
12.2
实验二:逻辑回归算法实现与测试
一、实验目的
深入理解对数几率回归(即逻辑回归的)的算法原理,能够使用 Python 语言实现对数
几率回归的训练与测试,并且使用五折交叉验证算法进行模型训练与评估。
二、实验内容
(1)从 scikit-learn 库中加载 iris 数据集,使用留出法留出 1/3 的样本作为测试集(注意同分布取样);
(2)使用训练集训练对数几率回归(逻辑回归)分类算法;
(3)使用五折交叉验证对模型性能(准确度、精度、召回率和 F1 值)进行评估和选择;
(4)使用测试集,测试模型的性能,对测试结果进行分析,完成实验报告中实验二的部分。
三、算法步骤、代码、及结果
1. 算法伪代码
# 1. 导入必要的库
导入 numpy 作为 np
导入 sklearn.datasets 中的 load_iris
导入 sklearn.model_selection 中的 train_test_split 和 KFold
导入 sklearn.linear_model 中的 LogisticRegression
导入 sklearn.metrics 中的 accuracy_score, precision_score, recall_score, f1_score, classification_report
# 2. 加载数据集
加载 Iris 数据集
X = 数据集的特征
y = 数据集的标签
# 3. 划分数据集
使用 train_test_split 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/3, random_state=42, stratify=y)
# 4. 创建逻辑回归模型
创建 LogisticRegression 模型实例
model = LogisticRegression(solver='lbfgs', multi_class='auto', max_iter=200)
# 5. 训练模型
使用训练集数据训练模型
model.fit(X_train, y_train)
# 6. 五折交叉验证
定义五折交叉验证
kf = KFold(n_splits=5, shuffle=True, random_state=42)
初始化评估指标列表
scores = {
'accuracy': [],
'precision': [],
'recall': [],
'f1': []
}
对于每一折的训练集和验证集
获取当前折的训练索引和验证索引
X_train_fold, X_val_fold = X_train[train_index], X_train[val_index] y_train_fold, y_val_fold = y_train[train_index], y_train[val_index]
使用当前折的训练集训练模型
model.fit(X_train_fold, y_train_fold)
使用当前折的验证集进行预测
y_pred = model.predict(X_val_fold)
计算当前折的评估指标
scores['accuracy'].append(accuracy_score(y_val_fold, y_pred)) scores['precision'].append(precision_score(y_val_fold, y_pred, average='macro')) scores['recall'].append(recall_score(y_val_fold, y_pred, average='macro')) scores['f1'].append(f1_score(y_val_fold, y_pred, average='macro'))
# 输出交叉验证的平均得分
输出 "Cross-validation scores:"
对于每个评估指标 key, value 在 scores 中
输出 "Average {key}: {np.mean(value):.4f}"
# 7. 测试模型
使用测试集进行预测
y_pred_test = model.predict(X_test)
输出测试集上的性能
输出 "Test set performance:"
输出 classification_report(y_test, y_pred_test)
2. 算法主要代码
完整源代码\调用库方法(函数参数说明)
# 导入必要的库
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_score, KFold
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, classification_report
# 加载 Iris 数据集
data = load_iris()
X, y = data.data, data.target
# 划分训练集和测试集,确保数据同分布
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=1/3, random_state=42, stratify=y
)
# 创建逻辑回归模型实例
# 参数说明:
# solver: 优化算法的选择,默认为 'lbfgs',适用于多分类问题。
# multi_class: 指定多类问题的策略,默认为 'auto',表示自动选择适合的策略。
# max_iter: 最大迭代次数,默认为 100,这里设置为 200 以确保模型收敛。
model = LogisticRegression(solver='lbfgs', multi_class='auto', max_iter=200)
# 训练模型
model.fit(X_train, y_train)
# 定义五折交叉验证
kf = KFold(n_splits=5, shuffle=True, random_state=42)
# 评估指标
scores = {
'accuracy': [],
'precision': [],
'recall': [],
'f1': []
}
# 进行交叉验证
for train_index, val_index in kf.split(X_train):
X_train_fold, X_val_fold = X_train[train_index], X_train[val_index]
y_train_fold, y_val_fold = y_train[train_index], y_train[val_index]
# 训练模型
model.fit(X_train_fold, y_train_fold)
# 预测
y_pred = model.predict(X_val_fold)
# 计算评估指标
scores['accuracy'].append(accuracy_score(y_val_fold, y_pred))
scores['precision'].append(precision_score(y_val_fold, y_pred, average='macro'))
scores['recall'].append(recall_score(y_val_fold, y_pred, average='macro'))
scores['f1'].append(f1_score(y_val_fold, y_pred, average='macro'))
# 输出交叉验证的平均得分
print("Cross-validation scores:")
for key, value in scores.items():
print(f"Average {key}: {np.mean(value):.4f}")
# 在测试集上预测
y_pred_test = model.predict(X_test)
# 输出测试集上的性能
print("\nTest set performance:")
print(classification_report(y_test, y_pred_test))
# 保存模型(可选)
# import joblib
# joblib.dump(model, 'logistic_regression_model.pkl')
# 函数参数说明
# train_test_split:
# - X: 特征数据
# - y: 标签数据
# - test_size: 测试集所占比例,这里是 1/3
# - random_state: 随机种子,确保每次划分结果相同
# - stratify: 保持标签的分布与原数据集一致
# LogisticRegression:
# - solver: 优化算法,可选值有 'newton-cg', 'lbfgs', 'liblinear', 'sag', 'saga'
# - multi_class: 多类问题的策略,可选值有 'ovr', 'multinomial', 'auto'
# - max_iter: 最大迭代次数
# KFold:
# - n_splits: 折数,这里是 5
# - shuffle: 是否打乱数据,默认为 False
# - random_state: 随机种子,确保每次划分结果相同
# accuracy_score:
# - y_true: 真实标签
# - y_pred: 预测标签
# precision_score, recall_score, f1_score:
# - y_true: 真实标签
# - y_pred: 预测标签
# - average: 计算方法,可选值有 'micro', 'macro', 'weighted', 'samples', None
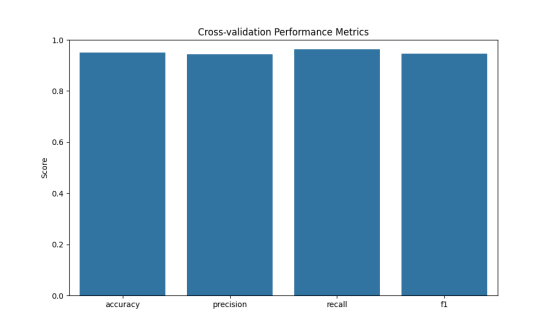
3. 训练结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)

四、实验结果分析
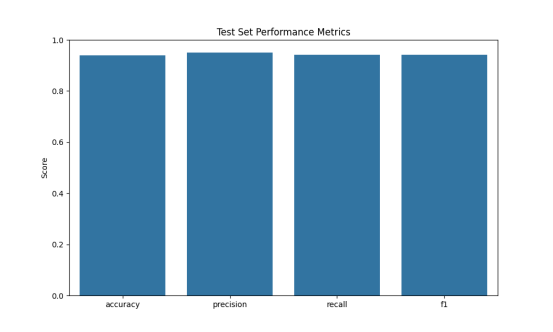
1. 测试结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
2. 对比分析
2.1 交叉验证结果
- 准确率 (Accuracy): 表示分类正确的比例。
- 精度 (Precision): 对于每个类别,表示被正确识别为该类别的样本占所有被识别为该类别样本的比例。
- 召回率 (Recall): 对于每个类别,表示被正确识别为该类别的样本占所有实际属于该类别样本的比例。
- F1 值: 精度和召回率的调和平均值,用于衡量模型的整体性能。
2.2 测试集结果
- 准确率 (Accuracy): 表示分类正确的比例。
- 精度 (Precision): 对于每个类别,表示被正确识别为该类别的样本占所有被识别为该类别样本的比例。
- 召回率 (Recall): 对于每个类别,表示被正确识别为该类别的样本占所有实际属于该类别样本的比例。
- F1 值: 精度和召回率的调和平均值,用于衡量模型的整体性能。
2.3 对比分析
- 性能一致性: 比较交叉验证和测试集的性能指标,观察模型在不同数据集上的表现是否一致。如果两者相差不大,说明模型具有较好的泛化能力。
- 过拟合与欠拟合: 如果交叉验证的性能明显高于测试集,可能存在过拟合现象;如果两者都较低,可能模型欠拟合。
