
12.19
实验6
熟悉Hive的基本操作
1.实验目的
(1)理解Hive作为数据仓库在Hadoop体系结构中的角色。
(2)熟练使用常用的HiveQL。
2.实验平台
操作系统:Ubuntu18.04(或Ubuntu16.04)。
Hadoop版本:3.1.3。
Hive版本:3.1.2。
JDK版本:1.8。
3.数据集
由《Hive编程指南》(O'Reilly系列,人民邮电出版社)提供,下载地址:
https://raw.githubusercontent.com/oreillymedia/programming_hive/master/prog-hive-1st-ed-data.zip
备用下载地址:
https://www.cocobolo.top/FileServer/prog-hive-1st-ed-data.zip
解压后可以得到本实验所需的stocks.csv和dividends.csv两个文件。
4.实验步骤
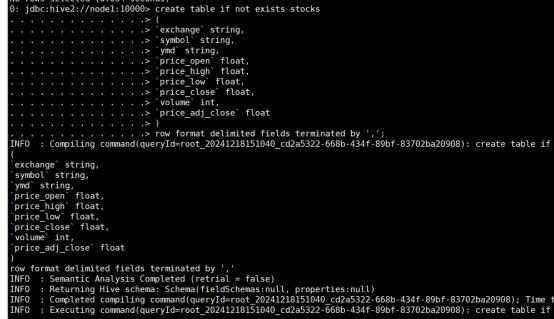
(1)创建一个内部表stocks,字段分隔符为英文逗号,表结构如表14-11所示。
表14-11 stocks表结构
|
col_name |
data_type |
|
exchange |
string |
|
symbol |
string |
|
ymd |
string |
|
price_open |
float |
|
price_high |
float |
|
price_low |
float |
|
price_close |
float |
|
volume |
int |
|
price_adj_close |
float |
命令:
create table if not exists stocks
(
`exchange` string,
`symbol` string,
`ymd` string,
`price_open` float,
`price_high` float,
`price_low` float,
`price_close` float,
`volume` int,
`price_adj_close` float
)
row format delimited fields terminated by ',';
运行结果:

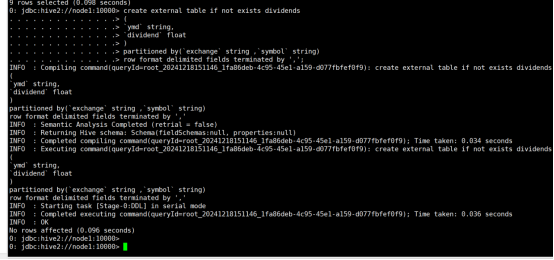
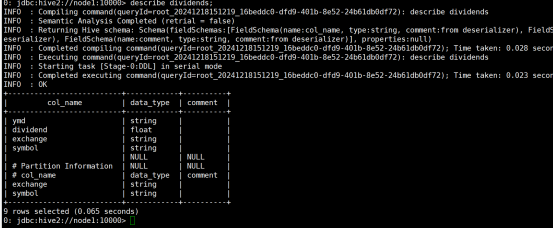
(2)创建一个外部分区表dividends(分区字段为exchange和symbol),字段分隔符为英文逗号,表结构如表14-12所示。
表14-12 dividends表结构
|
col_name |
data_type |
|
ymd |
string |
|
dividend |
float |
|
exchange |
string |
|
symbol |
string |
命令:
create external table if not exists dividends
(
`ymd` string,
`dividend` float
)
partitioned by(`exchange` string ,`symbol` string)
row format delimited fields terminated by ',';
运行结果:
(3)从stocks.csv文件向stocks表中导入数据。
命令:load data local inpath '/usr/local/hive/stocks.csv' overwrite into table stocks;
运行结果:

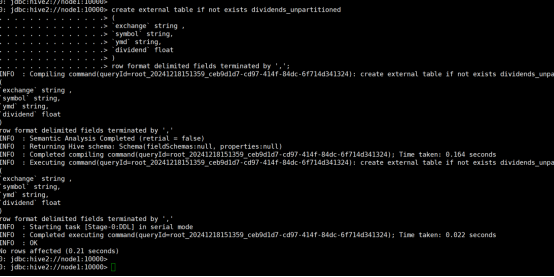
(4) 创建一个未分区的外部表dividends_unpartitioned,并从dividends.csv向其中导入数据,表结构如表14-13所示。
表14-13 dividends_unpartitioned表结构
|
col_name |
data_type |
|
ymd |
string |
|
dividend |
float |
|
exchange |
string |
|
symbol |
string |
命令:
create external table if not exists dividends_unpartitioned
(
`exchange` string ,
`symbol` string,
`ymd` string,
`dividend` float
)
row format delimited fields terminated by ',';(创建表)
load data local inpath '/usr/lsx/dividends.csv' overwrite into table dividends_unpartitioned;(导入数据)
运行结果:
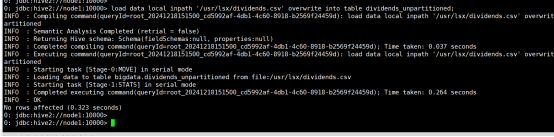
(5)通过对dividends_unpartitioned的查询语句,利用Hive自动分区特性向分区表dividends各个分区中插入对应数据。
命令:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=1000;
insert overwrite table dividends partition(`exchange`,`symbol`) select `ymd`,`dividend`,`exchange`,`symbol` from dividends_unpartitioned;
运行结果:
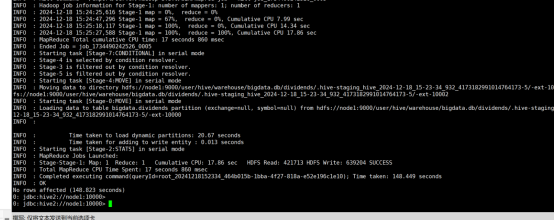
(6)查询IBM公司(symbol=IBM)从2000年起所有支付股息的交易日(dividends表中有对应记录)的收盘价(price_close)。
命令:
select s.ymd,s.symbol,s.price_close
from stocks s
LEFT SEMI JOIN
dividends d
ON s.ymd=d.ymd and s.symbol=d.symbol
where s.symbol='IBM' and year(ymd)>=2000;
运行结果:
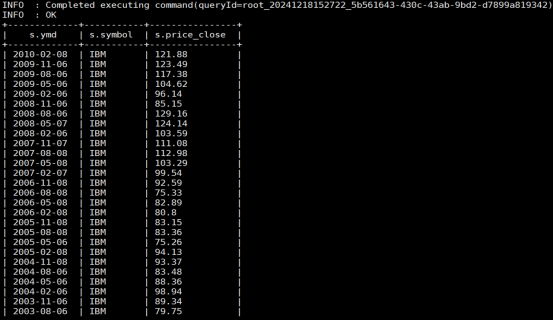
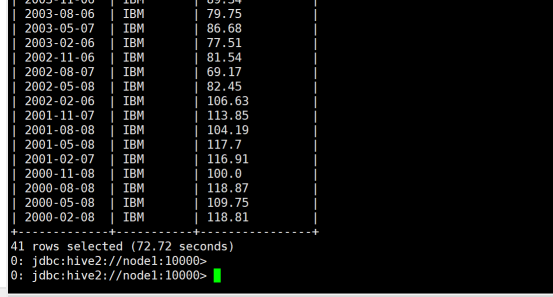
(7)查询苹果公司(symbol=AAPL)2008年10月每个交易日的涨跌情况,涨显示rise,跌显示fall,不变显示unchange。
命令:
select ymd,
case
when price_close-price_open>0 then 'rise'
when price_close-price_open<0 then 'fall'
else 'unchanged'
end as situation
from stocks
where symbol='AAPL' and substring(ymd,0,7)='2008-10';
运行结果:
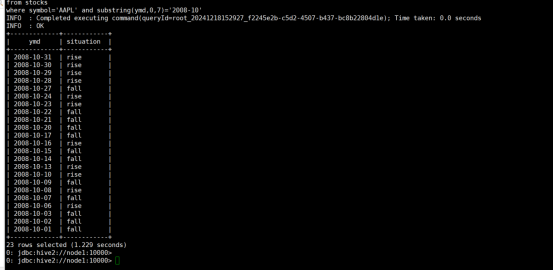
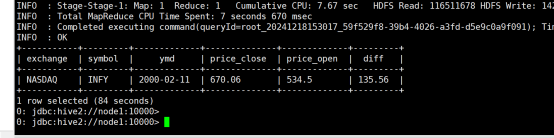
(8)查询stocks表中收盘价(price_close)比开盘价(price_open)高得最多的那条记录的交易所(exchange)、股票代码(symbol)、日期(ymd)、收盘价、开盘价及二者差价。
命令:
select `exchange`,`symbol`,`ymd`,price_close,price_open,price_close-price_open as `diff`
from
(
select *
from stocks
order by price_close-price_open desc
limit 1
)t;
运行结果:
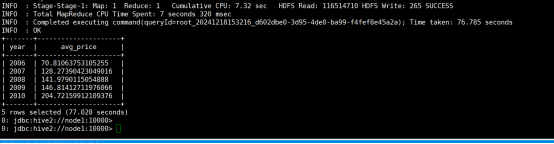
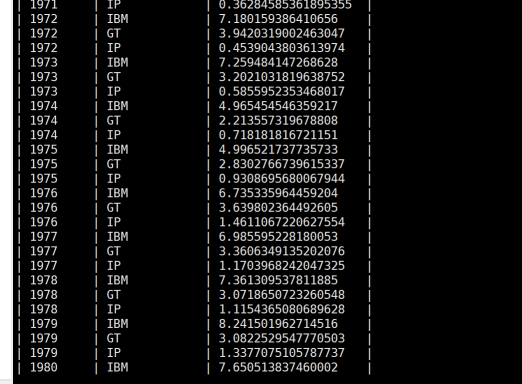
(9)从stocks表中查询苹果公司(symbol=AAPL)年平均调整后收盘价(price_adj_close) 大于50美元的年份及年平均调整后收盘价。
命令:
select
year(ymd) as `year`,
avg(price_adj_close) as avg_price from stocks
where `exchange`='NASDAQ' and symbol='AAPL'
group by year(ymd)
having avg_price > 50;
运行结果:
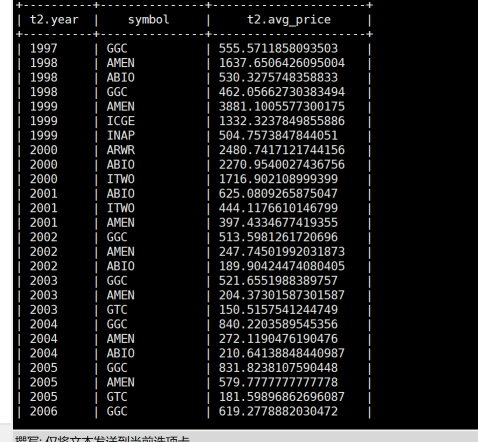
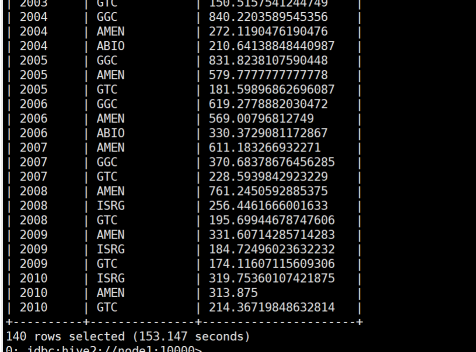
(10)查询每年年平均调整后收盘价(price_adj_close)前三名的公司的股票代码及年平均调整后收盘价。
命令:
select t2.`year`,symbol,t2.avg_price
from
(
select
*,row_number() over(partition by t1.`year` order by t1.avg_price desc) as `rank`
from
(
select
year(ymd) as `year`,
symbol,
avg(price_adj_close) as avg_price
from stocks
group by year(ymd),symbol
)t1
)t2
where t2.`rank`<=3;
运行结果:
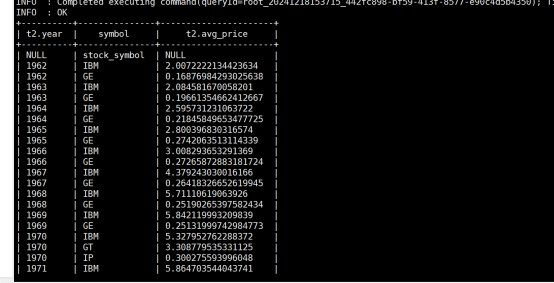
5.实验报告
|
题目: |
熟悉Hive的基本操作 |
姓名 |
陈庆振 |
日期:12.9 |
|
实验环境:Linux Hadoop版本:2.7.3。 Hive版本:1.2.1。 JDK版本:1.8。
|
||||
|
实验内容与完成情况:创建内部表stocks和外部分区表dividends,以及未分区的外部表dividends_unpartitioned,并成功导入数据。 利用Hive自动分区特性,将dividends_unpartitioned表中的数据插入到分区表dividends中。 查询IBM公司从2000年起所有支付股息的交易日的收盘价。 查询苹果公司2008年10月每个交易日的涨跌情况。 查询stocks表中收盘价比开盘价高得最多的记录。 查询苹果公司年平均调整后收盘价大于50美元的年份及年平均调整后收盘价。 查询每年年平均调整后收盘价前三名的公司的股票代码及年平均调整后收盘价。 |
||||
|
出现的问题:在导入数据时,由于路径问题导致无法找到文件,通过检查文件路径并确保Hive配置正确后解决。 在执行动态分区插入时,由于设置不当导致分区创建失败,通过调整hive.exec.dynamic.partition.mode为nonstrict并设置合适的hive.exec.max.dynamic.partitions.pernode值后解决。 在进行复杂查询时,由于对HiveQL的不熟悉导致查询语句编写错误,通过查阅文档和实践后逐渐掌握正确的查询语句编写方法。 |
||||
|
解决方案(列出遇到的问题和解决办法,列出没有解决的问题):问题1:数据导入失败。解决办法:检查文件路径,确保Hive的配置文件中指定的路径与实际文件路径一致。 问题2:动态分区创建失败。解决办法:调整Hive配置,设置hive.exec.dynamic.partition.mode为nonstrict,并适当增加hive.exec.max.dynamic.partitions.pernode的值。 问题3:复杂查询语句编写错误。解决办法:通过查阅HiveQL文档和实践,逐步掌握查询语句的编写,对于复杂的查询逻辑,可以通过分解查询步骤来逐步实现。 |
||||
