

Spark SQL笔记整理(二):DataFrame编程模型与操作案例
DataFrame原理与解析
Spark SQL和DataFrame
1、Spark SQL是Spark中的一个模块,主要用于进行结构化数据的处理。它提供的最核心的编程抽象,就是DataFrame。同时Spark SQL还可以作为分布式的SQL查询引擎。Spark SQL最重要的功能之一,就是从Hive中查询数据。
2、DataFrame
就易用性而言,对比传统的MapReduce API,说Spark的RDD API有了数量级的飞跃并不为过。然而,对于没有MapReduce和函数式编程经验的新手来说,RDD API仍然存在着一定的门槛。另一方面,数据科学家们所熟悉的R、Pandas等传统数据框架虽然提供了直观的API,却局限于单机处理,无法胜任大数据场景。为了解决这一矛盾,Spark SQL 原有SchemaRDD的基础上提供了与R和Pandas风格类似的DataFrame API。新的DataFrame API不仅可以大幅度降低普通开发者的学习门槛,同时还支持Scala、Java与Python三种语言。更重要的是,由于脱胎自SchemaRDD,DataFrame天然适用于分布式大数据场景。
DataFrame原理解析
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。
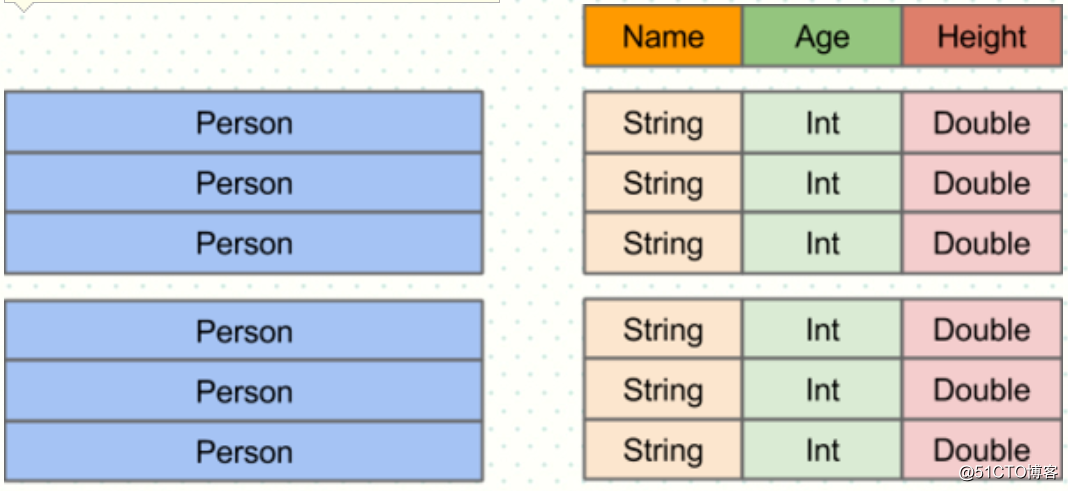
DataFrame基本操作案例
Spark SQLContext
要使用Spark SQL,首先就得创建一个创建一个SQLContext对象,或者是它的子类的对象,比如HiveContext的对象。
Java版本:
JavaSparkContext sc = ...;
SQLContext sqlContext = new SQLContext(sc);Scala版本:
val sc: SparkContext = ...
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._Spark HiveContext
1、除了基本的SQLContext以外,还可以使用它的子类——HiveContext。HiveContext的功能除了包含SQLContext提供的所有功能之外,还包括了额外的专门针对Hive的一些功能。这些额外功能包括:使用HiveQL语法来编写和执行SQL,使用Hive中的UDF函数,从Hive表中读取数据。
2、要使用HiveContext,就必须预先安装好Hive,SQLContext支持的数据源,HiveContext也同样支持——而不只是支持Hive。对于Spark 1.3.x以上的版本,都推荐使用HiveContext,因为其功能更加丰富和完善。
3、Spark SQL还支持用spark.sql.dialect参数设置SQL的方言。使用SQLContext的setConf()即可进行设置。对于SQLContext,它只支持“sql”一种方言。对于HiveContext,它默认的方言是“hiveql”。
创建DataFrame
使用SQLContext或者HiveContext,可以从RDD、Hive、ZMQ、Kafka和RabbitMQ等或者其他数据源,来创建一个DataFrame。我们来举例使用JSON文件为例创建一个DataFrame。
Java版本:
JavaSparkContext sc = new JavaSparkContext();
SQLContext sqlContext = new SQLContext(sc);
DataFrame df = sqlContext.read().json("hdfs://ns1/spark/sql/person.json");
df.show();Scala版本:
val sc: SparkContext = new SparkContext();
val sqlContext = new SQLContext(sc)
val df = sqlContext.read.json(" hdfs://ns1/spark/sql/person.json")
df.show()案例
json数据如下:
{"name":"Michael", "age":10, "height": 168.8}
{"name":"Andy", "age":30, "height": 168.8}
{"name":"Justin", "age":19, "height": 169.8}
{"name":"Jack", "age":32, "height": 188.8}
{"name":"John", "age":10, "height": 158.8}
{"name":"Domu", "age":19, "height": 179.8}
{"name":"袁帅", "age":13, "height": 179.8}
{"name":"殷杰", "age":30, "height": 175.8}
{"name":"孙瑞", "age":19, "height": 179.9}测试代码如下:
package cn.xpleaf.bigdata.spark.scala.sql.p1
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.{Column, DataFrame, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* SparkSQL基础操作学习
* 操作SparkSQL的核心就是DataFrame,DataFrame带了一张内存中的二维表,包括元数据信息和表数据
*/
object _01SparkSQLOps {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
val conf = new SparkConf().setMaster("local[2]").setAppName(_01SparkSQLOps.getClass.getSimpleName)
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val df:DataFrame = sqlContext.read.json("D:/data/spark/sql/people.json")
// 1.打印DF中所有的记录
println("1.打印DF中所有的记录")
df.show() // 默认的输出表中数据的操作,相当于db中select * from t limit 20
// 2.打印出DF中所有的schema信息
println("2.打印出DF中所有的schema信息")
df.printSchema()
// 3.查询出name的列并打印出来 select name from t
// df.select("name").show()
println("3.查询出name的列并打印出来")
df.select(new Column("name")).show()
// 4.过滤并打印出年龄超过14岁的人
println("4.过滤并打印出年龄超过14岁的人")
df.select(new Column("name"), new Column("age")).where("age>14").show()
// 5.给每个人的年龄都加上10岁
println("5.给每个人的年龄都加上10岁")
df.select(new Column("name"), new Column("age").+(10).as("10年后的年龄")).show()
// 6.按照身高进行分组
println("6.按照身高进行分组") // select height, count(1) from t group by height;
df.select(new Column("height")).groupBy(new Column("height")).count().show()
// 注册表
df.registerTempTable("people")
// 执行sql操作
var sql = "select height, count(1) from people group by height"
sqlContext.sql(sql).show()
sc.stop()
}
}输出结果如下:
1.打印DF中所有的记录
18/05/08 16:06:09 INFO FileInputFormat: Total input paths to process : 1
+---+------+-------+
|age|height| name|
+---+------+-------+
| 10| 168.8|Michael|
| 30| 168.8| Andy|
| 19| 169.8| Justin|
| 32| 188.8| Jack|
| 10| 158.8| John|
| 19| 179.8| Domu|
| 13| 179.8| 袁帅|
| 30| 175.8| 殷杰|
| 19| 179.9| 孙瑞|
+---+------+-------+
2.打印出DF中所有的schema信息
root
|-- age: long (nullable = true)
|-- height: double (nullable = true)
|-- name: string (nullable = true)
3.查询出name的列并打印出来
18/05/08 16:06:10 INFO FileInputFormat: Total input paths to process : 1
+-------+
| name|
+-------+
|Michael|
| Andy|
| Justin|
| Jack|
| John|
| Domu|
| 袁帅|
| 殷杰|
| 孙瑞|
+-------+
4.过滤并打印出年龄超过14岁的人
18/05/08 16:06:10 INFO FileInputFormat: Total input paths to process : 1
+------+---+
| name|age|
+------+---+
| Andy| 30|
|Justin| 19|
| Jack| 32|
| Domu| 19|
| 殷杰| 30|
| 孙瑞| 19|
+------+---+
5.给每个人的年龄都加上10岁
18/05/08 16:06:10 INFO FileInputFormat: Total input paths to process : 1
+-------+-------+
| name|10年后的年龄|
+-------+-------+
|Michael| 20|
| Andy| 40|
| Justin| 29|
| Jack| 42|
| John| 20|
| Domu| 29|
| 袁帅| 23|
| 殷杰| 40|
| 孙瑞| 29|
+-------+-------+
6.按照身高进行分组
18/05/08 16:06:11 INFO FileInputFormat: Total input paths to process : 1
+------+-----+
|height|count|
+------+-----+
| 179.9| 1|
| 188.8| 1|
| 158.8| 1|
| 179.8| 2|
| 169.8| 1|
| 168.8| 2|
| 175.8| 1|
+------+-----+
18/05/08 16:06:14 INFO FileInputFormat: Total input paths to process : 1
+------+---+
|height|_c1|
+------+---+
| 179.9| 1|
| 188.8| 1|
| 158.8| 1|
| 179.8| 2|
| 169.8| 1|
| 168.8| 2|
| 175.8| 1|
+------+---+DataFrame与RDD之间的转化案例与解析(Java、Scala)
相关使用数据
下面涉及的测试代码中,需要使用到的源数据sql-rdd-source.txt,如下:
1, zhangsan, 13, 175
2, lisi, 14, 180
3, wangwu, 15, 175
4, zhaoliu, 16, 195
5, zhouqi, 17, 165
6, weiba, 18, 155使用到的Person类,代码如下:
public class Person {
private int id;
private String name;
private int age;
private double height;
public Person() {
}
public Person(int id, String name, int age, double height) {
this.id = id;
this.name = name;
this.age = age;
this.height = height;
}
}利用反射机制将RDD转为DataFrame
1、一个问题就摆在大家的面前:为什么要将RDD转换为DataFrame呀?
主要是能使用Spark SQL进行SQL查询了。这个功能是无比强大的。
2、是使用反射机制推断包含了特定数据类型的RDD的元数据。这种基于反射的方式,代码比较简洁,事前知道要定义的POJO的元数据信息,当你已经知道你的RDD的元数据时,是一种非常不错的方式。
使用反射机制推断元数据
1、Java版本:
Spark SQL是支持将包含了POJO的RDD转换为DataFrame的。POJO的信息,就定义了元数据。Spark SQL现在是不支持将包含了嵌套POJO或者List等复杂数据的POJO,作为元数据的。只支持一个包含简单数据类型的field的POJO。
2、Scala版本:
而Scala由于其具有隐式转换的特性,所以Spark SQL的Scala接口,是支持自动将包含了case class的RDD转换为DataFrame的。case class就定义了元数据。Spark SQL会通过反射读取传递给case class的参数的名称,然后将其作为列名。
不同点:
3、与Java不同的是,Spark SQL是支持将包含了嵌套数据结构的case class作为元数据的,比如包含了Array等。
Scala版
测试代码如下:
package cn.xpleaf.bigdata.spark.scala.sql.p1
import java.util
import java.util.{Arrays, List}
import cn.xpleaf.bigdata.spark.java.sql.p1.Person
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{DataFrame, SQLContext}
/**
* SparkRDD与DataFrame之间的转换操作
* 1.通过反射的方式,将RDD转换为DataFrame
* 2.通过动态编程的方式将RDD转换为DataFrame
* 这里演示的是第1种
*/
object _02SparkRDD2DataFrame {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
val conf = new SparkConf().setMaster("local[2]").setAppName(_01SparkSQLOps.getClass.getSimpleName)
// 使用kryo的序列化方式
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
conf.registerKryoClasses(Array(classOf[Person]))
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val lines = sc.textFile("D:/data/spark/sql/sql-rdd-source.txt")
val personRDD:RDD[Person] = lines.map(line => {
val fields = line.split(",")
val id = fields(0).trim.toInt
val name = fields(1).trim
val age = fields(2).trim.toInt
val height = fields(3).trim.toDouble
new Person(id, name, age, height)
})
val persons: util.List[Person] = util.Arrays.asList(
new Person(1, "孙人才", 25, 179),
new Person(2, "刘银鹏", 22, 176),
new Person(3, "郭少波", 27, 178),
new Person(1, "齐彦鹏", 24, 175))
// val df:DataFrame = sqlContext.createDataFrame(persons, classOf[Person]) // 这种方式也可以
val df:DataFrame = sqlContext.createDataFrame(personRDD, classOf[Person])
df.show()
sc.stop()
}
}输出结果如下:
+---+------+---+--------+
|age|height| id| name|
+---+------+---+--------+
| 13| 175.0| 1|zhangsan|
| 14| 180.0| 2| lisi|
| 15| 175.0| 3| wangwu|
| 16| 195.0| 4| zhaoliu|
| 17| 165.0| 5| zhouqi|
| 18| 155.0| 6| weiba|
+---+------+---+--------+Java版
测试代码如下:
package cn.xpleaf.bigdata.spark.java.sql.p1;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Column;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.SQLContext;
import java.util.Arrays;
import java.util.List;
/**
* SparkRDD与DataFrame之间的转换操作
* 1.通过反射的方式,将RDD转换为DataFrame
* 2.通过动态编程的方式将RDD转换为DataFrame
* 这里演示的是第1种
*/
public class _01SparkRDD2DataFrame {
public static void main(String[] args) {
Logger.getLogger("org.apache.spark").setLevel(Level.OFF);
SparkConf conf = new SparkConf()
.setMaster("local[2]")
.setAppName(_01SparkRDD2DataFrame.class.getSimpleName())
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(new Class[]{Person.class});
JavaSparkContext jsc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(jsc);
List<Person> persons = Arrays.asList(
new Person(1, "孙人才", 25, 179),
new Person(2, "刘银鹏", 22, 176),
new Person(3, "郭少波", 27, 178),
new Person(1, "齐彦鹏", 24, 175)
);
DataFrame df = sqlContext.createDataFrame(persons, Person.class); // 构造方法有多个,使用personsRDD的方法也是可以的
// where age > 23 and height > 176
df.select(new Column("id"),
new Column("name"),
new Column("age"),
new Column("height"))
.where(new Column("age").gt(23).and(new Column("height").lt(179)))
.show();
df.registerTempTable("person");
sqlContext.sql("select * from person where age > 23 and height < 179").show();
jsc.close();
}
}输出结果如下:
+---+----+---+------+
| id|name|age|height|
+---+----+---+------+
| 3| 郭少波| 27| 178.0|
| 1| 齐彦鹏| 24| 175.0|
+---+----+---+------+
+---+------+---+----+
|age|height| id|name|
+---+------+---+----+
| 27| 178.0| 3| 郭少波|
| 24| 175.0| 1| 齐彦鹏|
+---+------+---+----+使用编程的方式将RDD转换为DataFrame
1、通过编程接口来创建DataFrame,在Spark程序运行阶段创建并保持一份最新的元数据信息,然后将此元数据信息应用到RDD上。
2、优点在于编写程序时根本就不知道元数据的定义和内容,只有在运行的时候才有元数据的数据。这种方式是在动态的时候进行动态构建元数据方式。
Scala版
测试代码如下:
package cn.xpleaf.bigdata.spark.scala.sql.p1
import cn.xpleaf.bigdata.spark.java.sql.p1.Person
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{DataTypes, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* SparkRDD与DataFrame之间的转换操作
* 1.通过反射的方式,将RDD转换为DataFrame
* 2.通过动态编程的方式将RDD转换为DataFrame
* 这里演示的是第2种
*/
object _03SparkRDD2DataFrame {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
val conf = new SparkConf().setMaster("local[2]").setAppName(_01SparkSQLOps.getClass.getSimpleName)
// 使用kryo的序列化方式
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
conf.registerKryoClasses(Array(classOf[Person]))
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
val lines = sc.textFile("D:/data/spark/sql/sql-rdd-source.txt")
val rowRDD:RDD[Row] = lines.map(line => {
val fields = line.split(",")
val id = fields(0).trim.toInt
val name = fields(1).trim
val age = fields(2).trim.toInt
val height = fields(3).trim.toDouble
Row(id, name, age, height)
})
val scheme = StructType(List(
StructField("id", DataTypes.IntegerType, false),
StructField("name", DataTypes.StringType, false),
StructField("age", DataTypes.IntegerType, false),
StructField("height", DataTypes.DoubleType, false)
))
val df = sqlContext.createDataFrame(rowRDD, scheme)
df.registerTempTable("person")
sqlContext.sql("select max(age) as max_age, min(age) as min_age from person").show()
sc.stop()
}
}输出结果如下:
+-------+-------+
|max_age|min_age|
+-------+-------+
| 18| 13|
+-------+-------+Java版
测试代码如下:
package cn.xpleaf.bigdata.spark.java.sql.p1;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.*;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.Metadata;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.util.Arrays;
import java.util.List;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class _02SparkRDD2DataFrame {
public static void main(String[] args) {
Logger.getLogger("org.apache.spark").setLevel(Level.OFF);
SparkConf conf = new SparkConf()
.setMaster("local[2]")
.setAppName(_02SparkRDD2DataFrame.class.getSimpleName())
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(new Class[]{Person.class});
JavaSparkContext jsc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(jsc);
List<Person> persons = Arrays.asList(
new Person(1, "孙人才", 25, 179),
new Person(2, "刘银鹏", 22, 176),
new Person(3, "郭少波", 27, 178),
new Person(1, "齐彦鹏", 24, 175)
);
Stream<Row> rowStream = persons.stream().map(new Function<Person, Row>() {
@Override
public Row apply(Person person) {
return RowFactory.create(person.getId(), person.getName(), person.getAge(), person.getHeight());
}
});
List<Row> rows = rowStream.collect(Collectors.toList());
StructType schema = new StructType(new StructField[]{
new StructField("id", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("name", DataTypes.StringType, false, Metadata.empty()),
new StructField("age", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("height", DataTypes.DoubleType, false, Metadata.empty())
});
DataFrame df = sqlContext.createDataFrame(rows, schema);
df.registerTempTable("person");
sqlContext.sql("select * from person where age > 23 and height < 179").show();
jsc.close();
}
}输出结果如下:
+---+----+---+------+
| id|name|age|height|
+---+----+---+------+
| 3| 郭少波| 27| 178.0|
| 1| 齐彦鹏| 24| 175.0|
+---+----+---+------+缓存表(列式存储)案例与解析
缓存和列式存储
Spark SQL 可以将数据缓存到内存中,我们可以见到的通过调用cache table tableName即可将一张表缓存到内存中,来极大的提高查询效率。
sqlContext.cacheTable(tableName)这就涉及到内存中的数据的存储形式,我们知道基于关系型的数据可以存储为基于行存储结构或者基于列存储结构,或者基于行和列的混合存储,即Row Based Storage、Column Based Storage、 PAX Storage。
Spark SQL 的内存数据是如何组织的?
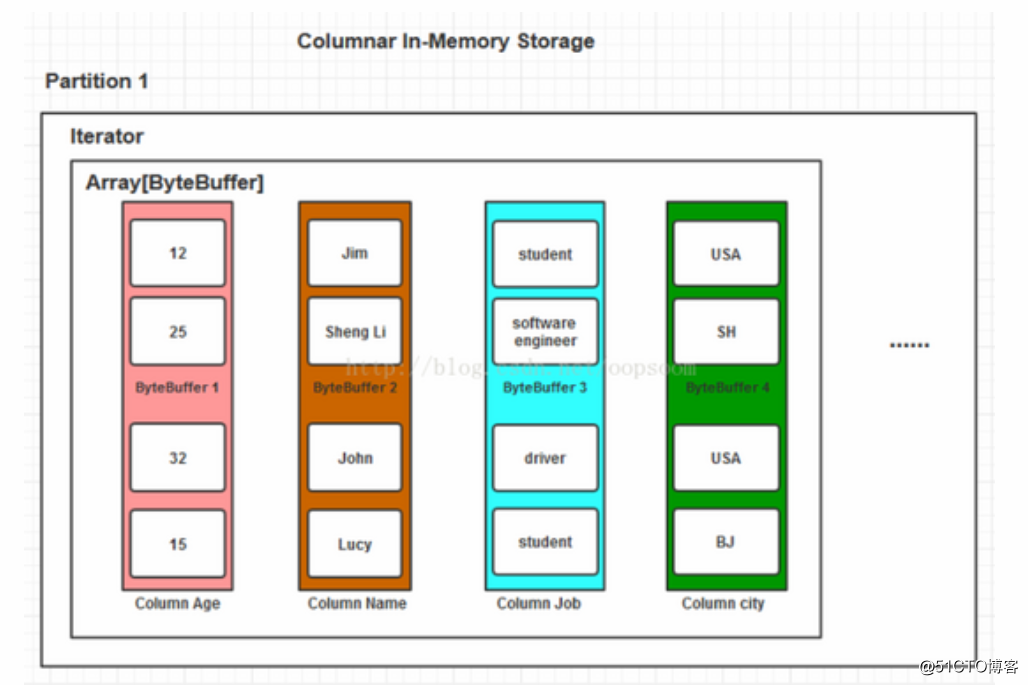
Spark SQL 将数据加载到内存是以列的存储结构。称为In-Memory Columnar Storage。
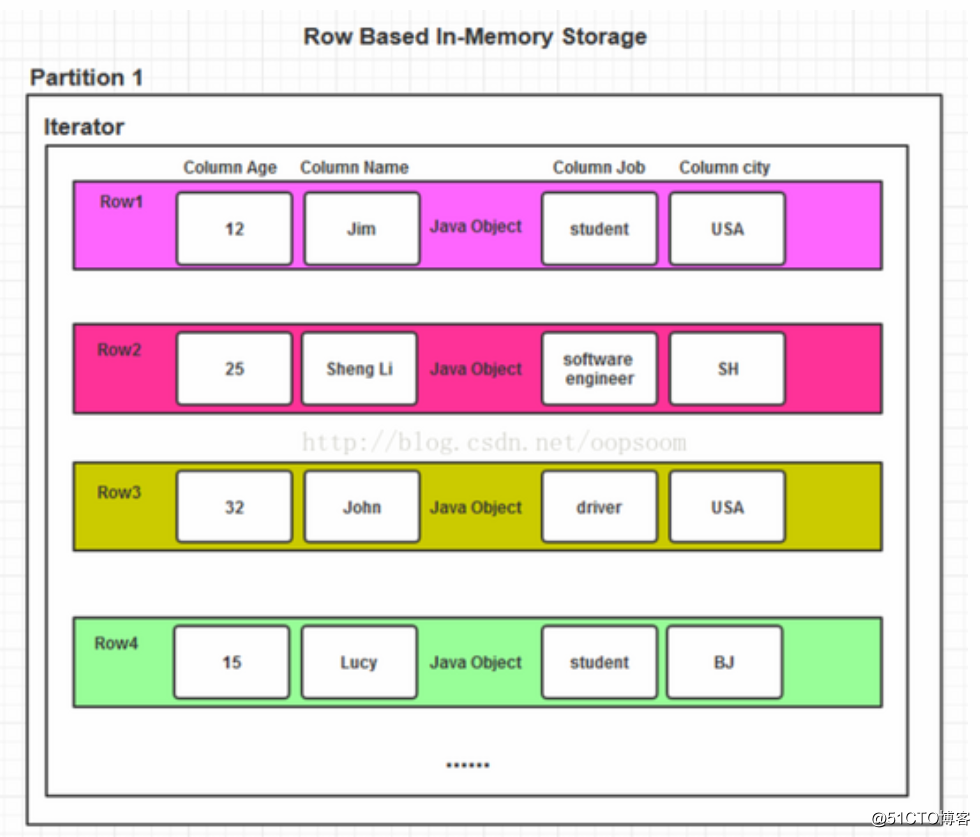
若直接存储Java Object 会产生很大的内存开销,并且这样是基于Row的存储结构。查询某些列速度略慢,虽然数据以及载入内存,查询效率还是低于面向列的存储结构。
基于Row的Java Object存储
内存开销大,且容易FULL GC,按列查询比较慢。
基于Column的ByteBuffer存储(Spark SQL)
内存开销小,按列查询速度较快。
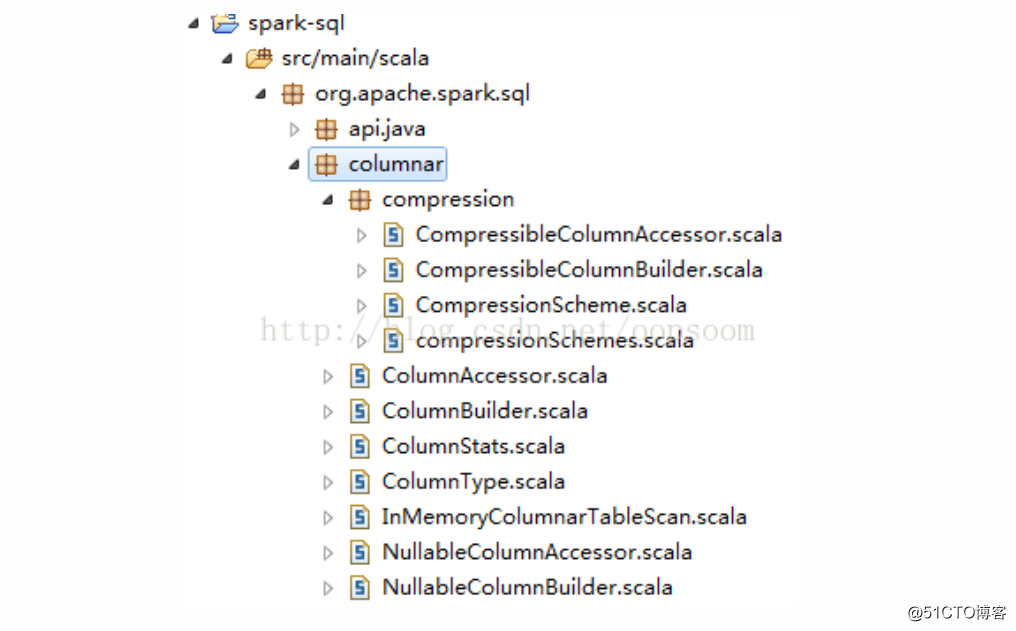
In-Memory Columnar Storage代码分布
Spark SQL的In-Memory Columnar Storage是位于spark列下面org.apache.spark.sql.columnar包内:
核心的类有 ColumnBuilder, InMemoryColumnarTableScan, ColumnAccessor, ColumnType.
如果列有压缩的情况:compression包下面有具体的build列和access列的类。
性能调优
对于某些工作负载,可以在通过在内存中缓存数据或者打开一些实验选项来提高性能。
在内存中缓存数据
Spark SQL可以通过调用sqlContext.cacheTable("tableName")方法来缓存使用柱状格式的表。然后,Spark将会仅仅浏览需要的列并且自动地压缩数据以减少内存的使用以及垃圾回收的 压力。你可以通过调用sqlContext.uncacheTable("tableName")方法在内存中删除表。
注意,如果你调用schemaRDD.cache()而不是sqlContext.cacheTable(...),表将不会用柱状格式来缓存。在这种情况下,sqlContext.cacheTable(...)是强烈推荐的用法。
可以在SQLContext上使用setConf方法或者在用SQL时运行SET key=value命令来配置内存缓存。

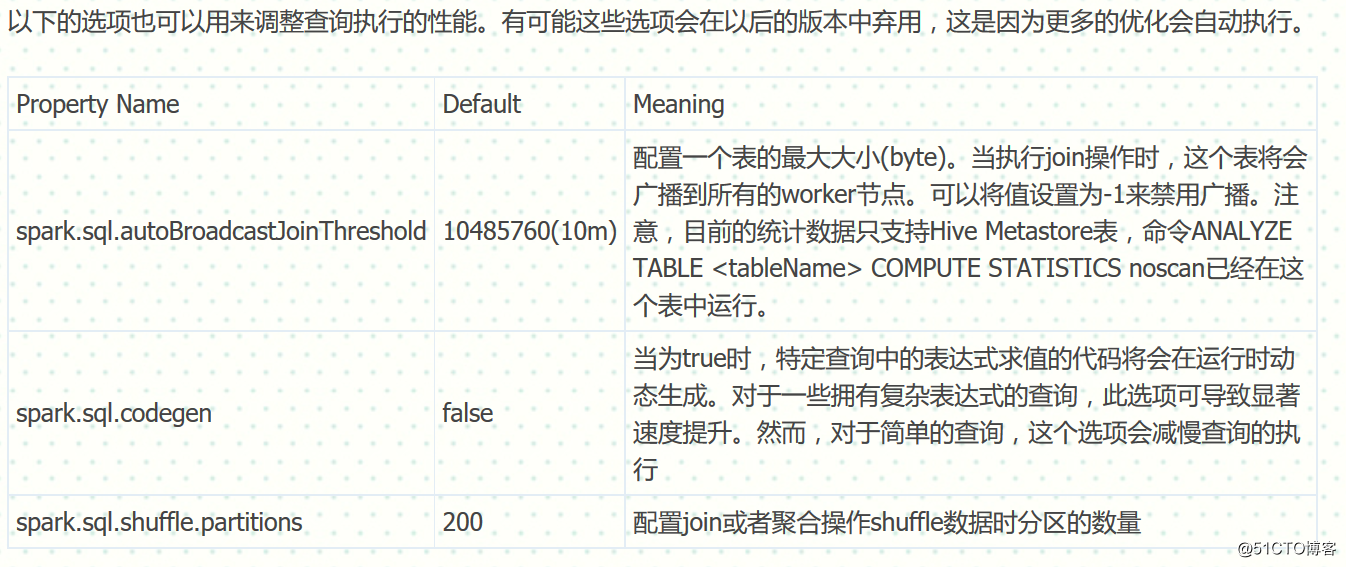
DataFrame常用API
1、collect 和 collectAsList 将df中的数据转化成Array和List
2、count 统计df中的总记录数
3、first 获取df中的第一条记录,数据类型为Row
4、head 获取df的前几条记录
5、show
6、take 获取df中的前几条记录
7、cache 对df进行缓存
8、columns 显示所有的列的schema列名,类型为Array[String]
9、dtypes 显示所有的列的schema信息,类型为Array[(String, String)]
10、explain 显示当前df的执行计划
11、isLocal 当前spark sql的执行是否为本地,true为真,false为非本地
12、printSchema
13、registerTempTable
14、schema
15、toDF :备注:toDF带有参数时,参数个数必须和调用这DataFrame的列个数据是一样的
类似于sql中的:toDF:insert into t select * from t1;
16、intersect:返回两个DataFrame相同的Rows
原文链接:http://blog.51cto.com/xpleaf/2114298
