
线程
目录
-
消息队列
-
IPC机制
-
生产者消费者类型
-
线程理论
-
开设线程的两种方式
-
线程实现TCP并发
-
线程join方法
-
线程下数据共享
-
线程对象书写和方法
-
守护线程
-
GIL全局解释器锁
内容
消息队列
队列:先进先出;堆栈:先进后出
以后我们会直接使别人封装好的消息队列,实现各种数据传输


from multiprocessing import Queue q = Queue(5) # 自定义队列存放的长度 # 往队列中存放数据 q.put(111) q.put(222) q.put(333) print(q.full()) # False 判断当前队列是否满了 q.put(444) q.put(555) print(q.full()) # True # q.put(666) # 超出最大长度,程序会原地阻塞,等待出现空位 print(q.get()) print(q.get()) print(q.get()) print(q.empty()) # False 判断队列是否已经空了 print(q.get()) print(q.get()) print(q.empty()) # True print(q.get()) # 队列中没有值,继续获取会阻塞,等待队列中给值 print(q.get_nowait()) # 队列中如果没有值,直接报错
上述方法能否在并发的场景下精准使用?
不能;多个进程处理并发无法保证队列里面的数据
IPC机制(进程间通信)
- 主进程与子进程数据交互
- 两个子进程数据交互
本质:不同内存空间中的进程数据交互
1.主进程与子进程交互
from multiprocessing import Process,Queue def producer(q): print('子进程producer从队列中取值>>>:',q.get()) if __name__ == '__main__': q = Queue() p = Process(target=producer,args=(q,)) # 将主进程中生成的q放到子进程中 p.start() print('主进程')
这个程序是永远无法结束;因为q.get()没有值,子进程一直在等待,主进程也要等待
from multiprocessing import Process,Queue def producer(q): print('子进程producer从队列中取值>>>:',q.get()) if __name__ == '__main__': q = Queue() p = Process(target=producer,args=(q,)) # 将主进程中生成的q放到子进程中 p.start() q.put(123) # 主进程往队列中存放数据123 print('主进程')
结果为:
主进程
子进程producer从队列中取值>>>: 123
2.两个子进程数据交互
from multiprocessing import Process,Queue def producer(q): # print('子进程producer从队列中取值>>>:',q.get()) q.put('子进程producer往队列中添加值') def consumer(q): print('子进程consumer从队列中取值>>>:',q.get()) if __name__ == '__main__': q = Queue() p = Process(target=producer,args=(q,)) # 将主进程中生成的q放到子进程中 p1 = Process(target=consumer,args=(q,)) p.start() p1.start() # q.put(123) # 主进程往队列中存放数据123 print('主进程')
结果为:
主进程
子进程consumer从队列中取值>>>: 子进程producer往队列中添加值
这样就实现了数据交互,那再基于网络就再封装了socket代码
生产者消费者模型
生产者:负责生产/制造数据;消费者:负责消费/处理数据
比如在爬虫领域中:
会先通过代码爬取网页数据(爬取网页的代码就可以称之为是生产者)
之后针对网页数据做筛选处理(处理网页的代码就可以称之为消费者)
如果使用进程来展示:
除了有至少两个进程之外,还需要一个媒介(消息队列)
以后遇到该模型需要考虑的问题其实就是供需平衡的问题;生产力与消费力要均衡
from multiprocessing import Process,Queue,JoinableQueue import time import random def producer(name,food,q): for i in range(10): data = f'{name}生产了{food}{i+1}' print(data) time.sleep(random.randint(1,3)) q.put(data) def consumer(name,q): while True: food = q.get() # 这里会卡住 # if food == None: # print('要饿死了') # break time.sleep(random.random()) print(f'{name}吃了{food}') q.task_done() # 每次取完数据必须给队列一个反馈 if __name__ == '__main__': # q = Queue() q = JoinableQueue() p1 = Process(target=producer,args=('大厨zhou','蛋炒饭',q)) p2 = Process(target=producer,args=('学徒chen','神仙汤',q)) c1 = Process(target=consumer,args=('wu',q)) c2 = Process(target=consumer,args=('jin',q)) c1.daemon = True # 将消费者设置成守护进程 c2.daemon = True p1.start() p2.start() c1.start() c2.start() """生产者生产完所有数据之后,往队列中添加结束的信号""" p1.join() p2.join() # q.put(None) # q.put(None) # 结束信号的个数要跟消费者个数一致才可以 """队列中其实已经自己加了锁,所以多进程取值也不会冲突,并且取走了就没了""" q.join() # 等待队列中数据全部被取出(一定要让生产者全部结束才能判断正确) """到这里表示消费者也已经消费完数据了"""
线程理论
进程:资源单位;线程:执行单位;也就是之前所讲的主进程
进程相当于车间(一个个空间);线程相当于车间里面的流水线(真正干活的额)
进程仅仅是在内存中开辟一块空间;线程是真正被CPU执行的,指的就是代码的执行过程
开设线程的原因:开设线程的消耗远远小于进程
开设进程:1.申请内存空间;2.拷贝代码
开设线程:一个进程内可以开设多个线程,无需申请内存空间
开设线程的两种方式
第一种方式:函数
from threading import Thread import time def task(name): print(f'{name} is running') time.sleep(3) print(f'{name} is over') if __name__ == '__main__': t = Thread(target=task,args=('zhou', )) t.start() # 创建线程的开销极小,几乎一瞬间就可以创建 print('主线程')
第二种方式:面向对象
from threading import Thread import time class MyThread(Thread): def __init__(self,name): super().__init__() self.name = name def run(self): print(f'{self.name} zhou is running') time.sleep(3) print(f'{self.name} is over') if __name__ == '__main__': t = MyThread('zhou') t.start() print('主线程')
线程实现TCP服务端的开发
服务端:
import socket from threading import Thread server = socket.socket() server.bind(('127.0.0.1',9999)) server.listen() def talk(sock): while True: data = sock.recv(1024) print(data.decode('utf8')) sock.send(data.upper()) while True: sock,add = server.accept() # 每来一个客户端就创建一个线程做数据交互 t = Thread(target=talk,args=(sock,)) t.start()
客户端:
import socket client = socket.socket() client.connect(('127.0.0.1',9999)) while True: client.send(b'hello') data = client.recv(1024) print(data.decode('utf8'))
线程join方法
from threading import Thread import time def task(name): print(f'{name} is running') time.sleep(3) print(f'{name} is over') t = Thread(target=task,args=('zhou',)) t.start() print('主线程')
结果为:
zhou is running
主线程
zhou is over
from threading import Thread import time def task(name): print(f'{name} is running') time.sleep(3) print(f'{name} is over') t = Thread(target=task,args=('zhou',)) t.start() t.join() print('主线程')
结果为:
zhou is running
zhou is over
主线程
join方法:主线程代码等待子线程代码运行完毕之后再往下执行
因为主线程结束也就标志着整个进程的结束,要确保子线程运行过程中所有的各项资源
同一个进程内的多个线程数据共享
from threading import Thread momey = 77777777 def task(): global money money = 1 t = Thread(target=task) t.start() t.join() print(money)
结果为:1
线程对象书写和方法
验证一个进程下的多个线程是否真的处于一个进程(获取进程号)
from threading import Thread import os def task(): print('子线程获取进程号>>>:',os.getpid()) if __name__ == '__main__': t = Thread(target=task) t.start() print('主线程获取进程号>>>:',os.getpid())
结果为:
子线程获取进程号>>>: 21092
主线程获取进程号>>>: 21092
统计当前进程下活跃的线程数:active_count()
from threading import Thread,active_count import os import time def task(): time.sleep(3) print('子线程获取进程号>>>:',os.getpid()) if __name__ == '__main__': t = Thread(target=task) t.start() print(active_count()) print('主线程获取进程号>>>:',os.getpid())
结果为:
2
主线程获取进程号>>>: 9912
子线程获取进程号>>>: 9912
这里如果不导入time模块,结果会是1,因为子线程获取进程号已经结束了
获取线程的名字
1.current_thread().name
from threading import Thread,active_count,current_thread import os import time def task(): time.sleep(3) print('子线程获取进程号>>>:',os.getpid()) print(current_thread().name) if __name__ == '__main__': t = Thread(target=task) t.start() t.join() print(active_count()) print(current_thread().name) print('主线程获取进程号>>>:',os.getpid())
结果为:
子线程获取进程号>>>: 20384
Thread-1
1
MainThread
主线程获取进程号>>>: 20384
2.self.name
from threading import Thread,active_count,current_thread import os import time class MyThread(Thread): def run(self): print(self.name) if __name__ == '__main__': t1 = MyThread() t2 = MyThread() t1.start() t2.start()
守护线程
from threading import Thread import time def task(name): print(f'{name} is running') time.sleep(3) print(f'{name} is over') if __name__ == '__main__': t1 = Thread(target=task,args=('zhou',)) t2 = Thread(target=task,args=('chen',)) t1.daemon = True t1.start() t2.start() print('主线程')
结果为:
zhou is running
chen is running
主线程
chen is over
zhou is over
如果守护线程还有非守护线程,主线程要等待所有非守护线程结束才可以结束
练习题:
无守护线程:
from threading import Thread import time def foo(): print(123) time.sleep(1) print('end123') def bar(): print(456) time.sleep(3) print('end456') if __name__ == '__main__': t1 = Thread(target=foo) t2 = Thread(target=bar) t1.start() t2.start() print('主线程')
结果为:
123
456
主线程
end123
end456
有守护线程:t1.daemon = True
123
456
主线程
end123
end456
有守护线程:t2.daemon = True
123
456
主线程
end123
GIL全局解释器锁
这是一个纯理论,不影响编程,面试可能会被问到
官方文档:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
python解释器类别:Cpython(底层是C);Jpytho(底层是JAVA);Ppython(底层是python)
GIL只存在于Cpython解释器中,不是python的特征,是python解释器的特征
GIL全称:global interpreter lock
GIL是一把互斥锁(将并发变成串行),用于阻止同一个进程下的多个线程同时执行即不能利用多核优势;原因在于Cpython解释器中的垃圾回收机制不是线程安全的
复习一下垃圾回收机制(线程):应用计数,标记清除,分代回收
这里很多不懂python的程序员会喷python是垃圾,速度太慢,有多核都不能用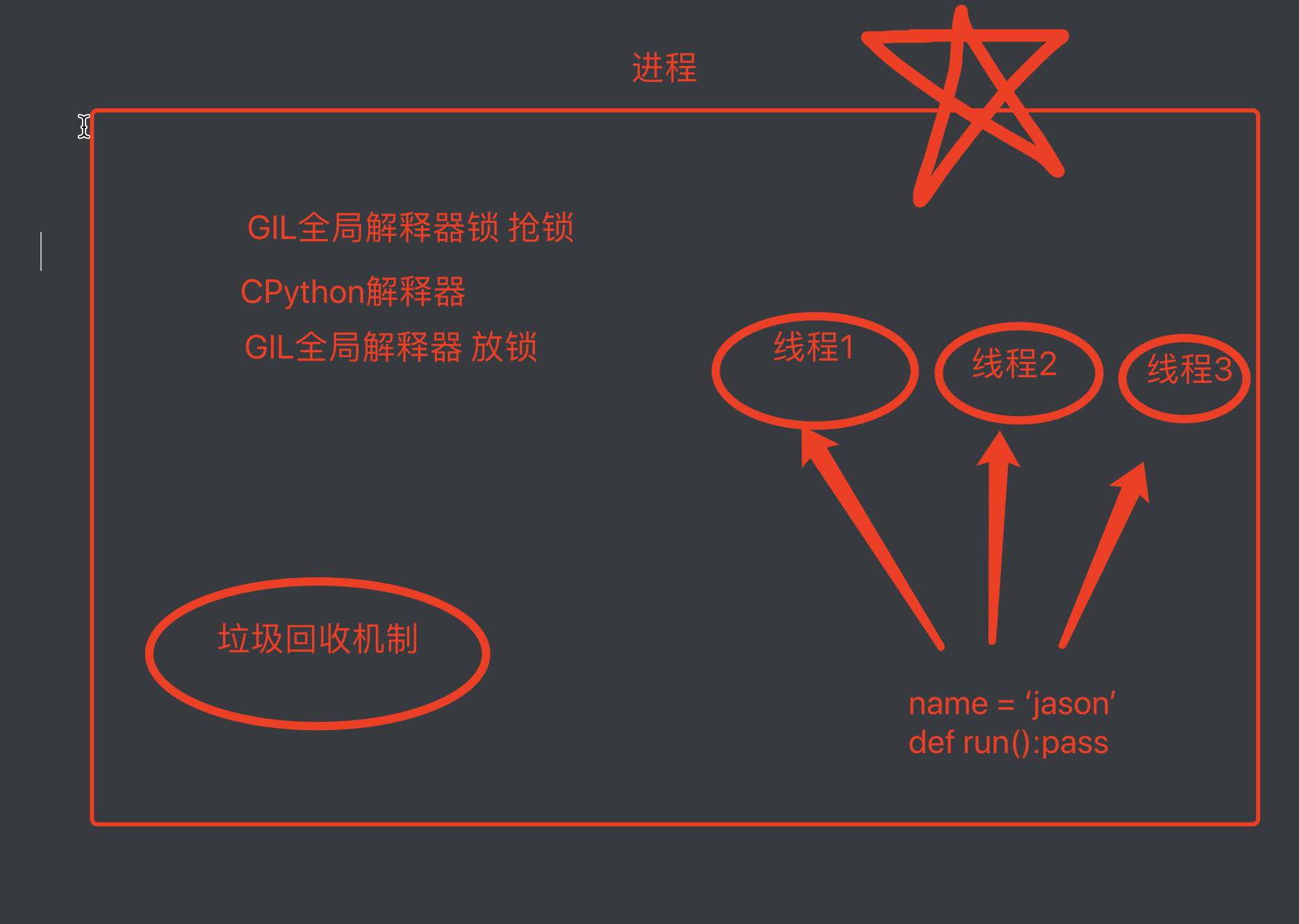
反怼:虽然用一个进程下的多个线程不能利用多核优势,但是还可以开设多进程
反向验证GIL的存在:如果不存在会产生垃圾回收机制与正常线程之间数据错乱
GIL是加在CPython解释器上面的互斥锁,同一个进程下的多个线程要想执行必须先抢GIL锁,所以同一个进程下多个线程肯定不能同时运行,即无法利用多核优势
要结合实际情况:
如果多个任务都是IO密集型的,那么多线程更有优势(消耗的资源更少): 多道技术:切换+保存状态
如果多个任务都是计算密集型,那么多线程确实没有优势,但是可以用多进程
以后用python就可以多进程下面开设多线程从而达到效率最大化
- 所有的解释型语言都无法做到同一个进程下多个线程利用多核优势
- GIL在实际编程中其实不用考虑
