暑假周进度报告(三)-------版本过高后续问题处理,eclipse编译运行MapReduce以及Hadoop学习
问题一:Hadoop版本太高
卸载Hadoop3.2.0 我改安装了Hadoop 2.7.7
如果没有权限下载。可以采用如下方式:
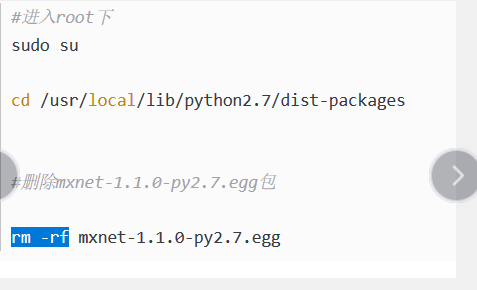
卸载完成以后返回原目录即可
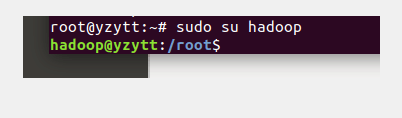
后面的jdk卸载也可以采用这种方式。
按照教程重新安装http://dblab.xmu.edu.cn/blog/install-hadoop/
由于后期需要安装HBASE 所以Hadoop安装版本选择问题参考如下:

然后
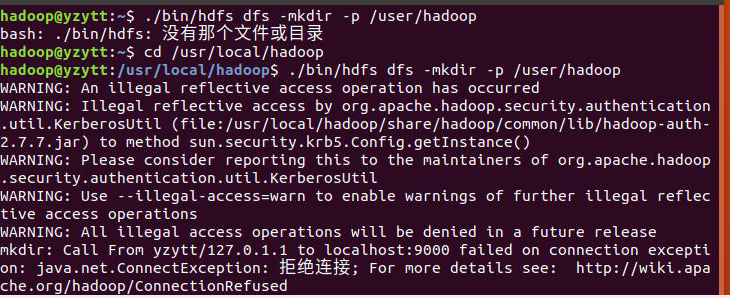
执行这一步时或者某些会出现各种警告,这个是由于之前安装的jdk版本过高造成的 卸载jdk 改安装jdk1.8.0
问题二:jdk版本过高
按照上述方式,卸载jdk
然后配置环境变量
然后可能会出现JAVA_HOME is not set and could not be found 类似于这种java_home找不到这种错误,或者找不到default-java等修改一下hadoop-env.sh文件改一下jdk路径即可,参考:https://blog.csdn.net/dianzishijian/article/details/52094569
运行MapReduce 项目实例的时候 可能会出现
Unable to load native-hadoop library for your platform
解决参考教程:https://blog.csdn.net/jack85986370/article/details/51902871
启动Hadoop:./sbin/start-dfs.sh
关闭Hadoop:./sbin/stop-dfs.sh
运行 Hadoop 程序时,为了防止覆盖结果,程序指定的输出目录(如 output)不能存在,否则会提示错误,因此运行前需要先删除输出目录。
./bin/hdfs dfs -rm -r output # 删除 output 文件夹
或者添加如下代码 在程序中(能在每次运行时自动删除输出目录,避免繁琐的命令行操作)
- Configuration conf = new Configuration();
- Job job = new Job(conf);
- /* 删除输出目录 */
- Path outputPath = new Path(args[1]);
- outputPath.getFileSystem(conf).delete(outputPath, true);
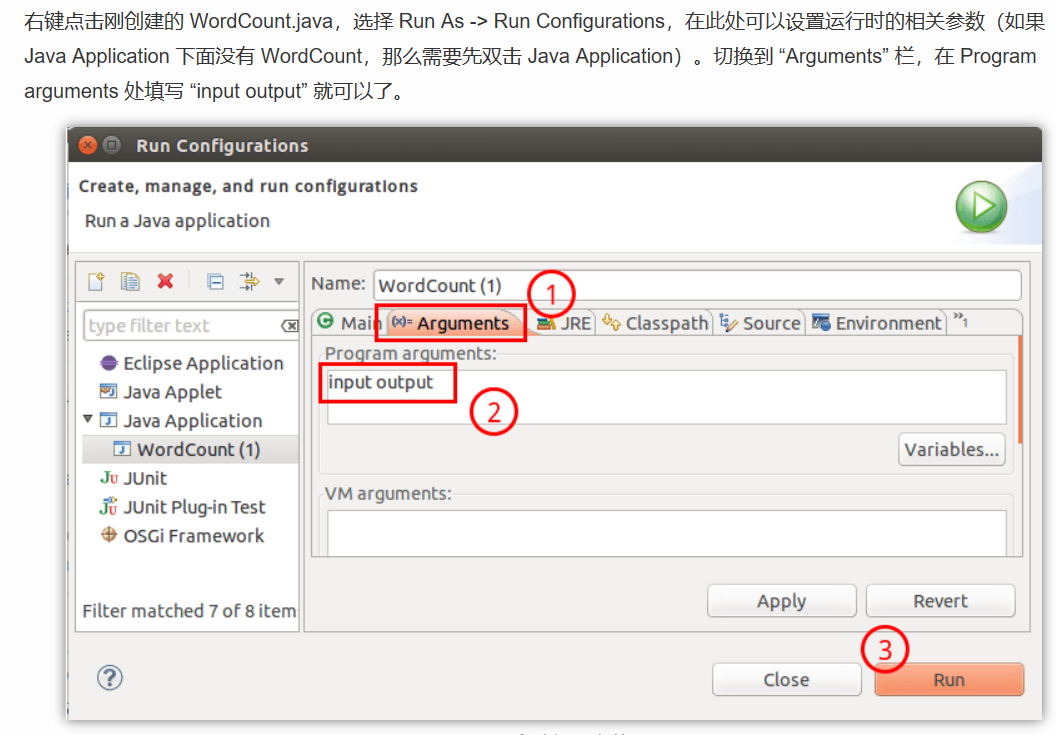

- // String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
- String[] otherArgs=new String[]{"input","output"}; /* 直接设置输入参数 */
分布式文件系统HDFS:
1.为了解决海量数据的分布式存储的问题
2.满足大规模数据的批量处理需求,不会去访问一块一块儿的数据
3.实时性不高
4.不支持多用户写入及任意修改文件,只允许追加数据,不允许修改
HDFS相关概念
1.块:HDFS的一个快要比普通的一个快大很多(支持面向大规模数据存储,降低分布式节点的寻址开销)-------->支持大规模文件存储,简化系统设计,适合数据备份
2.名称节点(主节点,记录数据库存储位置信息,数据目录),数据节点(存储实际数据,每个数据节点上的数据是被保存到数据节点本地的Linux文件系统中去)----->两大组件
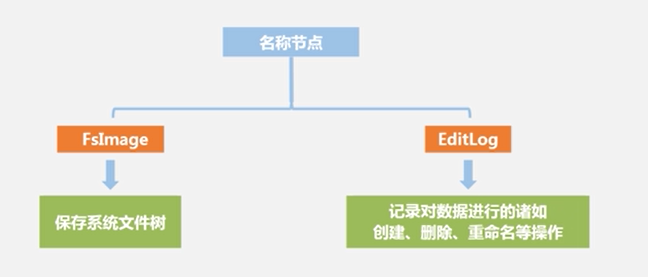
注意,在FsImage文件中是没有具体记录块在哪个数据节点存储的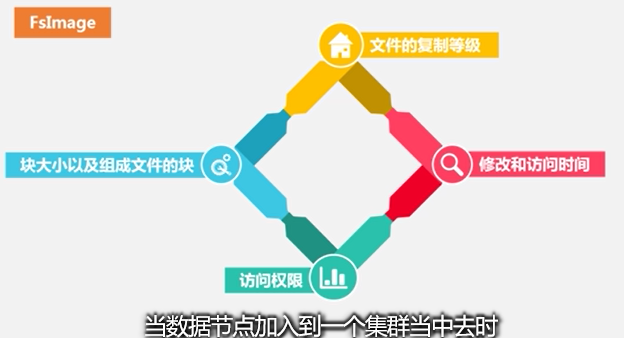
HDFS启动:先从底层读出FsImage,再读出EditLog,然后它们在内存中进行合并操作,合并后得到一个新的FsImage,删掉旧的FsImage,再生成一个新的EditLog,系统开始运行
第二名称节点:1.名称节点的冷备份,2.对EditLog的处理(帮助解决EditLog不断增大的问题)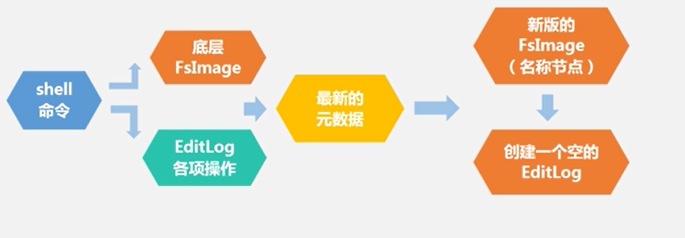

 浙公网安备 33010602011771号
浙公网安备 33010602011771号