编码的细微区别
在编程学习的深入后,不可避免的会遇到ANSI、GB2312、UTF8的编码问题,如果不彻底了解他们的区别,都最终会造成一个问题--乱码!想要更好的了解编码,我们首先应该了解编码的历史演变。
在继续学习之前先明白一下转化关系吧
8位bit=1字节(byte) 1024byte(字节)=1kb 1024kb=1MB 。。。。
一,ASCII码
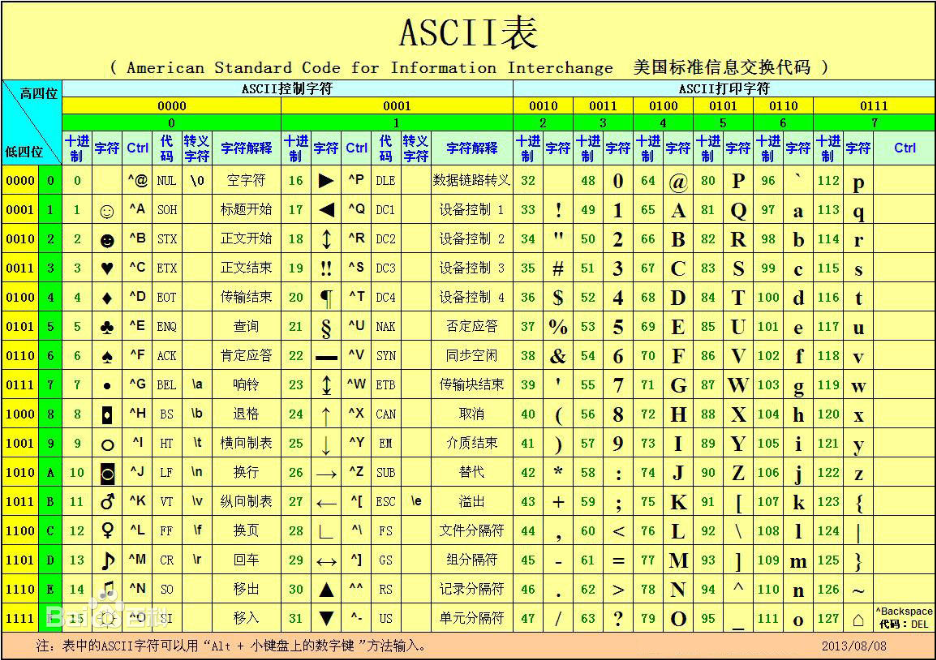
我们都知道计算机起源于美国,早期的计算机只是用于科学计算,但是在计算机迅速发展时,计算机被要求不仅仅能够进行数值计算,还要进行字符处理和表示。于是一套名为ASCII(American Standard Code for Information Interchange,美国信息互换标准代码)码的编码方式被创造而出,使用7位(bit)来表示一个字符,总共能够表示128种字符。
后来随着计算机越来越流行,这128中字符变得远远不够后来就新增了一位,变成了8位(bit)。
在ASCII码中一个字母占一个字节,不含有中文
详情请参考https://baike.baidu.com/item/ASCII/309296?fr=aladdin
二,GB2312
当计算机普及到全世界时,各个国家面临的首要问题就是要针对自己国家的语言制定一套自己国家的编码规范,我国就提出里一套针对中文的GB2312的编码方式,这套编码方式基于ASCII码(并非IBM的ASCII扩充版本),使用2个字节表示一个汉字,具体的方式是前127个字符不变。当第一个字节(高字节)大于160的时候,表示一个汉字的开始,再用这个字节组合第二个字节(低字节,范围也是160-255)共同表示一个汉字。总的来说GB2312 占2个字节,支持6700+汉字。
三,GBK
详情请参考https://baike.baidu.com/item/GBK%E5%AD%97%E5%BA%93/3910360?fr=aladdin&fromid=481954&fromtitle=GBK
中国人使用双字节(第一个字节大于127,第二个字节随意)拓展了中文的编码范畴,称为GBK编码(已经包含了GB2312的所有内容,外增加了20000多个简繁字体),以前在我国流行,现在用的也比较少了。GBK GB2312的升级版,支持21000+汉字,其中英文字母占一个字节,中文占两个字节。
四,GB18030
详情参考请https://baike.baidu.com/item/gb18030/3204518?fr=aladdin
GB18030-2005的主要特点是在GB18030-2000基础上增加了CJK统一汉字扩充B的汉字。
五,UNICODE
详情请参考https://baike.baidu.com/item/Unicode/750500?fr=aladdin
为了统一全世界的文字编码,ISO(国际标准化组织)制定了一种新的编码规范,这种编码规范将全世界的文字放在一张表内,称它为"Universal Multiple-Octet Coded Character Set",简称 UCS, 俗称"UNICODE"。请注意,Unicode和GBK、BIG5等ANSI编码仍然没有一种直接的算法进行转换,Unicode在制定时可以看成是废了所有的地区性编码,重新制定的编码,也不是从ASCII继承而来(但是前128字符仍保留为ASCII字符)。2-4字节 已经收录136690个字符,并还在一直不断扩张中。在Unicode编码中一个英文占两个字节,一个中文占两个字节。
六,utf-8
互联网兴起,UNICODE为了适应网络传输,出现了面向传输的众多 UTF(UCS Transfer Format)标准,顾名思义,UTF8就是每次8个位传输数据,而UTF16就是每次16个位,只不过为了传输时的可靠性,从UNICODE到 UTF时并不是直接的对应,而是要过一些算法和规则来转换。在utf-8编码中一个字母占1个字节,中文占三个字节。
总的来说常用的是ASCII码,utf-8,Unicode这三种编码方式,记住的是在三个中只有unicode的一个英文占两个字节,其他两个占一个字节。ASCII码中不支持中文,utf-8中文占三个字节,unicode占两个字节。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号