
12.20
实验7
Spark初级编程实践
1.实验目的
(1)掌握使用Spark访问本地文件和HDFS文件的方法
(2)掌握Spark应用程序的编写、编译和运行方法
2.实验平台
(1)操作系统:Ubuntu18.04(或Ubuntu16.04);
(2)Spark版本:2.4.0;
(3)Hadoop版本:3.1.3。
3.实验步骤
(1)Spark读取文件系统的数据
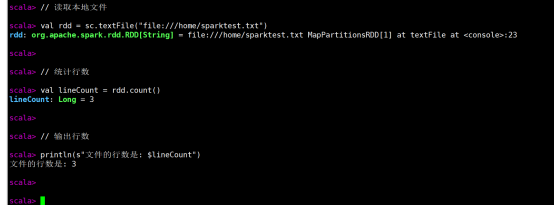
(1)在spark-shell中读取Linux系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数;
命令:
// 读取本地文件
val rdd = sc.textFile("file:///home/sparktest.txt")
// 统计行数
val lineCount = rdd.count()
// 输出行数
println(s"文件的行数是: $lineCount")
运行结果:
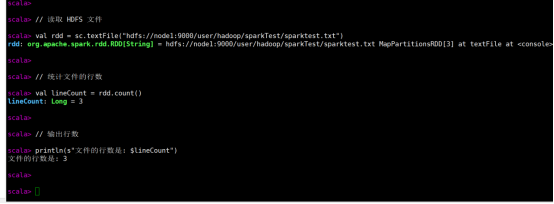
(2)在spark-shell中读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;
代码:
// 读取 HDFS 文件
val rdd = sc.textFile("hdfs://node1:9000/user/hadoop/sparkTest/sparktest.txt")
// 统计文件的行数
val lineCount = rdd.count()
// 输出行数
println(s"文件的行数是: $lineCount")
运行结果:
(3)编写独立应用程序(推荐使用Scala语言),读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;通过sbt工具将整个应用程序编译打包成 JAR包,并将生成的JAR包通过 spark-submit 提交到 Spark 中运行命令。
代码:
import org.apache.spark.sql.SparkSession
object HdfsLineCount {
def main(args: Array[String]): Unit = {
// 创建 SparkSession
val spark = SparkSession.builder
.appName("HDFS Line Count")
.getOrCreate()
// 读取 HDFS 上的文件
val filePath = "hdfs://node1:9000/user/hadoop/sparkTest/sparktest.txt" // 根据实际配置调整
val rdd = spark.sparkContext.textFile(filePath)
// 统计文件的行数
val lineCount = rdd.count()
// 打印输出文件的行数
println(s"文件的行数是: $lineCount")
// 停止 Spark 会话
spark.stop()
}
}
通过 spark-submit 提交作业:
命令:
spark-submit \
--class HdfsLineCount \
--master yarn \
target/scala-2.12/hdfslinecount_2.12-0.1.jar
运行结果:

(2)编写独立应用程序实现数据去重
对于两个输入文件A和B,编写Spark独立应用程序(推荐使用Scala语言),对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。下面是输入文件和输出文件的一个样例,供参考。
输入文件A的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件B的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件A和B合并得到的输出文件C的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
代码:
package bigdata2
import org.apache.spark.sql.SparkSession
object MergeAndRemoveDuplicates {
def main(args: Array[String]): Unit = {
// 创建Spark会话
val spark = SparkSession.builder()
.appName("MergeAndRemoveDuplicates")
.master("local[*]") // 本地运行,适当修改为集群配置
.getOrCreate()
// 读取输入文件A和B
val fileA = spark.read.text("/usr/lsx/fileA.txt")
val fileB = spark.read.text("/usr/lsx/fileB.txt")
// 合并两个文件
val combined = fileA.union(fileB)
// 去除重复内容
val unique = combined.distinct()
// 按行排序(可选)
val sorted = unique.orderBy("value")
// 将结果写入输出文件C
sorted.write.text("/usr/lsx/outputFileC.txt")
// 关闭Spark会话
spark.stop()
}
}
运行结果:

(3)编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
Algorithm成绩:
小明 92
小红 87
小新 82
小丽 90
Database成绩:
小明 95
小红 81
小新 89
小丽 85
Python成绩:
小明 82
小红 83
小新 94
小丽 91
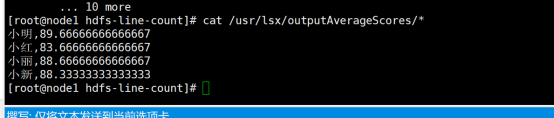
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
代码:
package bigdata3
import org.apache.spark.sql.{SparkSession, functions}
object CalculateAverageScore {
def main(args: Array[String]): Unit = {
// 创建Spark会话
val spark = SparkSession.builder()
.appName("CalculateAverageScore")
.master("local[*]") // 本地运行,适当修改为集群配置
.getOrCreate()
// 导入隐式转换,确保支持 Dataset 的隐式转换
import spark.implicits._
// 读取输入文件(假设三个学科成绩文件)
val algorithmFile = spark.read.text("/usr/lsx/Algorithm.txt")
val databaseFile = spark.read.text("/usr/lsx/Database.txt")
val pythonFile = spark.read.text("/usr/lsx/Python.txt")
// 将每个文件的数据转为(key, value)形式,key为学生名字,value为成绩
val algorithmScores = algorithmFile.map(line => {
val fields = line.getString(0).split(" ")
(fields(0), fields(1).toDouble)
}).toDF("student", "score")
val databaseScores = databaseFile.map(line => {
val fields = line.getString(0).split(" ")
(fields(0), fields(1).toDouble)
}).toDF("student", "score")
val pythonScores = pythonFile.map(line => {
val fields = line.getString(0).split(" ")
(fields(0), fields(1).toDouble)
}).toDF("student", "score")
// 合并三个学科的成绩
val allScores = algorithmScores.union(databaseScores).union(pythonScores)
// 按学生名字分组,并计算每个学生的平均成绩
val averageScores = allScores.groupBy("student")
.agg(functions.avg("score").alias("average_score"))
// 输出结果到新文件
averageScores.write.format("csv").save("/usr/lsx/outputAverageScores")
// 关闭Spark会话
spark.stop()
}
}
运行结果:
4.实验报告
|
题目: |
Spark初级编程实践 |
姓名 |
陈庆振 |
日期 12.16 |
|
实验环境:(1)操作系统:Linux (2)Spark版本:1.6.3; (3)Hadoop版本:2.7.3。
|
||||
|
实验内容与完成情况:掌握使用Spark访问本地文件和HDFS文件的方法,并成功读取文件统计行数。 掌握Spark应用程序的编写、编译和运行方法,包括读取HDFS文件、数据去重和求平均值问题。 |
||||
|
出现的问题:在读取HDFS文件时,由于HDFS配置问题导致文件无法读取,通过检查Hadoop配置和网络设置后解决。 在编写独立应用程序时,由于对Scala语言和Spark API不熟悉,导致程序编译错误,通过查阅文档和学习相关教程后解决。 在数据去重实验中,由于对Spark的distinct()操作理解不足,导致去重结果不完全正确,通过深入理解Spark的去重机制后解决。 在求平均值问题中,由于对Spark的聚合操作不熟悉,导致平均值计算错误,通过学习Spark的聚合函数后解决。 |
||||
|
解决方案(列出遇到的问题和解决办法,列出没有解决的问题):问题1:HDFS文件无法读取。解决办法:检查Hadoop配置文件,确保HDFS地址和端口配置正确。 问题2:程序编译错误。解决办法:学习Scala语言基础和Spark API文档,根据错误提示修改代码。 问题3:去重结果不完全正确。解决办法:深入理解Spark的distinct()操作,确保去重逻辑正确。 问题4:平均值计算错误。解决办法:学习Spark的聚合函数,如groupBy和agg,确保平均值计算逻辑正确。 |
||||
