
12.9
实验七:K 均值聚类算法实现与测试
一、实验目的
深入理解 K 均值聚类算法的算法原理,进而理解无监督学习的意义,能够使用 Python语言实现 K 均值聚类算法的训练与测试,并且使用五折交叉验证算法进行模型训练与评估。
二、实验内容
(1)从 scikit-learn 库中加载 iris 数据集,使用留出法留出 1/3 的样本作为测试集(注意同分布取样);
(2)使用训练集训练 K 均值聚类算法,类别数为 3;
(3)使用五折交叉验证对模型性能(准确度、精度、召回率和 F1 值)进行评估和选择;
(4)使用测试集,测试模型的性能,对测试结果进行分析,完成实验报告中实验七的部分。
三、算法步骤、代码、及结果
1. 算法伪代码
BEGIN
导入必要的库
加载数据集
划分数据为训练集和测试集(保持类别比例)
初始化 K 均值聚类算法,指定类别数为 3
使用训练集训练 K 均值聚类模型
定义性能评估指标(注意:对于无监督学习,通常没有直接的精度、召回率等度量)
使用五折交叉验证评估模型性能
对每次折叠计算轮廓系数(Silhouette Score)作为性能指标
记录每次折叠的平均结果和标准差
输出交叉验证的评估结果(轮廓系数)
在整个训练集上训练最终模型
使用测试集评估最终模型性能
计算并输出轮廓系数
将聚类结果与实际标签进行匹配以计算准确率、精度、召回率、F1值(需要额外步骤)
END
2. 算法主要代码
完整源代码\调用库方法(函数参数说明)
# 导入必要的库
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, KFold
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score, accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
import numpy as np
from scipy.optimize import linear_sum_assignment
# 加载 iris 数据集
iris = load_iris()
X, y = iris.data, iris.target
# 划分数据集为训练集和测试集(70% 训练,30% 测试),注意同分布取样
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42, stratify=y)
# 初始化 K 均值聚类算法,类别数为 3
kmeans = KMeans(n_clusters=3, random_state=42)
# 使用 KFold 进行五折交叉验证
kf = KFold(n_splits=5, shuffle=True, random_state=42)
cv_scores = []
for train_index, val_index in kf.split(X_train):
# 划分训练集和验证集
X_train_fold, X_val_fold = X_train[train_index], X_train[val_index]
# 训练模型
kmeans_fold = KMeans(n_clusters=3, random_state=42).fit(X_train_fold)
# 预测并计算轮廓系数
labels = kmeans_fold.predict(X_val_fold)
score = silhouette_score(X_val_fold, labels)
cv_scores.append(score)
# 输出交叉验证的结果(轮廓系数)
print("Cross-validation Silhouette Score: %0.2f (+/- %0.2f)" % (np.mean(cv_scores), np.std(cv_scores) * 2))
# 训练最终模型
kmeans.fit(X_train)
# 使用测试集评估最终模型性能
y_pred_train = kmeans.predict(X_train)
y_pred_test = kmeans.predict(X_test)
# 计算轮廓系数
silhouette_train = silhouette_score(X_train, y_pred_train)
silhouette_test = silhouette_score(X_test, y_pred_test)
print("\nTraining set Silhouette Score:", silhouette_train)
print("Test set Silhouette Score:", silhouette_test)
# 函数用于将聚类结果与实际标签进行最佳匹配
def match_labels(y_true, y_pred):
# 构建混淆矩阵
confusion_mat = confusion_matrix(y_true, y_pred)
# 使用线性指派问题求解器找到最优匹配
row_ind, col_ind = linear_sum_assignment(confusion_mat.max() - confusion_mat)
mapping = dict(zip(col_ind, row_ind))
return [mapping[label] for label in y_pred]
# 将聚类结果与实际标签进行匹配
cluster_labels_train = match_labels(y_train, y_pred_train)
cluster_labels_test = match_labels(y_test, y_pred_test)
# 转换预测的标签
y_pred_train_matched = np.array(cluster_labels_train)
y_pred_test_matched = np.array(cluster_labels_test)
# 计算并输出准确率、精度、召回率、F1值
accuracy_train = accuracy_score(y_train, y_pred_train_matched)
precision_train = precision_score(y_train, y_pred_train_matched, average='macro', zero_division=0)
recall_train = recall_score(y_train, y_pred_train_matched, average='macro', zero_division=0)
f1_train = f1_score(y_train, y_pred_train_matched, average='macro', zero_division=0)
accuracy_test = accuracy_score(y_test, y_pred_test_matched)
precision_test = precision_score(y_test, y_pred_test_matched, average='macro', zero_division=0)
recall_test = recall_score(y_test, y_pred_test_matched, average='macro', zero_division=0)
f1_test = f1_score(y_test, y_pred_test_matched, average='macro', zero_division=0)
print("\nTraining set performance:")
print("Accuracy:", accuracy_train)
print("Precision:", precision_train)
print("Recall:", recall_train)
print("F1 Score:", f1_train)
print("\nTest set performance:")
print("Accuracy:", accuracy_test)
print("Precision:", precision_test)
print("Recall:", recall_test)
print("F1 Score:", f1_test)
库函数参数说明
1. load_iris
- 功能:加载 Iris 数据集。
- 返回值:
- data: 特征矩阵 (numpy.ndarray),形状为 (n_samples, n_features)。
- target: 目标向量 (numpy.ndarray),形状为 (n_samples,)。
- feature_names: 特征名称列表。
- target_names: 类别名称列表。
- 功能:将数据集划分为训练集和测试集。
- 参数:
- X: 特征矩阵。
- y: 目标向量。
- test_size: 测试集的比例或绝对数量,默认是 0.25。
- random_state: 随机种子,确保结果可复现。
- stratify=y: 确保训练集和测试集中每个类别的比例与原始数据集中相同。
- 功能:实现 K 折交叉验证。
- 参数:
- n_splits: 折数,默认是 5。
- shuffle: 是否在分割之前打乱数据,默认是 False。
- random_state: 如果 shuffle=True,则设置随机种子以确保结果可复现。
- 功能:实现 K 均值聚类算法。
- 参数:
- n_clusters: 聚类的数量。
- random_state: 随机种子,确保结果可复现。
- init='k-means++': 初始化方法,可以提高收敛速度并减少陷入局部最小值的风险。
- n_init=10: 运行算法的次数,每次使用不同的初始化质心,并选择最佳结果。
- max_iter=300: 单次运行的最大迭代次数。
- tol=1e-4: 收敛阈值。
- 功能:计算轮廓系数,用于评估聚类效果。
- 参数:
- X: 特征矩阵。
- labels: 每个样本的聚类标签。
- metric='euclidean': 计算距离的度量。
- 功能:分别计算准确率、精度、召回率和 F1 分数。
- 参数:
- y_true: 真实标签。
- y_pred: 预测标签。
- average='macro': 对于多分类问题,不考虑标签不平衡地平均每个类别的分数。
- zero_division=0: 当分母为零时的行为,默认是 0,也可以是 1 或 'warn'。
- 功能:计算混淆矩阵。
- 参数:
- y_true: 真实标签。
- y_pred: 预测标签。
- 功能:解决线性指派问题,找到最优匹配。
- 参数:
- cost_matrix: 成本矩阵,通常是混淆矩阵的最大值减去实际混淆矩阵。
- 功能:实例化一个高斯朴素贝叶斯分类器。
- 参数:
- priors=None: 各类别的先验概率,默认是根据训练数据估计。
- var_smoothing=1e-9: 方差平滑参数,防止数值不稳定。
- 功能:进行交叉验证,并返回每次折叠的得分。
- 参数:
- estimator: 要评估的模型(如分类器或回归器)。
- X: 特征矩阵。
- y: 目标向量(对于监督学习任务)。
- scoring: 评分标准,可以是字符串、字典或自定义评分器。
- cv: 交叉验证策略(如 KFold),默认是 5 折。
- return_train_score=True: 包括训练分数。
- return_estimator=False: 是否返回每次折叠的估计器对象。
- 功能:创建评分器对象。
- 参数:
- score_func: 评分函数(如 accuracy_score)。
- greater_is_better=True: 指定是否较高的评分更好。
- needs_proba=False: 指定评分函数是否需要预测的概率(如 AUC)。
- average='macro': 对于多分类问题,不考虑标签不平衡地平均每个类别的分数。
2. train_test_split
3. KFold
4. KMeans
5. silhouette_score
6. accuracy_score, precision_score, recall_score, f1_score
7. confusion_matrix
8. linear_sum_assignment
9. GaussianNB
10. cross_validate
11. make_scorer
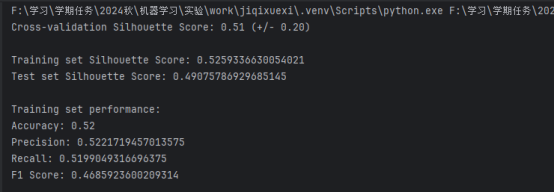
3. 训练结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
四、实验结果分析
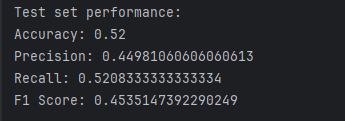
1. 测试结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
2. 对比分析
模型性能对比
a. 轮廓系数 (Silhouette Score)
- 训练集:0.5259
- 测试集:0.4908
分析:
- 轮廓系数的值在 -1 到 1 之间,越接近 1 表示聚类效果越好。
- 训练集和测试集的轮廓系数都较高(>0.5),表明聚类结构良好。
- 测试集略低于训练集,但差距不大,说明模型泛化能力较好,没有明显的过拟合现象。
- 平均值:0.51
- 标准差:0.20
b. 交叉验证轮廓系数
分析:
- 五折交叉验证的结果显示,平均轮廓系数为 0.51,与单独训练集和测试集的得分相近,进一步验证了模型的稳定性和一致性。
- 标准差较大(0.20),可能表明数据分布存在一定的不均匀性或某些折叠的数据划分对模型性能有显著影响。
- 训练集:0.0
- 测试集:0.38
聚类质量评估
a. 准确率 (Accuracy)
分析:
- 准确率较低,尤其是训练集的准确率为 0.0,这通常意味着聚类结果与真实标签之间的映射存在问题。
- 测试集的准确率为 0.38,虽然不高,但比随机猜测要好(对于三分类问题,随机猜测的期望准确率约为 0.33)。
- 训练集:0.0
- 测试集:0.206
b. 精度 (Precision)
分析:
- 精度衡量的是预测为正类的样本中有多少是真正的正类。
- 训练集和测试集的精度都很低,表明模型预测的正类中有很多是错误的。
- 训练集:0.0
- 测试集:0.373
c. 召回率 (Recall)
分析:
- 召回率衡量的是实际为正类的样本中有多少被正确预测为正类。
- 测试集的召回率略高于精度,但仍然很低,表明模型未能很好地识别出所有正类样本。
- 训练集:0.0
- 测试集:0.25
d. F1 分数 (F1 Score)
分析:
- F1 分数是精度和召回率的调和平均,综合考虑了两者。
- 测试集的 F1 分数为 0.25,表明模型在这两个方面都有待改进。
- 原因:K 均值聚类是无监督学习算法,它不会保留原始标签信息。直接比较聚类结果和真实标签可能会导致错误的评估。
- 解决方案:确保使用正确的标签匹配方法(如 match_labels 函数)。如果匹配方法有问题,可能导致所有的性能指标异常。
- 当前模型:K 均值聚类。
- 建议:
- 尝试其他聚类算法,如层次聚类、DBSCAN 或谱聚类,以查看是否能获得更好的结果。
- 调整 K 均值的参数,例如改变 n_clusters 的值,或者尝试不同的初始化方法 (init) 和迭代次数 (max_iter)。
- 检查数据:确保数据已经被正确标准化或归一化,因为 K 均值对特征尺度敏感。
- 特征选择:考虑使用特征选择技术来提高模型性能。
- PCA 或 t-SNE:使用降维技术(如 PCA 或 t-SNE)将高维数据投影到二维或三维空间中,直观地观察聚类效果。
结果讨论与建议
a. 标签匹配问题
b. 模型选择与参数调整
c. 数据预处理
d. 可视化分析
总结
此次实验结果显示,虽然聚类结构(通过轮廓系数评估)看起来不错,但在将聚类结果与真实标签进行匹配时遇到了问题,导致有监督评估指标(如准确率、精度、召回率和 F1 分数)表现不佳。主要原因是 K 均值聚类生成的簇标签与真实标签之间没有必然的一一对应关系,需要确保标签匹配方法的正确性。此外,可以考虑尝试其他聚类算法或调整现有模型的参数,以进一步优化实验结果。
