的多余空格,以确保输出的数据整齐、规范。
- 同时,我也意识到在处理数据时需要保持严谨的态度,特别是在解析复杂的网页结构时,要仔细检查每一个步骤,确保数据的准确性和完整性。
作业②:商城商品比价爬虫
任务概述
本次作业的目标是从在线商城抓取商品信息,尤其是商品的价格和名称,以便进行比价分析。这要求我们更深入地理解网页结构,熟练运用数据提取技术,同时也考验我们对不同数据格式的处理能力。
代码实现
以下是我实现商城商品比价爬虫的代码:
import re
import urllib.parse
import urllib.request
import chardet
# 获取爬取网页的 HTML 文本
def getHTMLText(url):
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36"
}
try:
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
raw_data = response.read()
encoding = chardet.detect(raw_data)['encoding']
data = raw_data.decode(encoding)
return data
except Exception as err:
print(f"请求错误:{err}")
return ""
# 从 HTML 文本中用正则表达式提取商品名称和价格
def parsePage(info, data):
print("解析数据中...")
# 提取价格
prices = re.findall(r'¥(\d+(?:,\d+)*\.\d{2})', data)
# 提取商品名称
names = re.findall(r'alt=\'(.*?)\'', data)
print(prices)
print(names)
for i in range(min(len(names), len(prices))):
price = prices[i].replace(',', '') # 去掉价格中的逗号
name = names[i].strip()
info.append([i + 1, price, name])
return info
# 格式化打印商品相关信息
def printGoodslist(info):
tplt = "{0:^5}\t{1:^10}\t{2:^20}"
print(tplt.format("序号", "价格", "商品名称"))
for item in info:
print(tplt.format(item[0], item[1], item[2]))
# 主函数:爬取网页,并格式化输出结果
def main():
goods = urllib.parse.quote(input("请输入要爬取的商品:"))
page = int(input("请输入要获取的页面序列:"))
print("正在爬取...")
url = f'https://search.dangdang.com/?key={goods}&act=input&page_index={page}'
info = []
data = getHTMLText(url)
if data:
print("HTML 文本获取成功!")
parsePage(info, data)
printGoodslist(info)
else:
print("HTML 文本获取失败。")
if __name__ == "__main__":
main()
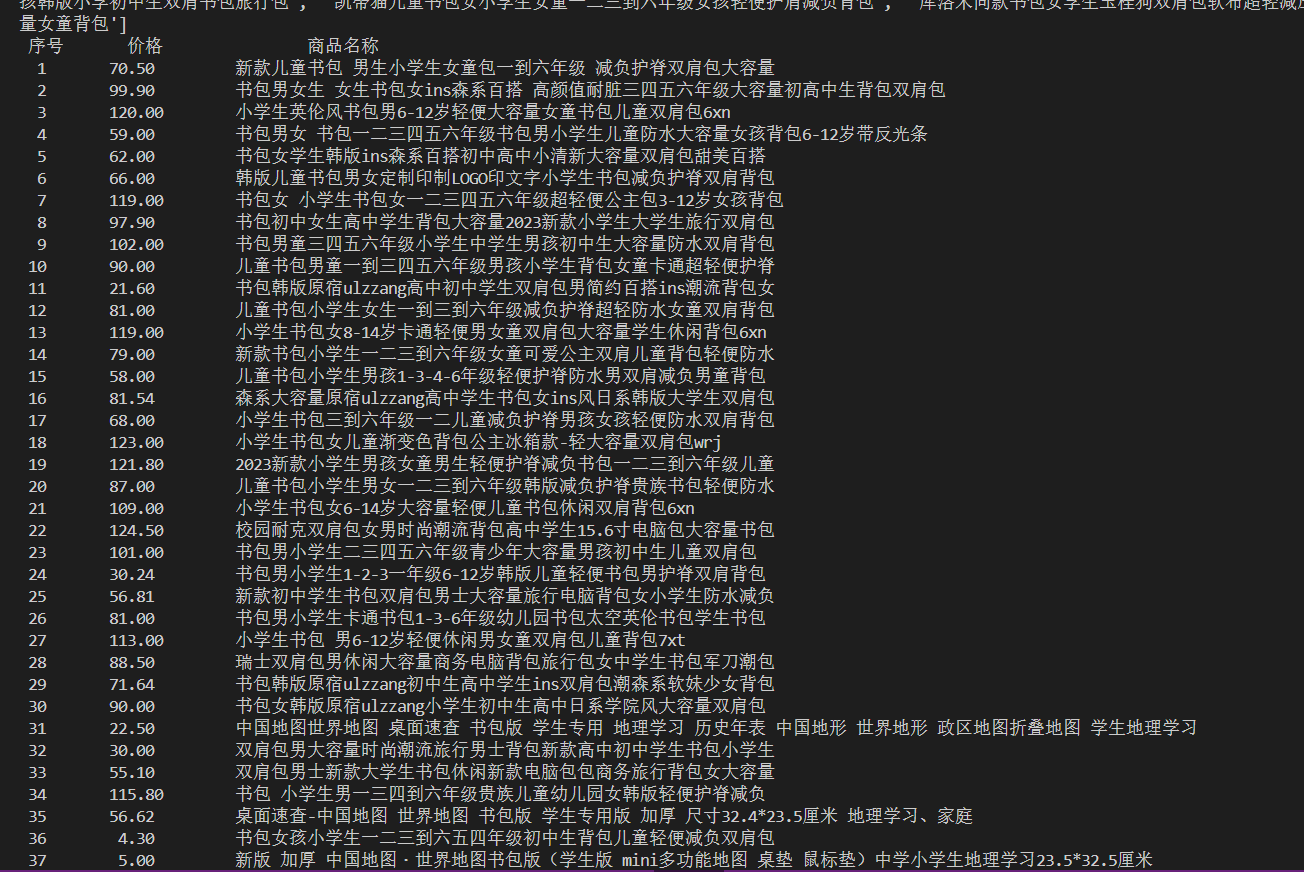
作业结果
运行代码后,我们可以得到清晰的商品信息列表,包括序号、价格和商品名称。以下是部分结果的截图:

作业心得
通过这个项目,我在爬虫技术方面有了更深入的学习和实践。
- 对网页 HTML 结构有了更细致的了解,能够根据实际需求定位到关键的信息节点。在这个作业中,通过分析商品页面的 HTML 代码,找到了包含商品名称和价格的标签及属性,从而准确地提取出了所需数据。
- 进一步掌握了正则表达式的使用技巧。正则表达式是强大的数据提取工具,但也需要对其语法和模式有深入的理解。在这个作业中,通过编写合适的正则表达式,成功地从复杂的 HTML 文本中提取出了价格和商品名称,并且学会了如何处理数据中的特殊字符(如去掉价格中的逗号),以满足数据处理的要求。
- 同时,我也深刻认识到在网络爬虫过程中需要遵守网站的使用条款和法律法规,确保我们的行为是合法合规的。合理的爬虫行为不仅可以保护网站的正常运行,也有利于我们长期获取有价值的数据。
作业③:下载网页中的所有 JPEG 和 JPG 文件
任务概述
在这一作业中,我们需要从指定网页中下载所有的 JPEG 和 JPG 图片文件。这涉及到对网页内容的解析、图片链接的提取以及文件的下载和存储操作,是对我们综合运用网络爬虫和文件操作知识的考验。
代码实现
以下是实现下载网页图片功能的代码:
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
# 设置目标网页URL
url = "https://news.fzu.edu.cn/yxfd.htm"
# 设置保存图片的文件夹
folder_name = "images"
# 创建文件夹(如果不存在)
if not os.path.exists(folder_name):
os.makedirs(folder_name)
# 发送请求获取网页内容
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有的图像标签
img_tags = soup.find_all('img')
for img in img_tags:
img_url = img.get('src')
# 确保img_url是完整的URL
if img_url:
img_url = urljoin(url, img_url)
# 检查文件扩展名
if img_url.lower().endswith(('.jpg', '.jpeg')):
# 获取图片的文件名
img_name = os.path.join(folder_name, os.path.basename(img_url))
# 下载并保存图片
img_data = requests.get(img_url).content
with open(img_name, 'wb') as handler:
handler.write(img_data)
print(f"下载了: {img_name}")
else:
print("网页请求失败,状态码:", response.status_code)
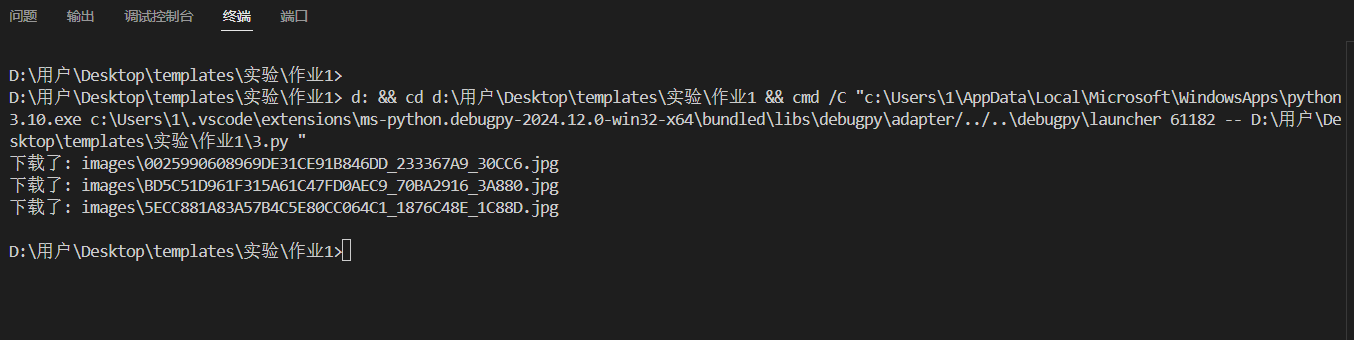
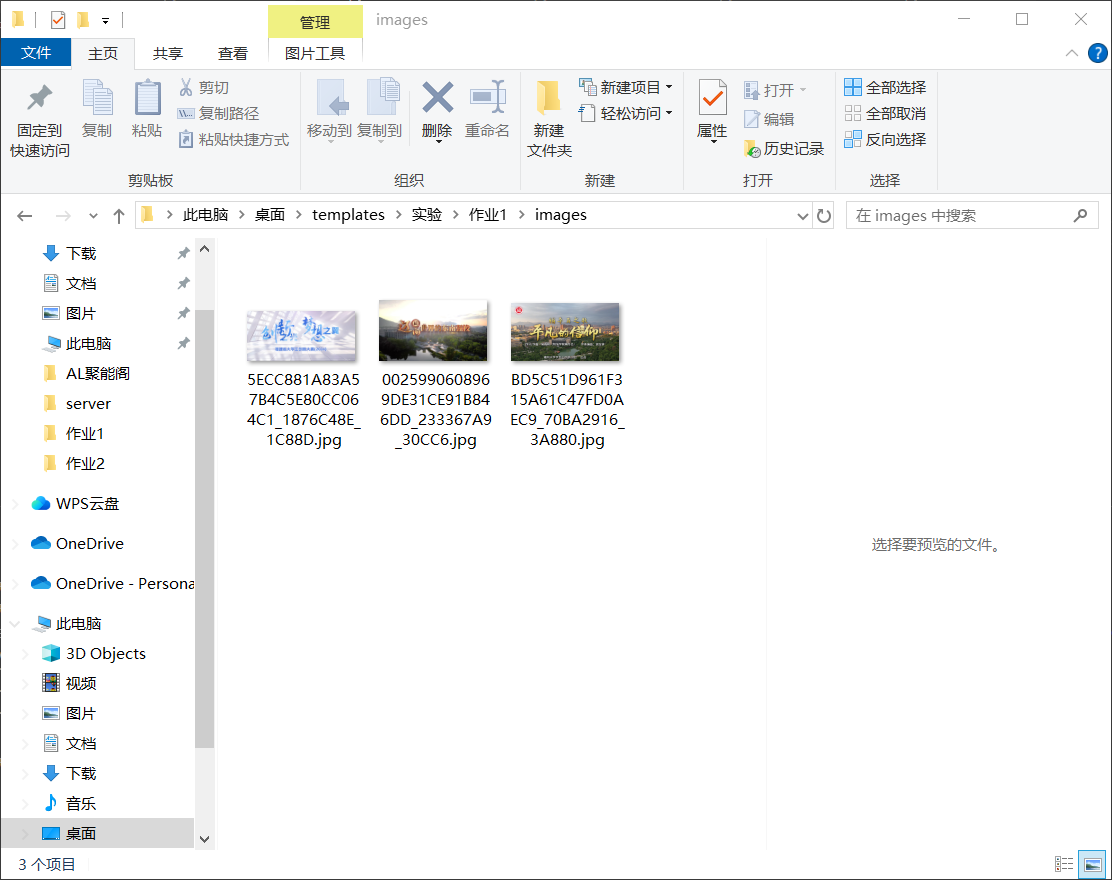
作业结果
通过运行上述代码,我们成功地从指定网页下载了所有符合条件的图片,并将它们保存到了本地的 images 文件夹中。以下是部分下载结果的截图:
作业心得
完成这个作业让我对文件操作和数据存储有了更深入的理解和实践经验。
- 学会了如何使用
os库在本地创建文件夹,为文件的存储做好准备。这是文件管理的基础操作,确保了我们能够将下载的图片有序地保存到指定位置。 - 掌握了如何从网页中提取图片链接,并将其转换为完整的 URL。通过
urljoin函数,我们可以根据网页的基础 URL 和图片的相对路径,构建出完整的图片下载地址,确保能够准确地获取到图片资源。 - 在文件下载和保存方面,我学会了如何使用
requests库获取图片的二进制数据,并将其写入到本地文件中。通过with open语句,我们可以安全地打开和关闭文件,确保数据的正确写入和文件资源的合理管理。 - 这个作业让我更加深入地理解了数据在网络和本地之间的传输和存储过程,提高了我对数据管理的实际操作能力。
总结与反思
通过这三个作业的实践,我对 Python 爬虫技术有了全面而系统的认识和掌握。这些作业不仅提升了我的编程能力,还让我体验到了从数据获取到处理的整个流程,激发了我对数据采集与融合技术的浓厚兴趣。
在完成作业的过程中,我也遇到了一些问题和挑战。例如,在解析网页结构时,不同网站的布局和标签结构各不相同,需要仔细分析和调试才能准确提取数据;在使用正则表达式时,需要不断优化表达式的模式,以确保能够准确匹配所需的信息;在处理网络请求和文件操作时,也需要考虑到各种异常情况,如网络连接中断、文件权限问题等。
然而,通过不断地尝试和学习,我逐渐克服了这些问题,并且在解决问题的过程中积累了宝贵的经验。这些经验将对我今后的学习和实践产生积极的影响,让我能够更加自信地应对各种数据采集和处理任务。
未来,我希望能够进一步深入研究爬虫的高级技术,如动态网页爬取、分布式爬虫等,以及更深入地学习数据分析方法,将采集到的数据进行更有价值的分析和利用。我相信,通过不断地学习和实践,我能够在数据采集与融合技术领域取得更大的进步。
感谢您的阅读,希望我的经验分享能够对您有所帮助,也期待与大家在学习和探索的道路上共同进步!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)