
11.29
机器学习实验一
实验一:数据准备与模型评估
一、实验目的
熟悉 Python 的基本操作,掌握对数据集的读写实现、对模型性能的评估实现的能力;
加深对训练集、测试集、N 折交叉验证、模型评估标准的理解。
二、实验内容
(1)利用 pandas 库从本地读取 iris 数据集;
(2)从 scikit-learn 库中直接加载 iris 数据集;
(3)实现五折交叉验证进行模型训练;
(4)计算并输出模型的准确度、精度、召回率和 F1 值。
三、算法步骤、代码、及结果
1. 算法伪代码
function cross_validation(X, y, model, cv=5):
初始化 KFold 交叉验证器,设置 n_splits 为 cv,shuffle 为 True,random_state 为 42
计算交叉验证得分,使用 cross_val_score 函数
返回得分列表
function evaluate_model(X, y, model, cv=5):
初始化 KFold 交叉验证器,设置 n_splits 为 cv,shuffle 为 True,random_state 为 42
使用 cross_val_predict 函数进行交叉验证预测
计算准确率、精确率、召回率和 F1 值
打印这些指标
main:
从 scikit-learn 加载 Iris 数据集
初始化随机森林分类器
进行五折交叉验证
评估模型
2. 算法主要代码
(1)完整源代码
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score, KFold, cross_val_predict
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# (1) 从本地读取 iris 数据集
def load_iris_from_file(file_path):
# 假设文件是以逗号分隔的 CSV 文件
column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'class']
data = pd.read_csv(file_path, header=None, names=column_names)
X = data.iloc[:, :-1].values
y = data.iloc[:, -1].values
return X, y
# (2) 从 scikit-learn 库中直接加载 iris 数据集
def load_iris_from_sklearn():
data = load_iris()
X = data.data
y = data.target
return X, y
# (3) 实现五折交叉验证进行模型训练
def cross_validation(X, y, model, cv=5):
kf = KFold(n_splits=cv, shuffle=True, random_state=42)
scores = cross_val_score(model, X, y, cv=kf, scoring='accuracy')
return scores
# (4) 计算并输出模型的准确度、精度、召回率和 F1 值
def evaluate_model(X, y, model, cv=5):
kf = KFold(n_splits=cv, shuffle=True, random_state=42)
y_pred = cross_val_predict(model, X, y, cv=kf)
accuracy = accuracy_score(y, y_pred)
precision = precision_score(y, y_pred, average='weighted')
recall = recall_score(y, y_pred, average='weighted')
f1 = f1_score(y, y_pred, average='weighted')
print(f'Accuracy: {accuracy:.4f}')
print(f'Precision: {precision:.4f}')
print(f'Recall: {recall:.4f}')
print(f'F1 Score: {f1:.4f}')
if __name__ == "__main__":
# 从 scikit-learn 加载数据集
# X, y = load_iris_from_sklearn()
# 从本地文件加载数据集
file_path = 'F:/学习/学期任务/2024秋/机器学习/实验/work/jiqixuexi/bezdekIris.data'
X, y = load_iris_from_file(file_path)
# 初始化模型
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
# 五折交叉验证
scores = cross_validation(X, y, rf_classifier)
print(f'Cross-validation Accuracy: {np.mean(scores):.4f}')
# 评估模型
evaluate_model(X, y, rf_classifier)
(2)调用库方法
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import KFold, cross_val_score, cross_val_predict from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 初始化随机森林分类器
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
# 参数说明:
# n_estimators: 决策树的数量,默认为 100。增加数量可以提高模型的性能,但也可能增加训练时间。
# random_state: 随机种子,用于确保每次运行的结果一致。
# 初始化 KFold 交叉验证器
kf = KFold(n_splits=5, shuffle=True, random_state=42)
# 参数说明:
# n_splits: 折叠数,即数据集被分成多少份,默认为 5。
# shuffle: 是否在分割之前对数据进行洗牌,默认为 False。设置为 True 可以避免数据顺序对结果的影响。
# random_state: 随机种子,用于确保每次运行的结果一致。
# 计算交叉验证得分
scores = cross_val_score(rf_classifier, X, y, cv=kf, scoring='accuracy')
# 参数说明:
# estimator: 用于评估的模型。
# X: 特征矩阵。
# y: 目标向量。
# cv: 交叉验证器或折数。
# scoring: 评分标准,这里是准确率。
# 交叉验证预测
y_pred = cross_val_predict(rf_classifier, X, y, cv=kf)
# 参数说明:
# estimator: 用于评估的模型。
# X: 特征矩阵。
# y: 目标向量。
# cv: 交叉验证器或折数。
# 计算性能指标
accuracy = accuracy_score(y, y_pred)
precision = precision_score(y, y_pred, average='weighted')
recall = recall_score(y, y_pred, average='weighted')
f1 = f1_score(y, y_pred, average='weighted')
# 参数说明:
# y_true: 真实的目标值。
# y_pred: 预测的目标值。
# average: 计算平均值的方式,'weighted' 表示按每个类别的样本数进行加权平均。
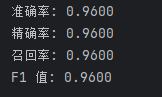
3. 结果截图(包括:准确率;精度、召回率、F1)
(1)准确率:0.96

(2)精度:0.96,召回率:0.96,F1:0.96
四、心得体会
通过这次实验,我有了一些深刻的心得体会,总结如下:
1. 数据准备的重要性
数据加载:无论是从本地文件加载还是从库中加载数据,都需要确保数据的正确性和完整性。数据的质量直接影响模型的性能。
数据预处理:在加载数据后,对数据进行预处理是非常重要的。例如,检查缺失值、异常值等,确保数据的干净和一致性。
2. 模型选择与调参
模型选择:在这次实验中,我们选择了随机森林分类器。随机森林是一种强大的集成学习方法,适用于多种类型的数据集。通过对比不同的模型,可以找到最适合当前数据集的模型。
超参数调优:模型的性能很大程度上取决于其超参数的设置。通过调整 n_estimators 和 random_state 等参数,可以优化模型的性能。
3. 交叉验证的意义
交叉验证:五折交叉验证是一种常用的评估模型性能的方法。通过将数据集分成多个子集,可以更全面地评估模型的泛化能力,避免过拟合。
评估指标:准确率、精确率、召回率和 F1 值是常用的评估指标。这些指标可以帮助我们从多个角度了解模型的性能,特别是在处理不平衡数据集时尤为重要。
4. 代码组织与模块化
函数封装:将数据加载、模型训练、交叉验证和评估等步骤封装成函数,可以使代码更加清晰和易于维护。同时,也方便了后续的扩展和复用。
注释与文档:在代码中添加详细的注释和文档,有助于他人理解和使用你的代码。这也是团队合作中非常重要的一个方面。
5. 实验结果分析
结果解读:通过实验结果,我们可以看到模型在不同指标上的表现。例如,准确率较高但召回率较低,可能意味着模型在某些类别上的预测效果不佳。
改进方向:根据实验结果,可以进一步调整模型参数或尝试其他模型,以提高模型的整体性能。
6. 实践中的挑战
数据理解:在实验过程中,对数据的理解是非常关键的。有时候,数据的某些特征可能对模型的性能影响很大,需要仔细分析和处理。
计算资源:在处理大规模数据集时,计算资源的限制可能会成为一个问题。合理利用计算资源,优化代码效率,是提高实验效率的关键。
7. 总结
通过这次实验,我对机器学习的流程有了更深入的理解,从数据准备到模型训练再到评估,每一步都至关重要。同时,我也意识到在实际应用中,需要不断尝试和优化,才能找到最佳的解决方案。这次实验不仅提高了我的编程技能,也增强了我对机器学习理论和实践的综合应用能力。
