10.29
大型数据库技术作业七
一. 单选题(共5题,10分)
1. (单选题, 2分) 在实际应用中,大数据处理不包括哪些类型?
基于实时数据流的数据处理
基于离线数据的处理
复杂的批量数据处理
基于历史数据的交互式查询
2. (单选题, 2分) 下列关于Spark的描述,错误的是哪一项?
Spark最初由美国加州伯克利大学(UCBerkeley)的AMP实验室于2009年开发
Spark在2014年打破了Hadoop保持的基准排序纪录.
Spark用十分之一的计算资源,获得了比Hadoop快3倍的速度
Spark运行模式单一
3. (单选题, 2分) 下列说法哪项有误?
相对于Spark来说,使用Hadoop进行迭代计算非常耗资源
Spark将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结果作运算,避免了从磁盘中频繁读取数据
Hadoop的设计遵循“一个软件栈满足不同应用场景”的理念
Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案
4. (单选题, 2分) 下列说法错误的是?
RDD(Resillient Distributed Dataset)是运行在工作节点(WorkerNode)的一个进程,负责运行Task
Application是用户编写的Spark应用程序
一个Job包含多个RDD及作用于相应RDD上的各种操作
Directed Acyclic Graph反映RDD之间的依赖关
5. (单选题, 2分) 下列关于RDD说法,描述有误的是?
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合
每个RDD可分成多个分区,每个分区就是一个数据集片段
RDD是可以直接修改的
RDD提供了一种高度受限的共享内存模型
二. 多选题(共5题,10分)
6. (多选题, 2分) Apache软件基金会最重要的三大分布式计算系统开源项目
Hadoop
Spark
Storm
Hive
7. (多选题, 2分) Spark具有的主要特点包括:
运行模式多样
运行速度快
容易使用
通用性
8. (多选题, 2分) Scala的特性包括:
Scala具备强大的并发性
Scala语法复杂
Scala兼容Java
运行速度快
9. (多选题, 2分) Spark最主要的优点是()
计算模式只能是MapReduce
Spark提供了内存计算
提供了单一数据集操作类型
基于DAG的任务调度执行机制
10. (多选题, 2分) Spark所采用Executor的优点包括:
利用多线程来执行具体的任务
多线程之间的数据共享
存储模块全部都只能在内存中完成
Executor中有一个BlockManager存储模块,有效减少IO开销
三. 简答题(共1题,20分)
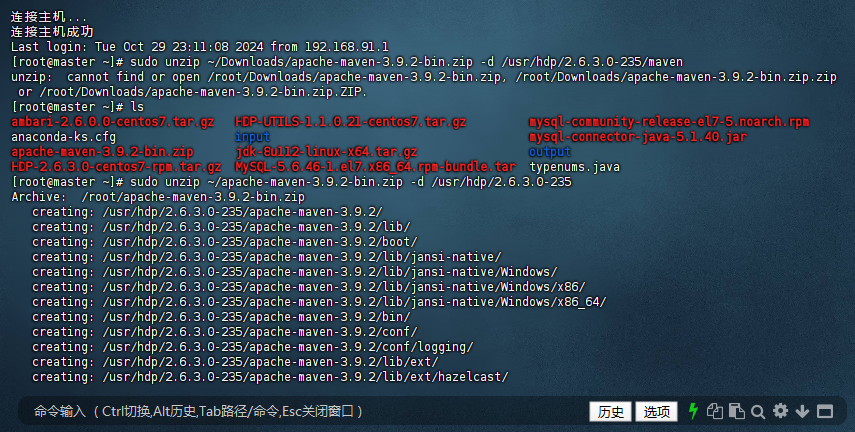
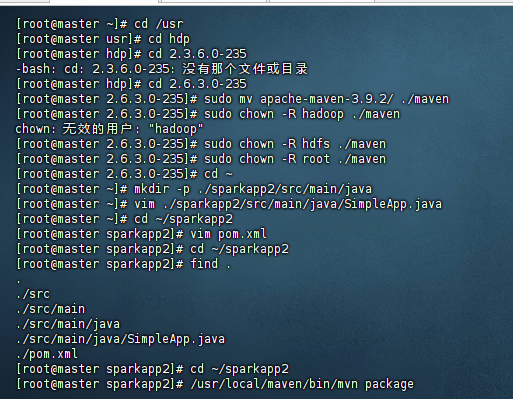
11. (简答题, 20分) 以下题目二选一: 1、请写出三个大数据在人类生活中应用的实例,并谈谈自己对大数据的看法。 2、编程实践:参考教程https://dblab.xmu.edu.cn/blog/4322/,任意选择以下一种方式通过Spark API 编写一个独立应用程序。 (一)使用sbt对Scala独立应用程序进行编译打包 (二)使用Maven对Java独立应用程序进行编译打包 (三)使用Maven对Scala独立应用程序进行编译打包 并截图给出代码及运行结果。