
通过String的不变性案例分析Java变量的可变性
阅读本文之前,请先看以下几个问题:
1、String变量是什么不变?final修饰变量时的不变性指的又是什么不变,是引用?还是内存地址?还是值?
2、java对象进行重赋值或者改变属性时在内存中是如何实现的?
3、以下是AQS中的一个方法代码,请问第一次进入这个方法时,执行到return的时候,t==node? head==tail?node.prev==head?head.next==node?这四个比较分别是true还是false?
1 private Node enq(final Node node) { 2 for (;;) { 3 Node t = tail; 4 if (t == null) { // Must initialize 5 if (compareAndSetHead(new Node())) 6 tail = head; 7 } else { 8 node.prev = t; 9 if (compareAndSetTail(t, node)) { 10 t.next = node; 11 return t; 12 } 13 } 14 } 15 }
如果你对以上几个问题统统能很清晰的答出来,那么就不用阅读本文了,否则还请慢慢读来。
正文
1、从工作中的问题出发
写这篇文章的起因,是工作中遇到了一个场景,大体是这样的。
公司项目用Apollo作为配置中心,现在有5个短信验证码的发送场景,每个场景都有最大发送次数上限,因为场景不同所以这个上限也彼此不同。每次发送短信前都会校验一下已发送次数是否已经超过这个上限,并且上限可能随时动态调整所以需要将每个场景的发送次数上限作为apollo配置项配置起来。而作为一个有追求的开发攻城狮,不能容忍通过场景码用if else这种粗糙的手段来获取配置项,所以BZ想到了Map。初步实现是这样的:
1 @Component 2 @Getter 3 public class ApolloDemo { 4 5 @Value("scene1.times") 6 private String scene1Times; 7 @Value("scene2.times") 8 private String scene2Times; 9 @Value("scene3.times") 10 private String scene3Times; 11 @Value("scene4.times") 12 private String scene4Times; 13 @Value("scene5.times") 14 private String scene5Times; 15 16 public static final Map<String, String> sceneMap = new HashMap<>(); 17 18 @PostConstruct 19 public void initMap () { 20 sceneMap.put("scene_code1", scene1Times); 21 sceneMap.put("scene_code2", scene2Times); 22 sceneMap.put("scene_code3", scene3Times); 23 sceneMap.put("scene_code4", scene4Times); 24 sceneMap.put("scene_code5", scene5Times); 25 } 26 }
但BZ是一个颇具智慧的攻城狮,这样的代码很明显存在问题:因为String是不变的,所以在initMap中初始化了Map之后,如果后续成员变量scene1Times改变了值,Map中的值是不会同步改变的。所以BZ采用了如下的改进版:
1 package com.mydemo; 2 3 import lombok.Getter; 4 import org.springframework.beans.factory.annotation.Value; 5 import org.springframework.stereotype.Component; 6 import org.springframework.stereotype.Service; 7 8 import javax.annotation.PostConstruct; 9 import java.lang.reflect.Method; 10 import java.util.HashMap; 11 import java.util.Map; 12 13 @Component 14 @Getter 15 public class ApolloDemo { 16 17 @Value("scene1.times") 18 private String scene1Times; 19 @Value("scene2.times") 20 private String scene2Times; 21 @Value("scene3.times") 22 private String scene3Times; 23 @Value("scene4.times") 24 private String scene4Times; 25 @Value("scene5.times") 26 private String scene5Times; 27 28 private static final Map<String, String> sceneMap = new HashMap<>(); 29 30 @PostConstruct 31 public void initMap () { 32 sceneMap.put("scene_code1", "getScene1Times"); 33 sceneMap.put("scene_code2", "getScene2Times"); 34 sceneMap.put("scene_code3", "getScene3Times"); 35 sceneMap.put("scene_code4", "getScene4Times"); 36 sceneMap.put("scene_code5", "getScene5Times"); 37 } 38 39 public String getTimesByScene(String sceneCode){ 40 String methodName = sceneMap.get(sceneCode); 41 try { 42 Method method = ApolloDemo.class.getMethod(methodName); 43 Object result = method.invoke(this, null); 44 return (String)result; 45 } catch (Exception e) { 46 e.printStackTrace(); 47 } 48 return ""; 49 } 50 }
通过反射调用get方法来获取实时的apollo配置值,功能算是交付出去了。但问题却刚刚开始。
我们都知道String是不可变的,那它为什么不可变呢?因为它的类由final修饰不可继承,而它用于存放字符串的成员变量char[]也是由final修饰的。继续追问,final修饰的变量不可变是指什么不可变?不可变有两种,一种是引用不可变,一种是值不可变。此处答案是引用不可变。其实Java中,不管是给对象赋值,还是给对象中的属性赋值,赋的值其实都是引用。针对String的不可变是引用不可变的结论,通过一个例子就可以证明:
1 public static void main(String[] args) { 2 String text = "text"; 3 System.out.println(text); 4 try { 5 Field value = text.getClass().getDeclaredField("value"); 6 value.setAccessible(true); 7 char[] valueArr = (char[])value.get(text); 8 valueArr[1]='a'; 9 } catch (Exception e) { 10 e.printStackTrace(); 11 } 12 System.out.println(text); 13 }
执行结果:
text
taxt
BZ通过反射改变了String的值,说明它的值是可变的,如果用反射执行 value.set(text, "aaa"),则会报错不让改,即引用不可变。
由此问题1得到了解答,内存地址只是用于迷惑人的,一个对象创建完成之后,其内存地址是不可改变的,直到被回收后重新分配。
2、问题2与问题3一起分析
针对问题3的方法,BZ用内存示意图来分析:
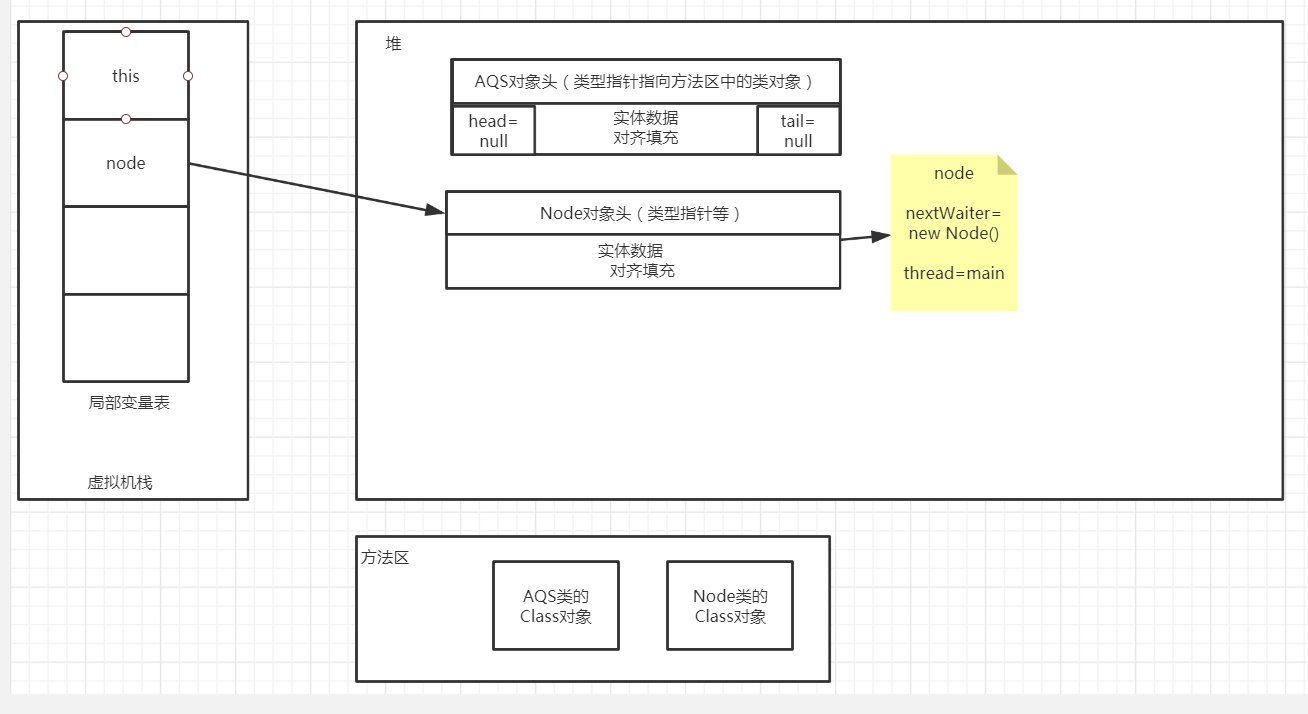
1)、刚进入enq方法时,tail、head、node的内存布局是这样:
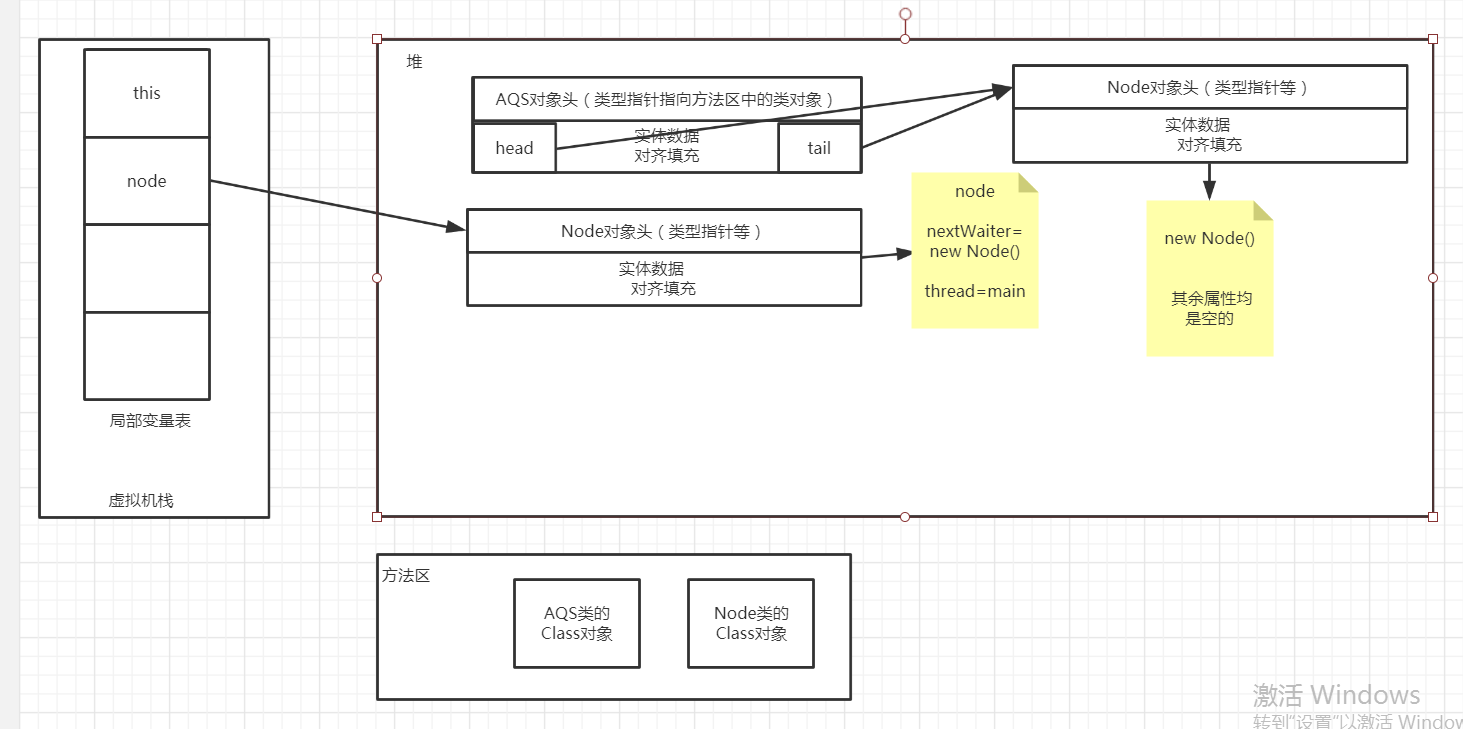
2)、走完第一遍循环并之后,完成了对head和tail的赋值,此时内存分布是这样:
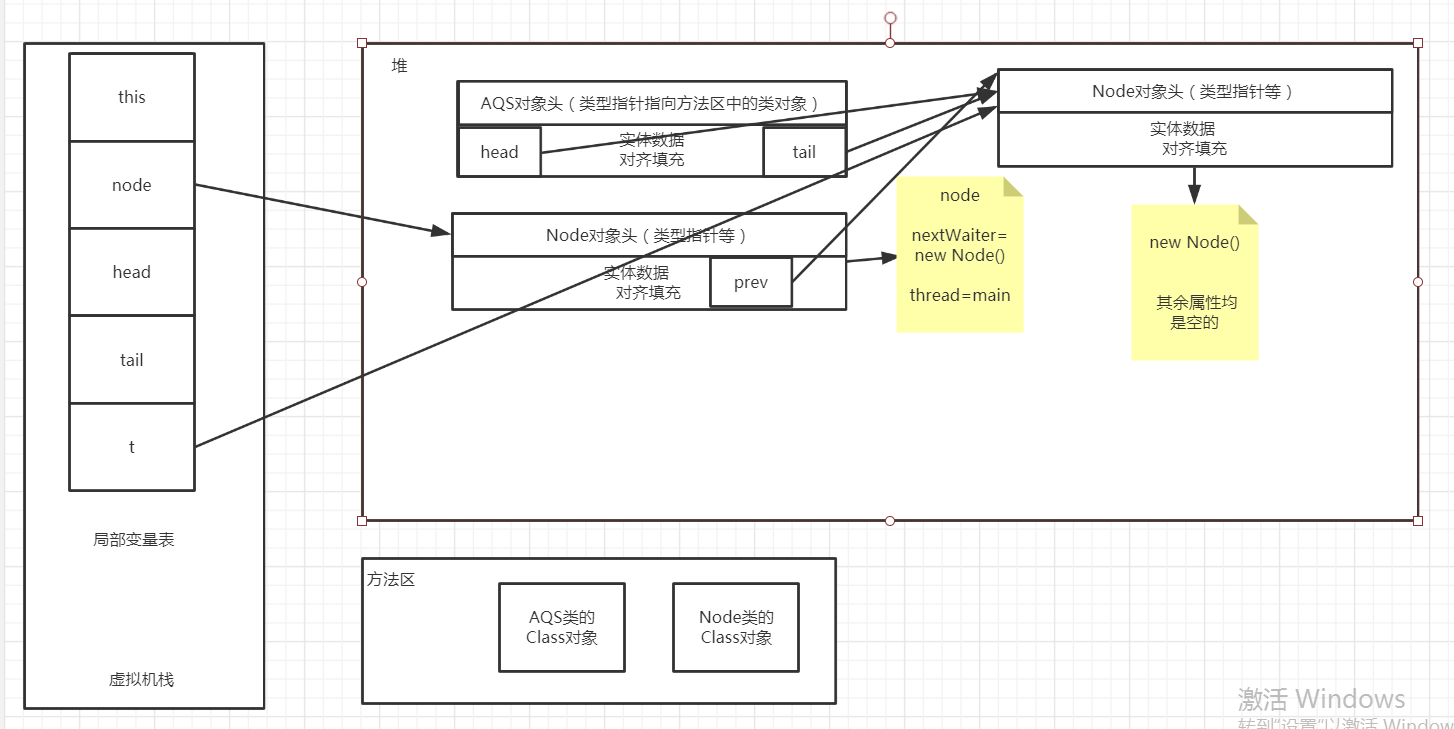
3)、进入第二遍循环中,走完第三行代码 Node t = tail 和node.prev=t之后的内存分布如下,因为赋值都是引用赋值,所以局部变量t和node.prev均指向了new Node()的引用地址。
4)、走完CAS tail之后是这样,即CAS是将tail的引用从new Node()改为了 node:

5)、走完最后一行t.next=node,内存分布如下所示,t指向的一直都是new Node(),而将node赋值给t.next之后,node和new Node()就组成了一个双向链表,new Node()是头,正好head指向它;node是尾,正好tail指向它,至此完成了AQS中双向链表的构建。
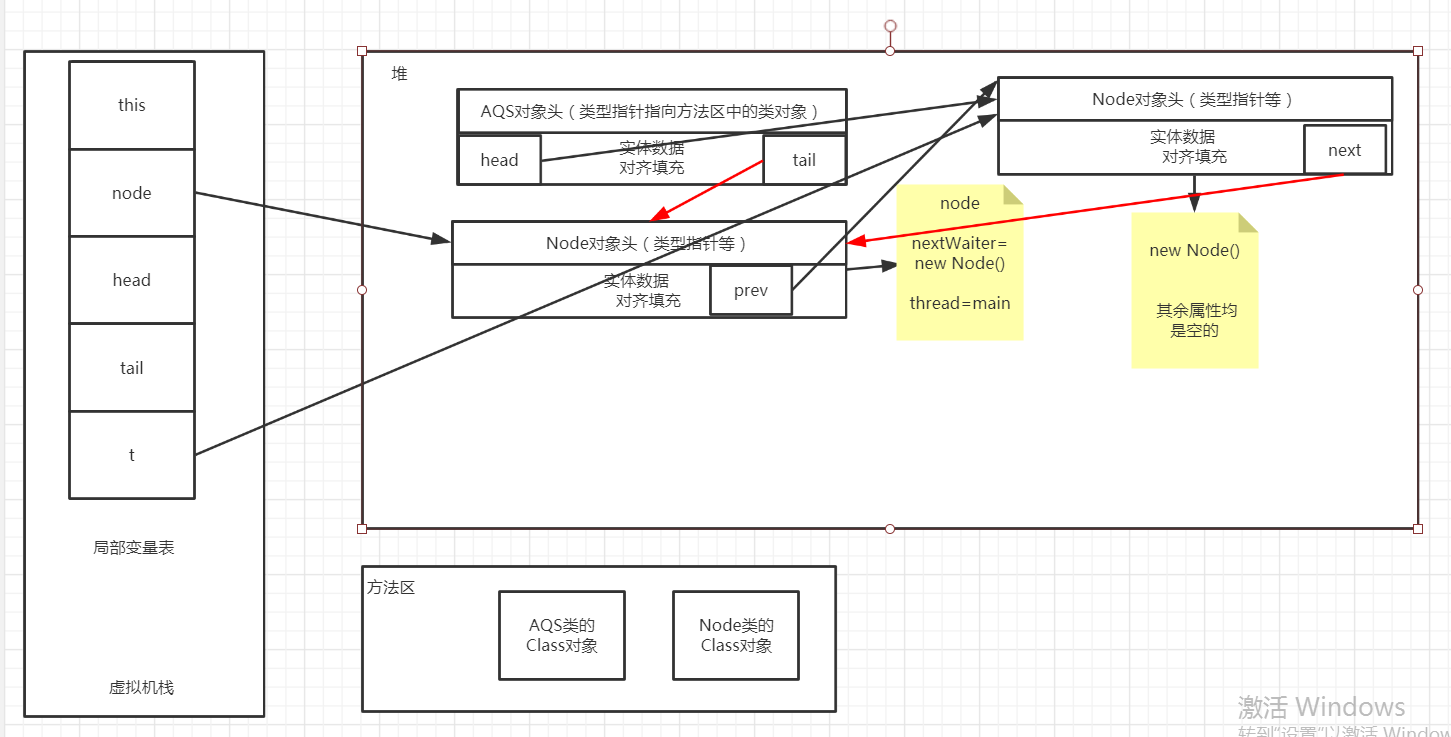
通过上面5张截图的变化,相信能对于问题2已经有答案了,至于问题3的答案,看最后一张图也就水落石出了,t==node? head==tail?node.prev==head?head.next==node?答案分别是:false;false;true;true。
本文到此为止,其中有描述不清楚的或者理解不到位的地方,还请各位看官批评指正,谢谢!
-------------------------------------------------------------2020-05-01补充分割线--------------------------------------------------------------------------
前两天偶然翻到Hollis发的一篇技术文章,探讨Java是值传递还是引用传递,Hollis不愧是年年纪最轻的阿里P8,在那篇文章中算是把Java值传递给讲清楚了,也是消除了BZ一直以来困扰在内心的疑云,下面BZ继续上面的话题,继续深入探讨下Java的值传递还是引用传递问题。如果想看原文,请关注公众号Hollis,搜文章题目【我要彻底给你讲清楚,Java就是值传递,不接受争辩的那种】。
在上文中,BZ有一句话是这样写的【不管是给对象赋值,还是给对象中的属性赋值,赋的值其实都是引用】。这句话其实没问题,但是会引起误解。
在严格求值策略中(对,你没看错,我们经常讨论的值传递还是引用传递,其对应的专有名词就叫求值策略,不理解没关系,先记住),有三种核心的求值策略,分别是:传值调用、传引用调用和传共享对象调用。
传值调用比较好理解,Java中的基本类型传递就是用的它。对于传引用调用,是指将对象的实际引用直接传给另一个变量(只看这一句解释可能看不出来关键,且看后面的例子)。对于第三种传共享对象调用,是指将对象的引用复制一份,给另一个对象赋值。这种求值策略传递的是引用的值,被划分到传值策略下面,是传值策略的一种特例。Java处理对象时用的就是这第三种求值策略。下面用一个伪代码来论证一下。
Object A = new Object();
Object B = A;
Object B = new Object();
此时如果是第二种引用传递,因为传递的就是A的引用本身,所以在完成B=new Object()的赋值之后,传递的A的引用就变成了另一个新的引用。但实测时会发现,A的引用还是A,只有B的引用变成了新的。由此可以得出结论,Java中传递的不是引用本身,而是引用的副本,副本改变了不会对原有引用造成影响,而且副本跟原引用都指向同一个对象,这个对象变化了副本引用和原引用都能感知到变化。
至此,本话题结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号