
spark核心优化详解
大家好!转眼又到了经验分享的时间了。吼吼,我这里没有摘要也没有引言,只有单纯的经验分享,请见谅哦!
言归正传,目前在大数据领域能够提供的核心计算的工具,如离线计算hadoop生态圈的mr计算模型,以及依赖mr的hive;在spark生态圈中包含spark core和spark sql。实时计算领域中有storm和spark streaming。
那么单纯看技术核心,本质上就是mr和spark 两种计算模型的竞争,那么storm会在以后的分享中提及,这里不做介绍。
之前很多人都在呼吁说spark的时代已经来临了,他将要代替hadoop了;呵呵,老生常谈这些并没有实际的意义,不过spark在逐渐的替换掉mr计算模型确实真的,也许非常古老又没有什么要求的mr作业仍然在企业中运行;这样的情况或许半年你都不会在去碰它;因为越来越多的数据公司已经都在转向用spark了。但也有人会说hadoop也是有专门的组织来维护,而且也在稳步的升中,所以mr效率会越来越高的;这个说法显然难以站住脚,毕竟无论怎样升级也只能解决mr的边边角角,而shuffle阶段的原理,写磁盘和文件排序是没有改变的,所以说mr也不可能有质的飞跃,如果有本质的改变那也应该重新起个名字。
不过说起spark相对比于mr确实快了很多,也方便了很多;一快一方便也使大家对spark越来越喜爱,其实在spark1.3.x以后就已经比较稳定了,所以才导致了现在越来越多的公司已经用上了1.5.x以及1.6.x的版本,而且spark的运行精髓就是依赖于内存,相比如今的数据价值,内存的在金钱上的花销已经越来越微不足道了。
大数据的内存处理是提高计算效率,节省时间的不二之选,所以说spark的出现显得至关重要,那么spark它的设计思想也解决了mr的弊端;
Shuffle结果
Spark的map操作和reduce操作是同时进行的,也就是说只有前一个stage和后一个stage之间才会有io操作,并且可以指定使用HashShuffleManager来避免sort操作,当然这是在你不需要排序的前提,退一步讲即使你需要排序,我们也可以使用自定义二次排序来处理后期的结果。
链式操作
Spark相比于mr使用弹性分布式数据集进行迭代的处理,每一次处理的结果会在集群内存中形成一份处理后的数据,该数据可持久化可缓存可跌带操作;这也反面对比出mr反复写文件,排序,读取文件的缓慢io操作。
生态圈更完善,社区活跃
Spark的强大之处更在于它完整性,支持核心编程的同时也支持类sql的操作,也提供了准实时的计算引擎;而且更重要的是不同的技术分支都依赖于spark core。相比集成mr hive storm成本上,兼容性上也都要强出很多。
易用性
Client支持多种语言,而且与hdfs以及hbase集成容易。
缺点
如果是超大级别的数据集,并且对于时效性基本没有要求,那么mr和hive 则是首选,毕海量级别的数据会带来极大的内存开销。
==============华丽分割线==============
通过spark的设计思想以及内存的计算模型确实能够弥补mr所带来的不足,官方给出spark要比mr快10~100倍,这个并不代表你直接写好了程序,马上运行就会比mr效率好很多;而是要做出相应的配置,所以这也是spark作业优化的重点。
提起spark优化重点,相信很多“技术控”直接就会谈到特别炫酷的:
- “随机key打散”
- “自定义broadcast代替join算子”
- “抽样倾斜数据单独join”
- “reduceByKey代替groupByKey”
- “Jvm堆外内存大小调整”
- “减少ShuffleMapTask的io次数”
。。。。等等。。。当然优化spark作业的运行,并不能说以上方法不可以,在出现数据倾斜或者聚合运算优化的时候当然是没有问题的,但是我们在谈及这些优化之前,还有很多基础的设置需要做,也可以说只有这些基础的东西落实了,才能在提及一上的应用优化方案;而且又不得不说当基础的核心优化配置好了以后你的spark应用就已经很快了(这点我非常确定)。以上的方案也只是起到了”锦上添花”的作用。
资源的分配和并行度的配置
对于一个spark应用最最重要的就是能够充分利用所分配的资源,那么我们有3个问题:
1:分配哪些资源?
2:在哪里分配资源?
3:为什么分配了资源以后能得到性能的提升?
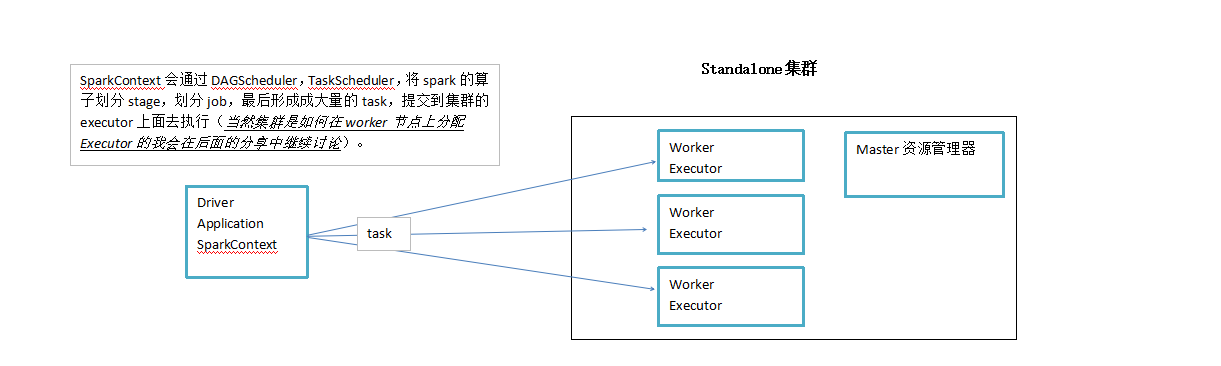
我们以standalone的运行环境举例,提交spark作业的时候我们需要使用submit shell来启动,内容如下:
/usr/local/spark/bin/spark-submit \
--class com.safe.lu.sparkcore.area \
--num-executors 10 \ 配置executor的数量
--driver-memory 4096m \ 配置driver的内存
--executor-memory 10240m \ 配置每个executor的内存大小
--executor-cores 5 \ 配置每个executor的cpu core数量
/usr/local/area-1.0.1-jar-with-dependencies.jar \
通过上面的配置节我们可以看出分配资源的位置共有4处
1:executor个数
2:每个executor所占用的内存
3:每个executor所拥有的核心数
4:driver client的内存大小
分配资源的位置已经明确,下一个问题是我们怎么样去配置这些数值呢?
第一种:以standalone为例,你的spark应用一定要清楚,管理员在集群中能够允许你使用多少内存,多少cpu core,然后在设置的时候就根据这个实际的情况,去调节每个spark作业的实际资源分配。
第二种:如果运行环境为yarn,要看提供的资源队列有多少资源,对应去设置就可以了。
一个原则就是资源有多大,就去调节到最大的大小。
那么分配了更多资源后为什么会提升性能,我们从作业运行的角度去解释下。
1:增加executor:
如果executor数量比较少,那么,能够并行执行的task数量就比较少,就意味着spark 作业的并行执行的能力就很弱。
比如有5个executor,每个executor有2个cpu core,那么同时能够并行执行的task,就是10个。10个执行完以后,再换下一批10个task。那么增加了executor数量以后,就意味着,能够并行执行的task数量,也就变多了。比如原先是10个,现在可能可以并行执行20个,甚至30个,100个。那么并行能力就比之前提升了数倍,数十倍。相应的,性能(执行的速度),也能提升数十倍。
2:增加每个executor的内存量:
如果需要对RDD进行cache,那么更多的内存,就可以缓存更多的数据,将更少的数据写入磁盘,甚至不写入磁盘。减少了磁盘IO。
对于shuffle操作resultTask端,会需要内存来存放拉取的数据并进行聚合。如果内存不够,也会写入磁盘。如果给executor分配更多内存以后,就有更少的数据落入磁盘,当然如果内存足够大甚至不需要写入磁盘,从而减少了磁盘IO,提升了执行性能。
而且对于Task在executor中执行时如果内存不够,可能会导致JVM频繁的垃圾回收发生,这样也会拖慢spark app整体的执行速度,而且在这个时候你如果不多次测试调整,shuffle拉取参数,和map端的输出策略则很有可能会莫名奇妙的出现 not found blockfile等异常,而且不定时发生,非常令人头疼,所以下篇文章中我还会分享shuffle阶段可能会出现的近10种问题。
“。。。。。。说到这里不得不吐槽下,spark的执行各个环节问题确实很多,相比mr作业来说想把spark app成功并稳定的运行确实不容易,因为spark的调整点实在太多,如果你的app运行环境不满足,那就会各种出问题,此时并不是说你的程序写的多优美可以解决的,吼吼!所以要求应该对其各个环节的行为有所掌握。
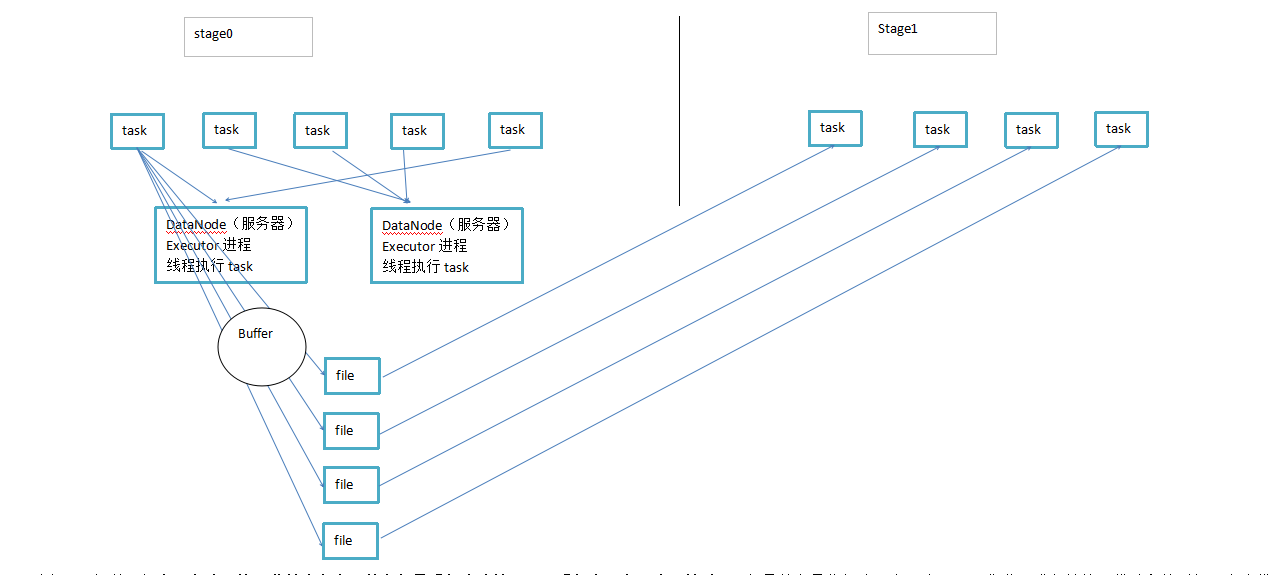
在这里还应该去sparkContext中去配置并行度,“而且并行度的设置需要高于你的cpu core的数量,这样就不会发生一批任务执行完毕后,某个cpu出现空闲的问题,提高并行度意味着提高了同时计算的能力”,而且task的并行执行数量多了也就意味着ShuffleMapTask多了的同时,ResultTask的数量也是增多的,那么Shuffle阶段的性能也会成倍的提升,执行基本原理如下(并行度为4):
到这里还想说一句真正有分量的一些技术和点,其实都是看起来比较平凡,看起来没有那么“炫酷”,但是其实是你每次写完一个spark作业,进入性能调优阶段的时候,应该优先调节的事情,就是这些!(大部分时候,可能资源和并行度到位了,spark作业就真的很快了)
弹性分布式数据集的重用处理
每当说到rdd真的是又一次想去赞美spark设计的美妙了;他让我们能够在每一个处理阶段形成一个DataSet,而每一个DataSet之间你可以去抽样持久化mysql,持久化HBase,可以去做任何事儿,方便的同时我们又发现另一个重要的问题,如下图:

上面的执行流程很清晰,无非就是rdd3 和 rdd2 同时用到了rdd1;默认情况下,多次对一个RDD执行算子,去获取不同的RDD;都会对这个RDD以及之前的父RDD,全部重新计算一次;这样一来看起来就有点“灾难”了;这种情况,是一定要避免的,一旦出现一个rdd重复计算的情况,就会导致性能急剧降低,因为依赖的rdd都是要重新进算。
如果HDFS->RDD0-RDD1的时间是10分钟,那么此时就要走两遍,就变成20分钟了。
所以在RDD的操作这块要特别的注意:
1:尽量去复用RDD,十分相似的RDD,可以抽取称为一个共同的RDD,供后面的RDD计算时,反复使用。
2:对于要多次计算和使用的公共RDD,一定要进行持久化,也就是将RDD的数据缓存到内存中/磁盘中,(BlockManager),以后无论对这个RDD做多少次计算,那么都是直接取这个RDD的持久化的数据,比如从内存中或者磁盘中,直接提取一份数据。
3:持久化的数据也是可以进行序列化的,正常将数据持久化在内存中,那么可能会导致内存的占用过大,也许会导致OOM;内存无法支撑公共RDD数据完全存放的时候,优先考虑使用序列化的方式在纯内存中存储。将RDD的每个partition的数据,序列化成一个大的字节数组,就一个对象;序列化后,大大减少内存的空间占用,“下一篇文章我也会继续介绍序列化的优化方案”,序列化唯一的缺点就是,在获取数据的时候,需要反序列化。
。
4:如果序列化单纯内存存储方式还是导致OOM,也可以使用“内存+磁盘”的方式进行存储,这时也可以不进行序列化。
5:如果是在内存十分充足的情况下(仅仅内存极度充足),也可以使用双副本缓存机制,这样避免第一次cache丢失后的重新计算。
广播变量处理task执行的算子中引入的外部变量
先做一个场景举例说明,比如你现在统计全国不同区域的“贷款总数”,但你在清洗出的日志中只能拿到区域的key,这个时候另一个人告诉你区域的字典数据在redis或者在HBase中,那么这个时候你可能要在diver中存储一份数据,然后在spark算子中去获取这个变量,从而根据key值来得到实际的地区名称。
Broadcast适合将“大变量”广播出去。而不是直接使用;Broadcast初始的时候仅仅在Drvier上有一份副本。
task在运行的时候,想要使用广播变量中的数据,此时首先会在自己本地的Executor对应的BlockManager中,尝试获取变量副本;如果本地没有,那么就从Driver远程拉取变量副本,并保存在本地的BlockManager中;此后这个executor上的task,都会直接使用本地的BlockManager中的副本。

对于“大变量”广播变量的好处,不是每个task一份变量副本,而是变成每个节点的executor才保存一份副本。这样的话,就可以让变量产生的副本大大减少。
到了这里spark的核心优化最根本点已经基本做到了,这个时候其实你的spark作业就已经会很快了;这些看似非常普通的操作和设计确是spark作业最最关键的点,像shuffle优化,具体的数据倾斜优化确实很“炫酷”;但是在做这些之前,千万不要忘记最最核心最最基本的优化点,不应该本末倒置。
当然对于spark的shuffle优化,序列化优化,算子优化等等,可能还有几个甚至十几个点在这里暂时不过多的阐述,因为做好了核心的优化才是将spark应用效率成倍提升的关键,其它优化点虽然也比较重要,但或许只能让spark作业从30分钟提升到25分钟。
如果有人对spark内存数据处理比较感兴趣的话,后面我会继续分享并详细剖析shuffle阶段的关键点,以及发生数据倾斜优化策略,以及向worker动态分配executor策略,BlockManager的工作原理等等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号