
12.16
实验3
熟悉常用的HBase操作
1.实验目的
(1)理解HBase在Hadoop体系结构中的角色;
(2)熟练使用HBase操作常用的Shell命令;
(3)熟悉HBase操作常用的Java API。
2.实验平台
(1)操作系统:Linux(建议Ubuntu16.04或Ubuntu18.04);
(2)Hadoop版本:3.1.3;
(3)HBase版本:2.2.2;
(4)JDK版本:1.8;
(5)Java IDE:Eclipse。
3. 实验步骤
(一)编程实现以下指定功能,并用Hadoop提供的HBase Shell命令完成相同任务:
(1) 列出HBase所有的表的相关信息,例如表名;
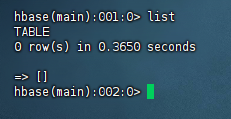
package org.example.three;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.conf.Configuration;
public class HBaseTableList {
public static void main(String[] args) {
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "master"); // HBase Zookeeper 地址
config.set("hbase.zookeeper.property.clientPort", "2181");
try {
System.out.println("Connecting to HBase...");
// 建立连接
try (org.apache.hadoop.hbase.client.Connection connection = org.apache.hadoop.hbase.client.ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin()) {
System.out.println("Connected to HBase...");
// 获取表信息
TableName[] tableNames = admin.listTableNames();
if (tableNames.length == 0) {
System.out.println("No tables found in HBase.");
} else {
for (TableName tableName : tableNames) {
System.out.println("表名: " + tableName.getNameAsString());
}
}
}
} catch (Exception e) {
System.err.println("Error connecting to HBase: " + e.getMessage());
e.printStackTrace();
}
}
}
(2) 在终端打印出指定的表的所有记录数据;
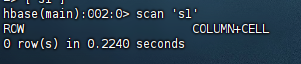
package org.example.three;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HBaseScanTable {
public static void main(String[] args) {
try {
// 配置HBase连接
org.apache.hadoop.conf.Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "master"); // 修改为HBase所在的Zookeeper的主机地址
config.set("hbase.zookeeper.property.clientPort", "2181");
// 建立连接
Connection connection = ConnectionFactory.createConnection(config);
Table table = connection.getTable(TableName.valueOf("s1")); // 修改为你要查看的表名
// 扫描整个表
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
for (Cell cell : result.listCells()) {
String row = Bytes.toString(cell.getRowArray(), cell.getRowOffset(), cell.getRowLength());
String value = Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());
System.out.println("Row: " + row + " => Value: " + value);
}
}
scanner.close();
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
(3) 向已经创建好的表添加和删除指定的列族或列;
添加数据

package org.example.three;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HBaseAddColumnFamily {
public static void main(String[] args) {
try {
// 配置HBase连接
org.apache.hadoop.conf.Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "master");
config.set("hbase.zookeeper.property.clientPort", "2181");
// 建立连接
Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin();
// 为表添加列族
TableName tableName = TableName.valueOf("s1"); // 修改为你的表名
HColumnDescriptor columnFamily = new HColumnDescriptor("phone"); // 新列族名称
admin.addColumnFamily(tableName, columnFamily);
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
删除数据

package org.example.three;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HBaseDeleteColumnFamily {
public static void main(String[] args) {
try {
// 配置HBase连接
org.apache.hadoop.conf.Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "192.168.91.128");
config.set("hbase.zookeeper.property.clientPort", "2181");
// 建立连接
Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin();
// 删除表的列族
TableName tableName = TableName.valueOf("s1"); // 修改为你的表名
admin.deleteColumnFamily(tableName, Bytes.toBytes("phone")); // 修改为你要删除的列族名称
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
(4) 清空指定的表的所有记录数据;
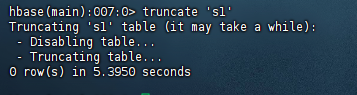
package org.example.three;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.TableName;
import java.io.IOException;
public class HBaseTruncateTable {
public static void main(String[] args) {
try {
// 配置HBase连接
org.apache.hadoop.conf.Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "master");
config.set("hbase.zookeeper.property.clientPort", "2181");
// 建立连接
Connection connection = ConnectionFactory.createConnection(config);
Admin admin = connection.getAdmin();
// 设置表名
TableName tableName = TableName.valueOf("s1"); // 修改为你的表名
// 确保表被禁用
if (!admin.isTableDisabled(tableName)) {
System.out.println("禁用表...");
admin.disableTable(tableName); // 禁用表
}
// 清空表数据
System.out.println("清空表数据...");
admin.truncateTable(tableName, false); // 清空表但不删除表
connection.close();
System.out.println("表已清空!");
} catch (IOException e) {
e.printStackTrace();
}
}
}
(5) 统计表的行数。
package org.example.three;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HBaseCountRows {
public static void main(String[] args) {
try {
// 配置HBase连接
org.apache.hadoop.conf.Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", "master");
config.set("hbase.zookeeper.property.clientPort", "2181");
// 建立连接
Connection connection = ConnectionFactory.createConnection(config);
Table table = connection.getTable(TableName.valueOf("s1")); // 修改为你的表名
// 扫描表并统计行数
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan);
int rowCount = 0;
for (Result result : scanner) {
rowCount++;
}
System.out.println("总共行数: " + rowCount);
scanner.close();
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
(二)HBase数据库操作
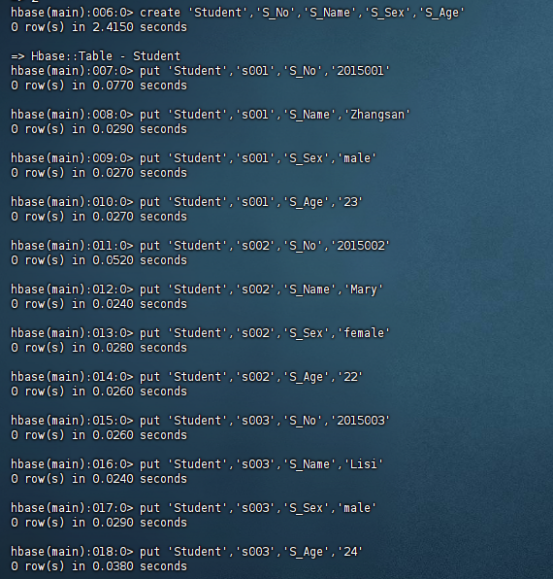
1. 现有以下关系型数据库中的表和数据(见表14-3到表14-5),要求将其转换为适合于HBase存储的表并插入数据:
表14-3 学生表(Student)
|
学号(S_No) |
姓名(S_Name) |
性别(S_Sex) |
年龄(S_Age) |
|
2015001 |
Zhangsan |
male |
23 |
|
2015002 |
Mary |
female |
22 |
|
2015003 |
Lisi |
male |
24 |
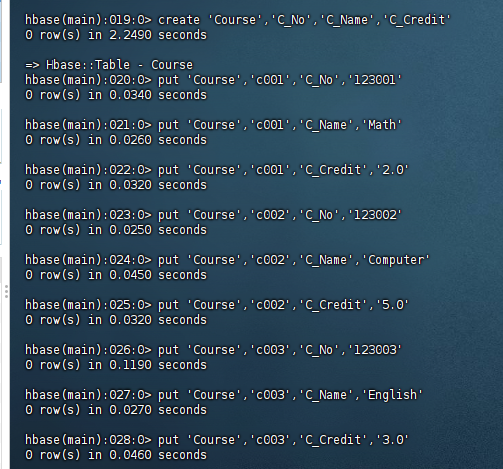
表14-4 课程表(Course)
|
课程号(C_No) |
课程名(C_Name) |
学分(C_Credit) |
|
123001 |
Math |
2.0 |
|
123002 |
Computer Science |
5.0 |
|
123003 |
English |
3.0 |
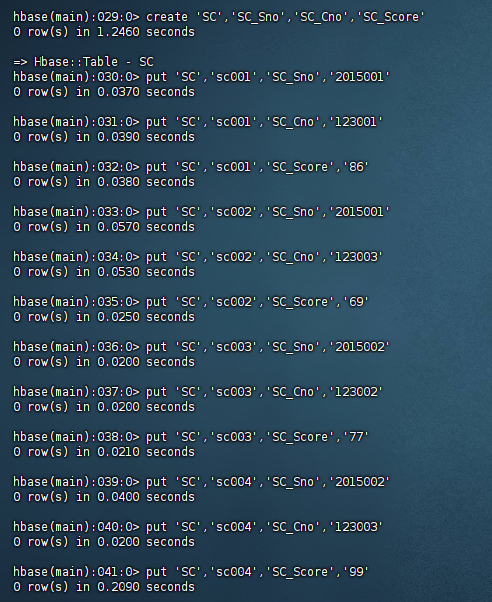
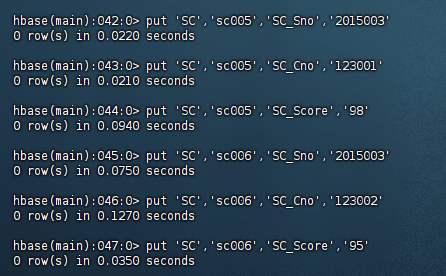
表14-5 选课表(SC)
|
学号(SC_Sno) |
课程号(SC_Cno) |
成绩(SC_Score) |
|
2015001 |
123001 |
86 |
|
2015001 |
123003 |
69 |
|
2015002 |
123002 |
77 |
|
2015002 |
123003 |
99 |
|
2015003 |
123001 |
98 |
|
2015003 |
123002 |
95 |
2. 请编程实现以下功能:
(1)createTable(String tableName, String[] fields)
创建表,参数tableName为表的名称,字符串数组fields为存储记录各个字段名称的数组。要求当HBase已经存在名为tableName的表的时候,先删除原有的表,然后再创建新的表。

(2)addRecord(String tableName, String row, String[] fields, String[] values)
向表tableName、行row(用S_Name表示)和字符串数组fields指定的单元格中添加对应的数据values。其中,fields中每个元素如果对应的列族下还有相应的列限定符的话,用“columnFamily:column”表示。例如,同时向“Math”、“Computer Science”、“English”三列添加成绩时,字符串数组fields为{“Score:Math”, ”Score:Computer Science”, ”Score:English”},数组values存储这三门课的成绩。

(3)scanColumn(String tableName, String column)
浏览表tableName某一列的数据,如果某一行记录中该列数据不存在,则返回null。要求当参数column为某一列族名称时,如果底下有若干个列限定符,则要列出每个列限定符代表的列的数据;当参数column为某一列具体名称(例如“Score:Math”)时,只需要列出该列的数据。

(4)modifyData(String tableName, String row, String column)
修改表tableName,行row(可以用学生姓名S_Name表示),列column指定的单元格的数据。

(5)deleteRow(String tableName, String row)
删除表tableName中row指定的行的记录。

4.实验报告
|
题目: |
熟悉常用的HBase操作 |
姓名 |
|
日期 11.18 |
|
实验环境:操作系统:Linux;Hadoop版本:2.7.3 |
||||
|
实验内容与完成情况: 1. 编程实现指定功能,并用 Hadoop 提供的 HBase Shell 命令完成相同任务: 2. 现有关系型数据库中的表和数据,要求将其转换为适合于 HBase 存储的表并插入数据。 |
||||
|
出现的问题:数据类型不匹配:关系型数据库中的数据类型可能与HBase中的数据类型不匹配。 字段长度限制:HBase对字符串字段的长度有长度限制,可能需要截断或更改字段类型。 索引和主键:HBase不直接支持索引和主键,可能需要重新设计数据模型。 |
||||
|
解决方案(列出遇到的问题和解决办法,列出没有解决的问题):检查并调整数据类型,确保与HBase兼容。 对于长字符串字段,考虑使用string类型,并适当截断或使用多个字段存储。 重新设计数据模型,使用HBase的分区特性来优化查询性能。 |
||||
