

第三次作业词频统计
个人信息:
姓名:张执鹏程
学号:2017*******90
码云仓库:https://gitee.com/zhangzpcword_frequency
程序分析:
1.在python中导入string中的punctuation包
from string import punctuation
2.读文件到缓冲区,打开文件
def process_file(dst): # 读件到缓冲区 try: # 打开文件 f1=open(dst,"r") except IOError as s: print (s) return None try: # 读文件到缓冲区 bvffer=f1.read() except: print ("Read File Error!") return None f1.close() return bvffer
3.设置缓冲区,并进行数字处理
def process_buffer(bvffer): if bvffer: word_freq = {} # 下面添加处理缓冲区 bvffer的代码,统计每个单词的频率,存放在字典word_freq bvffer=bvffer.lower() for x in '~!@#$%^&*()_+/*-+\][': bvffer=bvffer.replace(x, " ") words=bvffer.strip().split() for word in words: word_freq[word]=word_freq.get(word,0)+1 return word_freq
4.设置可以输出前十个单词的函数
def output_result(word_freq): if word_freq: sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:10]: # 输出 Top 10 的单词 print(item)
5.封装函数
if __name__ == "__main__": import argparse parser = argparse.ArgumentParser() parser.add_argument('dst') args = parser.parse_args() dst = args.dst bvffer = process_file(dst) word_freq = process_buffer(bvffer) output_result(word_freq)
性能分析:
1.词频统计的前十:
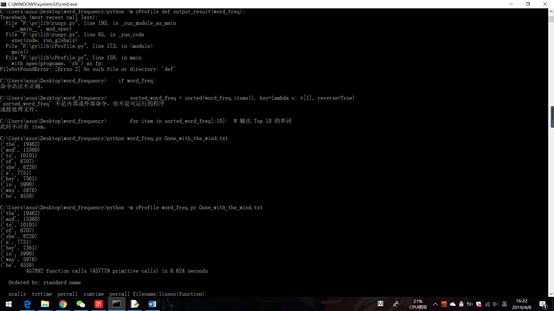
2.执行最正确次数最多的代码
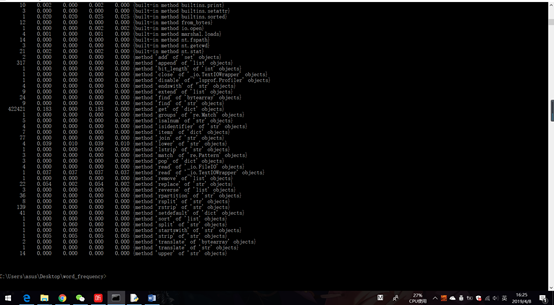
3.执行时间最长的代码:

总结:
让我学会了git的新用法,并且让我对python有了更加深入的了解,以后我也会努力的!!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号