小白学习之路,基础二
一,列表,元组操作
列表在我们以后的学习中会使用很多,能够对一些数据进行快速的存储,修改删除等操作。如果学过java的同学,你会发现python中的列表类似java中的数组。下面我们简单介绍一下列表。
1.首先学会定义列表:
names=["a","b","c","d","e"]
2.对列表里面的数据就行查找
列表是通过相应数据的下标来获取对应的数据
>>> names[0] "a" >>> names[2] "c" >>> names[-1] #-1表示最后一个 "e" >>> names[-2] #还可以倒着取 "d"
一定记得下标是从0开始的哦
列表还可以取一定范围的数据,我们称为切片。
names[1:3] #查找第二个数据到第三个数据 names[-3:-1] #查找倒数第三个到倒数第二个数据 name[-3:] #查找倒数第三个到最后一个数据 name[:5] #查找第一个到第五个数据 name[::2] #查找第一个到最后一个,但是要间隔一个元素取一个
一定要记得切片是顾头不顾尾,只能取到前面的数据,后面那个取不到!!!
3.对列表的数据进行添加
对列表的添加有两种方式,一种是在指定位置加入相应数据,还有就是在列表最后面追加数据
1 names.insert(3,"4") #在第四个位置增加数据4 2 names.append("end") #在最后的一个位置添加数据end
4.对列表进行修改,删除
1 names[0]="first" #存在的数据赋值就是修改 2 3 names.remove("a") # 删除指定数据 4 del names[0] # 删除指定位置数据 5 names.pop() # 删除最后一个数据
5.列表的其他操作
1 names.index("a") #查找数据所在的位置 2 names.count("a") #统计a的个数 3 names.sort() #排序输出,一定记得python3x中不支持不同类型排序 4 names.reverse() #反转 5 #复制 6 names2=names.copy() #浅复制,只能复制第一层的东西,后面是跟复制的变化而变化 7 8 import copy 9 names2 =copy.deepcopy(names) #深度复制,不管names2怎么变化都是复制最初的数
遍历出所有列表中的数据:
for i in names: print(i) #遍历出列表中的所有数据
遍历出列表中的数据和序号
1 for index,i in enumerate(names): 2 print(index,i)
6.元组
元组其实跟列表差不多的,不过它不能被修改,所有又叫只读列表
定义方法:
names=("a","b","c")
二,字符串相关操作
字符串的相关操作太多了,我这里就列举一些比较常用的。


1 name="zzq" 2 name.capitalize() #首字母大写 3 name.count("z") #统计z的个数 4 name.center(20,"-") #打印20个字符,不够两边加- 5 name.encode() #转化为二进制 6 name.encode().decode() #二进制转化为字符编码 7 name.endswith("q") #判断是否q结尾 8 name.expandtabs(tabsize=2) #tab转化为多少空格 9 name.find("q") #找到q所在的位置索引,从最左开始 10 name.rfind("q") #找到q所在的位置索引,从最右边开始 11 name.isalpha() #判断是否全部为字母 12 name.isidentifier() #判断是不是合法的标识符 13 name.istitle() #判断首字母是否大写 14 name.upper() #全部变为大写 15 name.lower() #全部变为小写 16 "zhu zhi qiang".split("z") #按照z把前面的字符串分成列表 17 '+'.join(['1','2']) #把列表转化为字符串,中间添加+(可以自己随便定义) 18 .strip() #去掉空格跟换行符
三,字典操作
字典一种key - value 的数据类型,类似与其他语言中的键值对。在后续的学习中会大量的使用到。字典跟列表一样是无序的。
定义字典语法:
1 name={ 2 1:"zzq", 3 2:"gmx", 4 3:"aaa" 5 }
字典的增加和修改
1 name[1]="zzq43" #替换 2 name[4]="add" #添加
字典的删除和查找
1 del name[4] #删除 2 name.pop(3) #删除 3 print(name[1]) #查找 4 print(name.get(1)) #标准查找,不存在不会报错
字典可以嵌套使用,不仅仅是字典嵌套字典,还可以嵌套列表等共同使用,已达到更多的功能。
遍历字典的两种方法
1 for i in name: 2 print(i,name[i]) 3 for k,v in name.items(): #变成列表以后遍历出所有的数据 4 print(k,v)
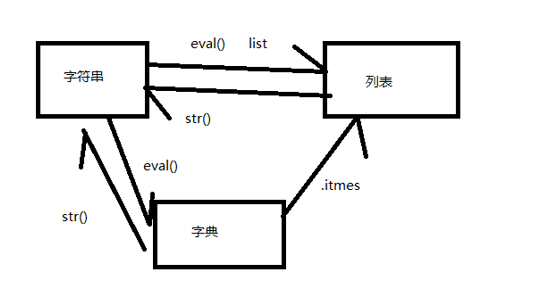
自己总结的字符串列表还有字典之间的转化关系图,图比较丑emmm,所以就将就看。
四,集合
集合也是无序的,不重复的数据集合。集合的主要作用有两个:
1.去重:把一个列表变成集合,就自动去重了
2.关系测试:测试两组数据之前的交集、差集、并集等关系
定义集合
1 #两种方法 2 name=[1,2,2,5,4,4] 3 new=set(name) 4 5 new2=set([1,2,2,5,4,4])
集合的常见操作
1 set1=set([1,2,2,3]) 2 set2=set([2,3,4,5]) 3 set1.intersection(set2) #两个集合的交集 4 set1.union(set2) #并集 5 set1.difference(set2) #差集,第一个有但是第二个没有 6 set1.issubset(set2) #判断set2是不是set1的子集 7 set1.issuperset(set2) #判断是不是父集 8 set1.symmetric_difference(set2) #对称集,输出两个集合不同的数据 9 #其他表达方式 10 set1 & set2 #表示两个集合的并集 11 set1 | set2 #表示两个集合的交集 12 set1 - set2 #表示两个集合的差集 13 set1 ^ set2 #表示两个集合的对称差集
集合的增删改操作
1 set1.add('11') #添加一个数据 2 set1.update([33,44,7]) #添加一组数据 3 set1.remove('11') #删除数据,如果没有就会报错 4 set1.discard(3) #删除数据,如果没有不会报错 5 set1.pop() #随机删除一个数据
五,文件的相关操作
文件的操作大概有打开文件,然后对文件的修改,读取,删除,写入等操作,最后执行完成关闭文件。这就是文件的基本操作流程。
1.首先先认识一下打开文件的模式有哪些:
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+,可读写文件。【可读;可写;可追加】
- w+,写读
- a+,同a
"U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)
- rU
- r+U
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
- rb
- wb
- ab
文件的基本操作
1 #只读文件操作 2 f=open('test','r',encoding='utf-8')#打开文件test,只读 3 data=f.readline() #打开文件的第一行数据 4 all_data=f.read() #读取剩下的所有文件内容 5 f.close() #关闭文件 6 #写入文件操作(文件里面有内容自动删除,然后添加新内容) 7 f=open('test','w',encoding='utf-8')#打开文件test,只写 8 f.write('hello world\n')#在文件中写入数据 9 f.close() 10 #写入文件操作(文件里面有内容,就在原来的后面追加添加的内容) 11 f=open('test','a',encoding='utf-8')#打开文件test,只写 12 f.write('hello world\n')#在文件中写入数据,如果文件有数据在文件后面追加 13 f.close() 14 #如果在前面的基础上加上一个+表示可读可写,其他功能一样
对二进制文件的操作
1 #用法跟前面的r,w,a相同,只是处理二进制文件 2 f=open('test','ab') 3 f.write(b'I Love You') #在写入的时候一定记得要是字节 4 f.write("我爱你".encode()) 5 f.close()
文件的一些基本功能操作
1 f.tell() #显示光标的位置,字节形式 2 f.seek(0) #把光标位置变为0,可以实现重读功能 3 f.flush() #时刻刷新 4 f.truncate(50) #从开始位置一直截止到50个字符的位置,只有在a的情况下才行
其他文件有用的操作
1 #因为在打开文件以后很多人忘记忘掉文件,所以还有下面这种方法 2 with open('test','r') as f: 3 print(f.read()) 4 #打开多个文件 5 with open('test','r') as f,\ 6 open('test2','r') as f2: 7 pass
六,字符编码转化
学习这个之前,先跟大家普及一下简单的知识。或者可以参考我的另外一篇博客,嘻嘻嘻,强势一个波广告。https://www.cnblogs.com/zzqit/p/9169264.html
8位(bit)=1字节(byte)
ASCII码中英文占一个字节,没有中文,只有英文和特殊字符
万国码,Unicode,英文和中文都占两个字节
Utf-8 (可变长字符编码) 英文占1个字节,中文占三个字节
编码之间的相互转换,详细文章http://www.cnblogs.com/yuanchenqi/articles/5956943.html

详细代码介绍:
1 #默认的是utf-8,如果你在解码不写的时候默认就是解码成uft-8 2 s="我爱你" 3 s_gbk=s.encode('gbk') #把Unicode转化为gbk 4 gbk_utf8=s_gbk.decode('gbk').encode('utf-8')#把gbk转化为unicode,然后变成utf-8
生活,在于选择。把自己摆在一个合适的位置,选择适合自己的生活与生存的方式,即使不是大红大紫、大富大贵,只要心是快乐的,那就是最好的。每个人都有自己的轨道,每个人也都在自己的轨道上面不停的前进。我希望每个人都能在自己选择的路上做好自己,不要在意别人的眼光,开心就好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号