
requrets、re实现简单爬虫
开发环境:python 3.8.0+requests+pygame+ReNamer Pro
简介:爬取网络电子书籍,按章节名称写入每一章的内容(且按章节名排序),存于电子书名文件夹下。
效果:
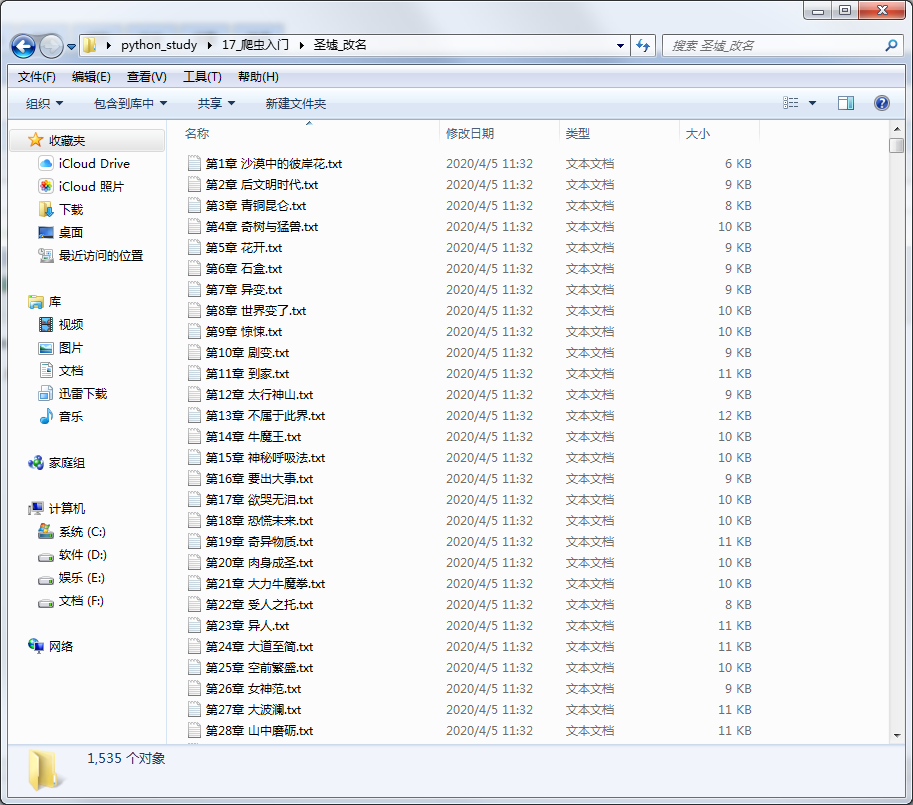
代码如下:
1 import requests 2 import re 3 import os 4 5 # 1.获取电子书目录页HTML代码 6 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'} 7 response = requests.get('http://www.xqishuta.com/du/36/36878/', headers=headers) 8 html = response.content.decode('utf-8') 9 # print(html) 10 11 # 2.re获取每一章节的URL 12 urls = re.findall('<a href="(.*?)">.*? .*?</a>', html) 13 urls1 = urls[20:-1] 14 15 # 3.re获取每一章节的名称 16 urss = re.findall('<a href=".*?">(.*? .*?)</a>', html) 17 urss1 = urss[20:-1] 18 print(urss1[0]) 19 20 # 按书籍名创建文件夹 21 dir_name = ['圣墟'][0] 22 if not os.path.exists(dir_name): 23 os.mkdir(dir_name) 24 25 # 4.循环获取每一章节HTML代码 26 i = 0 27 while i < len(urss1): 28 # response1 = requests.get(("http://www.xqishuta.com/du/36/36878/" + urls1[i])) 29 # # print("http://www.xqishuta.com/du/36/36878/" + urls1[i]) 30 # print(response1) 31 response = requests.get(str("http://www.xqishuta.com/du/36/36878/" + str(urls1[i])), headers=headers).content.decode('utf-8') 32 # re获取每一章节的内容 33 content = re.findall('.*?.*?<p class=".*?">', response) 34 # 内容清洗 35 text = re.sub("[A-Za-z0-9\!\%\[\]\,\:<\/\\\< >\=""'\"\"]", "", str(content)).encode('utf-8') 36 37 # 5.按章节名称写入每一章的内容 38 with open(dir_name + '/' + urss1[i] + '.txt', 'wb') as f: 39 f.write(text)40 # 打印已经完成的章节的URL 41 print(urls1[i]) 42 43 i += 1
最后:由于这本电子书籍章节名称前一千多章章节排序名称为中文,后面为数字,造成文件夹中排序上错乱。效果是这样的,强迫症表示看着非常难受
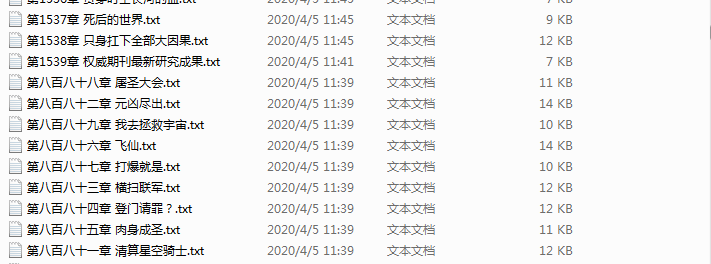
于是网上找来一软件为ReNamer Pro将中文排序改为了数字排序,用的是里面的名称替换。
思路很简单,全部拖入后一换1....十、百、千替换成空,然后特殊的(比如第十章,第一百章,第一千章等)取消选中,重命名后特殊名称的分批替换。都重命名后排序效果如最上图,看着非常舒适。
链接: https://pan.baidu.com/s/1tRr2f7XUJ5oCLX2zUS-UQA 提取码: qpif

 浙公网安备 33010602011771号
浙公网安备 33010602011771号