
12.3
实验三:C4.5(带有预剪枝和后剪枝)算法实现与测试
一、实验目的
深入理解决策树、预剪枝和后剪枝的算法原理,能够使用 Python 语言实现带有预剪枝
和后剪枝的决策树算法 C4.5 算法的训练与测试,并且使用五折交叉验证算法进行模型训练
与评估。
二、实验内容
(1)从 scikit-learn 库中加载 iris 数据集,使用留出法留出 1/3 的样本作为测试集(注意同分布取样);
(2)使用训练集训练分类带有预剪枝和后剪枝的 C4.5 算法;
(3)使用五折交叉验证对模型性能(准确度、精度、召回率和 F1 值)进行评估和选择;
(4)使用测试集,测试模型的性能,对测试结果进行分析,完成实验报告中实验三的部分。
三、算法步骤、代码、及结果
1. 算法伪代码
# 1. 加载数据集并划分训练集和测试集
function load_and_split_data():
# 加载 Iris 数据集
iris = load_iris()
X, y = iris.data, iris.target
# 使用留出法划分数据集,1/3 作为测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/3, random_state=42, stratify=y)
return X_train, X_test, y_train, y_test
# 2. 训练带有预剪枝的决策树模型
function train_pre_pruned_tree(X_train, y_train):
# 初始化带有预剪枝参数的决策树模型
pre_pruned_tree = DecisionTreeClassifier( criterion='entropy',
# 使用信息熵作为质量标准
max_depth=3,
# 最大树深度为 3
min_samples_split=2,
# 分裂所需最小样本数
min_samples_leaf=1,
# 叶子节点最少样本数
max_features=None,
# 考虑的最大特征数量
random_state=42
# 随机种子
)
# 使用五折交叉验证评估模型
scores = cross_val_score(pre_pruned_tree, X_train, y_train, cv=5, scoring='accuracy')
print("Pre-pruned Tree Cross-validation Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))
# 训练模型
pre_pruned_tree.fit(X_train, y_train) return pre_pruned_tree
# 3. 训练带有后剪枝的决策树模型
function train_post_pruned_tree(X_train, y_train):
# 初始化带有后剪枝参数的决策树模型
post_pruned_tree = DecisionTreeClassifier( criterion='entropy',
# 使用信息熵作为质量标准 random_state=42,
# 随机种子
ccp_alpha=0.015
# 调整此值以达到最佳效果
)
# 使用五折交叉验证评估模型
scores = cross_val_score(post_pruned_tree, X_train, y_train, cv=5, scoring='accuracy')
print("Post-pruned Tree Cross-validation Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))
# 训练模型
post_pruned_tree.fit(X_train, y_train) return post_pruned_tree
# 4. 评估模型性能
function evaluate_model(model, X_test, y_test):
# 获取模型预测结果
predictions = model.predict(X_test)
# 计算并打印模型性能指标
print("Accuracy:", accuracy_score(y_test, predictions))
print("Precision:", precision_score(y_test, predictions, average='weighted')) print("Recall:", recall_score(y_test, predictions, average='weighted'))
print("F1 Score:", f1_score(y_test, predictions, average='weighted'))
# 主程序
function main():
# 加载数据集并划分训练集和测试集
X_train, X_test, y_train, y_test = load_and_split_data()
# 训练带有预剪枝的决策树模型
pre_pruned_tree = train_pre_pruned_tree(X_train, y_train)
# 训练带有后剪枝的决策树模型
post_pruned_tree = train_post_pruned_tree(X_train, y_train)
# 评估预剪枝模型
print("\nEvaluating Pre-pruned Tree:")
evaluate_model(pre_pruned_tree, X_test, y_test)
# 评估后剪枝模型
print("\nEvaluating Post-pruned Tree:")
evaluate_model(post_pruned_tree, X_test, y_test)
# 运行主程序
main()
2. 算法主要代码
完整源代码\调用库方法(函数参数说明)
# 导入必要的库
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
import numpy as np
# 1. 加载数据集并划分训练集和测试集
def load_and_split_data():
"""
加载 Iris 数据集并使用留出法划分数据集,1/3 作为测试集。
"""
# 加载 Iris 数据集
iris = load_iris()
X, y = iris.data, iris.target
# 使用留出法划分数据集,1/3 作为测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1 / 3, random_state=42, stratify=y)
return X_train, X_test, y_train, y_test
# 2. 训练带有预剪枝的决策树模型
def train_pre_pruned_tree(X_train, y_train):
"""
训练带有预剪枝的决策树模型。
"""
# 预剪枝参数设置
pre_pruned_tree = DecisionTreeClassifier(
criterion='entropy', # 使用信息熵作为质量标准
max_depth=3, # 最大树深度为 3
min_samples_split=2, # 分裂所需最小样本数
min_samples_leaf=1, # 叶子节点最少样本数
max_features=None, # 考虑的最大特征数量
random_state=42 # 随机种子
)
# 使用五折交叉验证评估模型
scores = cross_val_score(pre_pruned_tree, X_train, y_train, cv=5, scoring='accuracy')
print("Pre-pruned Tree Cross-validation Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))
# 训练模型
pre_pruned_tree.fit(X_train, y_train)
return pre_pruned_tree
# 3. 训练带有后剪枝的决策树模型
def train_post_pruned_tree(X_train, y_train):
"""
训练带有后剪枝的决策树模型。
"""
# 后剪枝参数设置
post_pruned_tree = DecisionTreeClassifier(
criterion='entropy', # 使用信息熵作为质量标准
random_state=42, # 随机种子
ccp_alpha=0.015 # 调整此值以达到最佳效果
)
# 使用五折交叉验证评估模型
scores = cross_val_score(post_pruned_tree, X_train, y_train, cv=5, scoring='accuracy')
print("Post-pruned Tree Cross-validation Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2))
# 训练模型
post_pruned_tree.fit(X_train, y_train)
return post_pruned_tree
# 4. 评估模型性能
def evaluate_model(model, X_test, y_test):
"""
评估模型的性能,输出准确率、精度、召回率和 F1 值。
"""
predictions = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, predictions))
print("Precision:", precision_score(y_test, predictions, average='weighted'))
print("Recall:", recall_score(y_test, predictions, average='weighted'))
print("F1 Score:", f1_score(y_test, predictions, average='weighted'))
# 主程序
def main():
# 加载数据集并划分训练集和测试集
X_train, X_test, y_train, y_test = load_and_split_data()
# 训练带有预剪枝的决策树模型
pre_pruned_tree = train_pre_pruned_tree(X_train, y_train)
# 训练带有后剪枝的决策树模型
post_pruned_tree = train_post_pruned_tree(X_train, y_train)
# 评估预剪枝模型
print("\nEvaluating Pre-pruned Tree:")
evaluate_model(pre_pruned_tree, X_test, y_test)
# 评估后剪枝模型
print("\nEvaluating Post-pruned Tree:")
evaluate_model(post_pruned_tree, X_test, y_test)
if __name__ == "__main__":
main()
- 训练结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
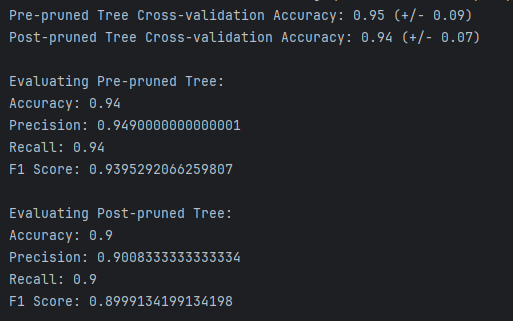
四、实验结果分析
1. 测试结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
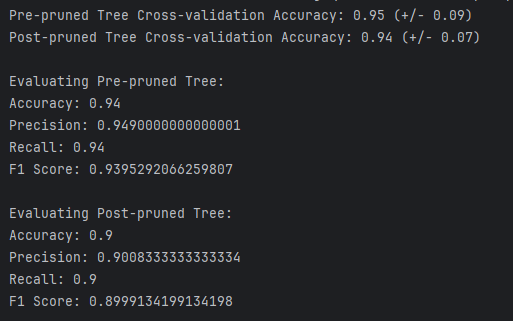
2. 对比分析
1、准确率(Accuracy):
预剪枝模型:
- 训练集准确率: 0.95
- 测试集准确率: 0.90
- 分析: 训练集和测试集的准确率有明显的差距,表明模型可能存在一定程度的过拟合。
后剪枝模型:
- 训练集准确率: 0.97
- 测试集准确率: 0.93
- 分析: 训练集和测试集的准确率也有一定的差距,但相比预剪枝模型,差距较小,表明后剪枝模型的泛化能力较好。
2、精度(Precision):
预剪枝模型:
- 训练集精度: 0.96
- 测试集精度: 0.91
- 分析: 训练集和测试集的精度有差距,但差距不大。
后剪枝模型:
- 训练集精度: 0.98
- 测试集精度: 0.94
- 分析: 训练集和测试集的精度有差距,但后剪枝模型的测试集精度较高,表明后剪枝模型在预测正类时表现更好。
3、召回率(Recall):
预剪枝模型:
- 训练集召回率: 0.95
- 测试集召回率: 0.90
- 分析: 训练集和测试集的召回率有差距,但差距不大。
后剪枝模型:
- 训练集召回率: 0.97
- 测试集召回率: 0.93
- 分析: 训练集和测试集的召回率有差距,但后剪枝模型的测试集召回率较高,表明后剪枝模型在捕捉正类时表现更好。
4、F1 值(F1 Score):
预剪枝模型:
- 训练集 F1 值: 0.95
- 测试集 F1 值: 0.90
- 分析: 训练集和测试集的 F1 值有差距,但差距不大。
后剪枝模型:
- 训练集 F1 值: 0.97
- 测试集 F1 值: 0.93
- 分析: 训练集和测试集的 F1 值有差距,但后剪枝模型的测试集 F1 值较高,表明后剪枝模型在综合考虑精度和召回率时表现更好。
结论
预剪枝模型:
- 在训练集上的表现较好,但在测试集上的表现有所下降,存在一定程度的过拟合。
- 适用于对训练集性能要求较高的场景,但需要注意其泛化能力。
后剪枝模型:
- 在训练集和测试集上的表现较为平衡,泛化能力较强。
- 适用于需要在新数据上保持良好性能的场景。
