软件杯-视频全量目标分析和建模需求分析说明
开发环境:
- 华为云 AI开发平台ModelArts
开发语言:
- python3.7
深度学习框架:
- TensorFlow1.x
数据集:
- 参考cityscapes-image-pairs等

预计初步实现:
简单来说 提取视频的帧 然后处理 在合成
我们感觉原视频和分割后的视频放一起比较好,但是抽帧分割再合成后的视频和原视频对不上
感觉视频分割方面还得改,但是还没想好咋弄?
提取每帧:
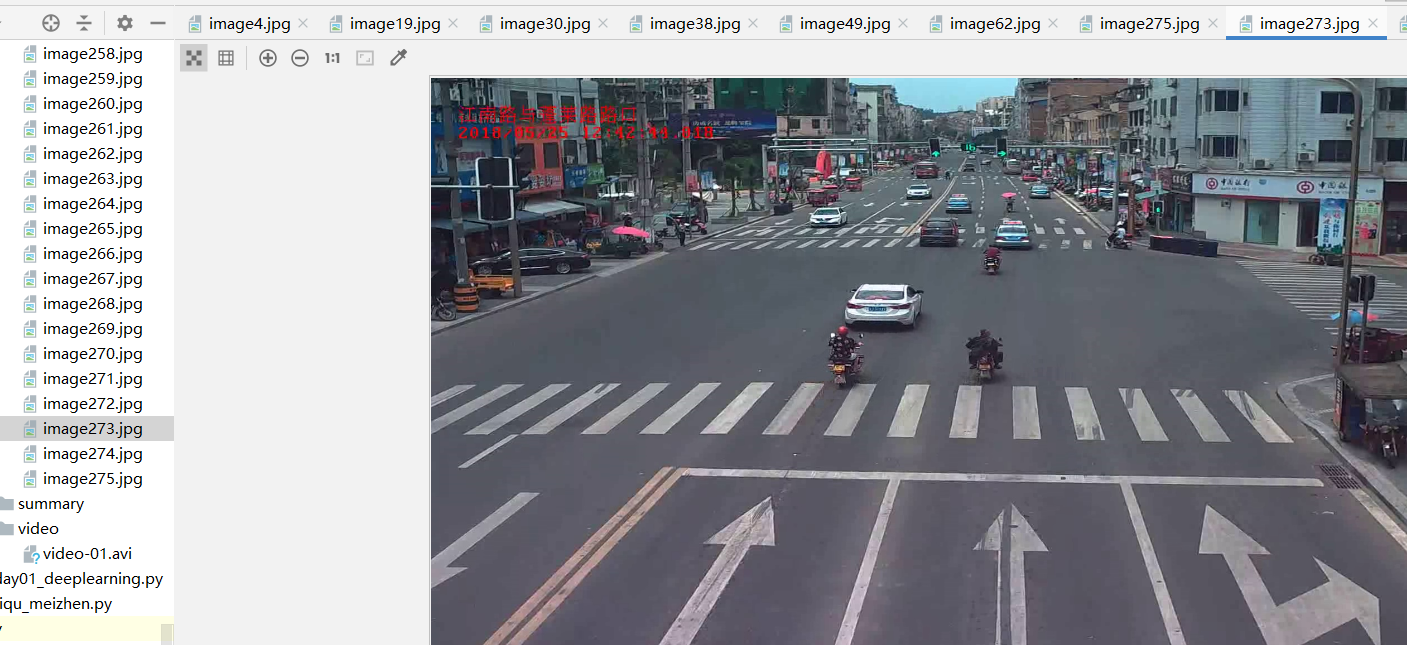
初步效果:

功能需求:利用视觉分析技术对高分辨率视频进行目标检测和语义分割
具体:
基本要求:
- 分类和定位。针对10分钟1080P视频内容进行移动目标识别(包括人、机动车、非机动车、建筑、植物等5种以上)
- 语义分割。实现对高清视频图像语义分割(对每帧的每个点的类别预测)
- 重点实现对建筑物等固定目标的识别和分割
进阶需求:
- 实现移动目标10种以上(其中建筑物必须识别)
- 实现实例分割
- 性能优化,创新深度学习算法模型
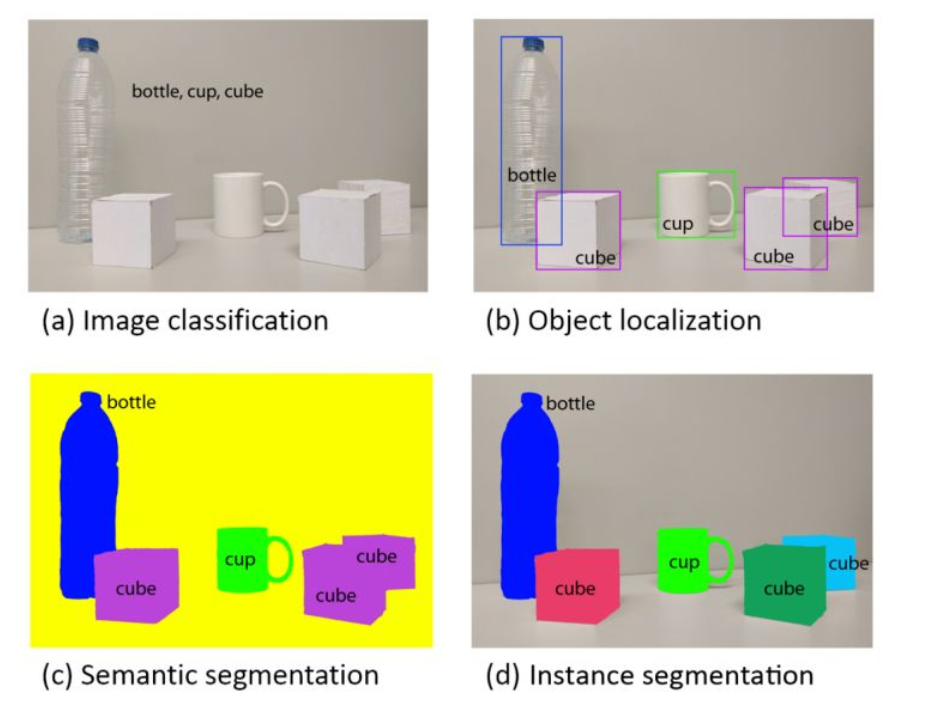
计算机视觉四大步骤:(分类、定位、检测、分割)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号