
Web自动化002-Web自动化元素定位及浏览器的相关操作
Web自动化002-Web自动化元素定位及浏览器的相关操作
Web自动化元素定位及浏览器相关的操作
标签=元素
1.元素定位
- 首先需要选择要被定位的元素(锁定被操作的元素)
- 然后才能对元素进行具体操作(具体的操作方法)
selenium第三方库中提供了两类定位的方法
- find_element----->返回一个元素,如果没有该元素,就会报错
- find_elements----->返回多个元素(整个返回值是一个列表,列表中可能有多个元素)如果没有找到元素,那么就会返回一个空列表。 这个不会报找不到元素的错误{如 not such element.....}
- 比如做自动化的时候,某个表单的很多按钮、页面的是数据或者控件(页面元素)定位是一组元素,我们可以通过这个方法获取一个列表,通过列表的索引,去找到对应的元素,进而对元素进行操作。
- selenium4.0以后把常规的方法封装成只有这两个方法
- 相当于把常规的8种元素定位方法,封装到内部函数
- 源码解析:
def find_element(self, by=By.ID, value: Optional[str] = None) -> WebElement:
"""Find an element given a By strategy and locator.
:Usage:
::
element = driver.find_element(By.ID, 'foo')
:rtype: WebElement
"""
if isinstance(by, RelativeBy):
elements = self.find_elements(by=by, value=value)
if not elements:
raise NoSuchElementException(f"Cannot locate relative element with: {by.root}")
return elements[0]
if by == By.ID:
by = By.CSS_SELECTOR
value = f'[id="{value}"]'
elif by == By.CLASS_NAME:
by = By.CSS_SELECTOR
value = f".{value}"
elif by == By.NAME:
by = By.CSS_SELECTOR
value = f'[name="{value}"]'
return self.execute(Command.FIND_ELEMENT, {"using": by, "value": value})["value"]
这是一个在Selenium WebDriver中的方法`find_element`的源代码实现。
它用于根据给定的定位策略(By strategy)和定位器(locator)查找一个元素。
此方法的用法如下所示:
```python
element = driver.find_element(By.ID, 'foo')
```
函数的返回类型为`WebElement`,表示找到的元素对象。
函数的实现逻辑如下:
1. 如果定位策略是`RelativeBy`的实例,将调用`find_elements`方法来查找元素,
并返回列表中的第一个元素。如果没有找到元素,则抛出`NoSuchElementException`异常,<br>
异常消息中会包含无法找到的相对元素的信息。
2. 如果定位策略是`By.ID`,将将定位策略修改为`By.CSS_SELECTOR`,并将值修改为一个CSS选择器,选择器的规则是`[id="{value}"]`,即根据`id`属性的值来选择元素。
3. 如果定位策略是`By.CLASS_NAME`,同样将定位策略修改为`By.CSS_SELECTOR`,并将值修改为一个CSS选择器,选择器的规则是`. {value}`,即根据`class`属性的值来选择元素。
4. 如果定位策略是`By.NAME`,同样将定位策略修改为`By.CSS_SELECTOR`,并将值修改为一个CSS选择器,选择器的规则是`[name="{value}"]`,即根据`name`属性的值来选择元素。
5. 最后,调用`execute`方法,执行找到元素的命令,命令参数中使用修改后的定位策略和值,将返回的结果中的`value`字段作为结果返回。
很久没看selenium,发现最新的源码有更新,我在此处进行补充解析:

def find_element(self, by=By.ID, value: Optional[str] = None) -> WebElement:
"""Find an element given a By strategy and locator.
:Usage:
::
element = driver.find_element(By.ID, 'foo')
:rtype: WebElement
"""
by, value = self.locator_converter.convert(by, value)
if isinstance(by, RelativeBy):
elements = self.find_elements(by=by, value=value)
if not elements:
raise NoSuchElementException(f"Cannot locate relative element with: {by.root}")
return elements[0]
return self.execute(Command.FIND_ELEMENT, {"using": by, "value": value})["value"]
- 需要导入模块---from selenium.webdriver.common.by import By
- 导入By类,在find_element/elements中传入元素定位的方法和元素定位选择器
- 4.0版本以后的版本,需要导入此库,完成元素的定位
- By类的类属性
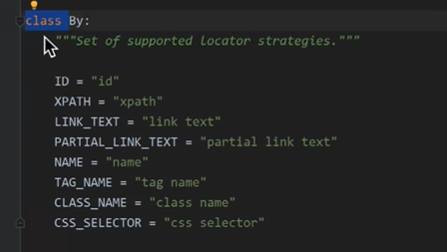
selenium中提供了8种不同类型的元素定位方式(主流方法)
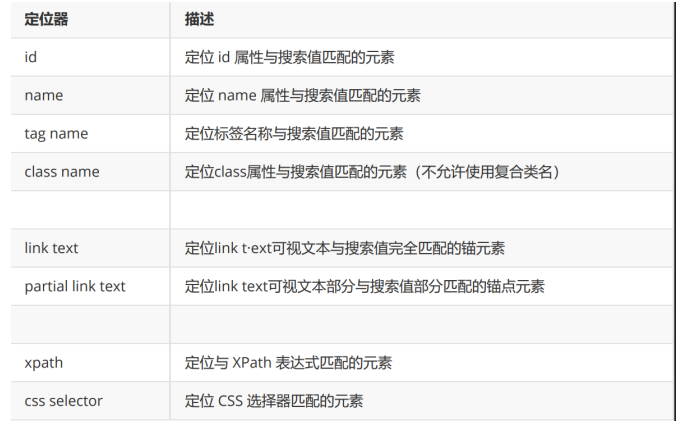
Selenium元素定位方式主要有以下几种:
- ID定位:通过元素的ID属性值来定位元素,使用方法是driver.find_element_by_id("id值")。
- Name定位:通过元素的name属性值来定位元素,使用方法是driver.find_element_by_name("name值")。
- Class Name定位:通过元素的class属性值来定位元素,使用方法是driver.find_element_by_class_name("class值")。
- Tag Name定位:通过元素的标签名来定位元素,使用方法是driver.find_element_by_tag_name("标签名")。
- Link Text定位:通过链接文本来定位链接元素,使用方法是driver.find_element_by_link_text("链接文本")。精准文本匹配的方法
- Partial Link Text定位:通过链接文本的一部分来定位链接元素,使用方法是driver.find_element_by_partial_link_text("链接文本的一部分")。模糊文本匹配的方式
- XPath定位:通过元素的XPath路径来定位元素,使用方法是driver.find_element_by_xpath("XPath路径")。
- CSS Selector定位:通过元素的CSS选择器来定位元素,使用方法是driver.find_element_by_css_selector("CSS选择器")。
注意上述的方法最终只有两种find_element/elements
下面给出一个页面html的元素示例:
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
其中:
id=kw
classname=s_ipt
name=wd
其中link_text partial_link_text针对的都是a标签 ,专门要来定位a标签
- 前者是精准匹配、全部匹配文本定位 后者为部分匹配 模糊文本匹配
Tag name 一般不去使用,因为一个页面相同元素-标签的名字特别多
定位元素的原则:只要能够定位成功,不管哪种方式都可以
import time
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.maximize_window()
time.sleep(2)
# <input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
# 通过元素的id属性定位
# driver.find_element(By.ID, 'kw').send_keys("刘亦菲")
# 通过元素的name属性定位
driver.find_element(By.NAME, 'wd').send_keys("李一桐")
# 通过元素的class_name属性定位
driver.find_element(By.CLASS_NAME, 's_ipt').send_keys("刘诗诗")
send_keys()方法可以进行内容的输入
click()方法用来完成点击操作
# # driver.find_element(By.LINK_TEXT, '网盘').click()
# # driver.find_element(By.PARTIAL_LINK_TEXT, '盘').click()
LINK_TEXT:精准匹配定位元素
PARTIAL_LINK_TEXT:模糊匹配定位元素
页面中可以打开开发者工具,然后点击console控制台可以在里面写JavaScript脚本以及核心的元素定位及操作都能完成:
xpath支持相对路径定位和绝对路径定位
XPath是一种在XML文档中定位元素的语言,也可以用于HTML文档中。在Selenium中,我们可以使用XPath来定位元素。XPath有两种类型:绝对路径和相对路径。
绝对路径是从根节点开始的完整路径,可以通过浏览器的开发者工具来获取,但是由于页面结构可能会改变,因此绝对路径并不是一种稳定的定位方式。
相对路径是相对于当前元素的路径,相对路径更灵活,也更易于维护。以下是一些常用的XPath定位方式:
- 通过元素标签名定位元素://标签名,例如//input。
- 通过元素属性定位元素://*[@属性名="属性值"],例如//*[@id="username"]。
- 通过元素属性模糊匹配定位元素://*[contains(@属性名,"属性值的一部分")],例如//*[contains(@class,"button")]。
- 通过元素文本内容定位元素://*[text()="文本内容"],例如//*[text()="登录"]。
- 通过元素文本内容模糊匹配定位元素://*[contains(text(),"文本内容的一部分")],例如//*[contains(text(),"登录")]。
- 通过元素的父节点、兄弟节点等关系定位元素:例如//div[@class="form"]/input[1],表示找到class属性为form的div元素下的第一个input元素。
ps:因为前端页面可能看起来没改动,但是元素的路径和标签可能进行修改,特别是class值以及元素的上下层级关系,标签名称、顺序之类,所以使用绝对路径、相对路径的定位元素做自动化测试时,容易会出现元素变更,我们可以从代码中报错 no such element
注意,XPath中的单引号和双引号不能混用,如果属性值中含有引号,可以使用双引号包裹属性值,例如//*[@title="It's a title"]。
使用xpath进行定位的时候因为xpath值是字符串(双引号),所以实际的定位元素值内部使用单引号
手写xpath函数:$x("具体的xpath值")
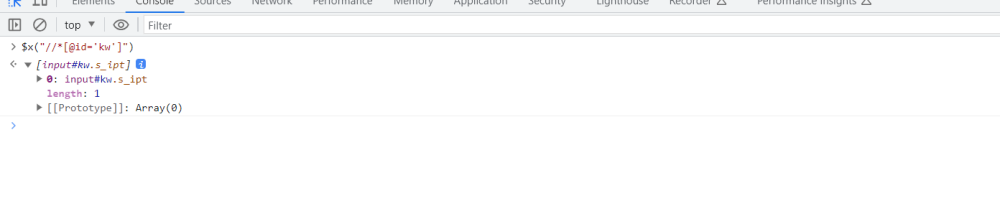
如果能够定位到页面中会显示而且可以选中并且操作该元素
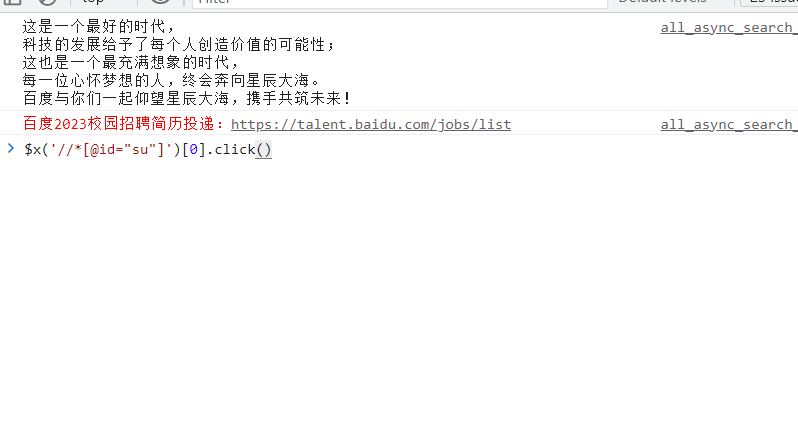
css选择器的定位方式: 其中id用#表示 class用.表示
css选择的属性: id:#id
name:[name=wd]
class(类选择器):.s_ipt
CSS元素定位是Selenium中常用的一种元素定位方式,它可以通过CSS选择器来定位页面上的元素。使用CSS元素定位需要了解一些CSS选择器的基本语法和规则。
下面是一些常见的CSS选择器:
- 标签选择器:使用标签名作为选择器,例如 `div`、`p`、`a` 等。
- 类选择器:使用类名作为选择器,以点号开头,例如 `.classname`。
- ID 选择器:使用 ID 值作为选择器,以#号开头,例如 `#idname`。
- 属性选择器:根据元素属性值来进行匹配,例如 `[attribute=value]`。
总结: 不管使用哪一种定位元素的方式,原则上是能够定位到该元素就直接使用,比较常用的定位方式:
xpath和css
从操作元素的角度来讲并没有任何差异
css定位方法执行的时候比较高效,对于前端开发人员会比较友好
xpath定位方法是通过底层JavaScript脚本执行的,支持更多的逻辑处理,完成复杂的元素项,对于测试人员非常的友好
示例代码
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.maximize_window()
time.sleep(2)
# <input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
# driver.find_element(By.ID, 'kw').send_keys("刘亦菲")
# driver.find_element(By.NAME, 'wd').send_keys("李一桐")
# driver.find_element(By.CLASS_NAME, 's_ipt').send_keys("刘诗诗")
# driver.find_element(By.LINK_TEXT, '网盘').click()
# driver.find_element(By.PARTIAL_LINK_TEXT, '盘').click()
# driver.find_element(By.XPATH, '//*[@id="kw"]').send_keys("郑爽")
# driver.find_element(By.XPATH, '/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input').send_keys('张馨予')
driver.find_element(By.CSS_SELECTOR, '#kw').send_keys('杨幂')
driver.find_element(By.CSS_SELECTOR, '.s_ipt').send_keys('赵丽颖')
driver.find_element(By.CSS_SELECTOR, '[name=wd]').send_keys('袁冰妍')
time.sleep(5)
driver.quit()
定位元素不到的报错信息:

2.元素的具体操作
元素交互方法:
输入内容:send_keys()
点击(鼠标的左击):click() 此处可以用来完成点击操作
清除文本:clear() {注意做自动化测试,对于输入框的输入,如果输入框中已有默认的数值,需要先调用clear()方法执行清除操作,再调用send_keys方法完成输入的操作}
ele1 = driver.find_element(By.ID, 'kw')
ele1.send_keys("范冰冰")
time.sleep(2)
ele1.clear()
元素的属性获取
- 获取元素的大小:size
- 获取元素的文本信息:text
- 获取元素的属性:get_attribute()
- 判断元素是否可见:is_display()
- 判断元素是否可用:is_enable()
注意上面的方法 大部分用于自动化测试的断言,比如判断文本信息的准确性,比如判断勾选了某个按钮后,页面的class/type属性是否有变化:如 checked,判断按钮被禁用,按钮是否置灰,此时元素是否可见可使用等情况
# 示例代码:
ele = driver.find_element(By.ID, 'su')
#获取元素的大小:size
print(ele.size)
#获取元素的文本信息 text
print(ele.text)
#获取元素的属性 比如获取元素的type属性
print(ele.get_attribute("type"))
#判断元素是否可见
print(ele.is_displayed())
#如果元素可见 返回的结果为True 否则返回的结果为Flase
# 判断元素是否可用 如果可用 返回的结果为True 否则返回的结果为Flase
print(ele.is_enabled())
3 .浏览器的基本操作
浏览器常见的操作:
- 浏览器的最大化
- 设置浏览器的宽高
- 设置浏览器的位置
- 刷新 前进 后退
- 关闭当前窗口页面 关闭整个浏览器
- 浏览器标题、URL
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_driver = webdriver.Chrome()
chrome_driver.get('https://www.baidu.com/')
chrome_driver.implicitly_wait(10)
chrome_driver.maximize_window()
chrome_driver.set_window_size(200,600)
time.sleep(3)
chrome_driver.set_window_position(100,100)
time.sleep(3)
chrome_driver.maximize_window()
# 示例代码:
driver.find_element(By.ID, 'kw').send_keys('司空千落')
driver.find_element(By.ID, 'su').click()
#获取浏览器的标题
print(driver.title)
#获取浏览器的url地址(当前的地址)
print(driver.current_url)
time.sleep(5)
#刷新页面
driver.refresh()
sleep(2)
#页面回退
driver.back()
sleep(2)
#页面前进
driver.forward()
sleep(2)
#关闭当前页面窗口
driver.close()
sleep(2)
#退出浏览器 或者是叫做关闭浏览器驱动对象
driver.quit()
4.等待
为什么要等待?等什么?
等元素
因为在web页面中看到的元素,不一定全部写在html页面中,有可能是通过JavaScript脚本进行操作产生出来的,
而 JavaScript产生的元素时,很有可能需要先获取到数据,处理之后才会显示出现,所以不一定页面打开,所有的页面元素都会加载出来,如果需要被定位的元素,没有被加载出来那么程序会报错。
等待的三种方式
- 强制等待
- 直接使用python的模块time的sleep方法
- time.sleep() 括号里面的参数为强制等待的时间
- 显式等待
- 每隔一段时间不断地尝试查找定位该元素
- 如果定位到了该元素那么就返回该元素值
- 如果在规定的时间里面,没有找到,那么程序会报错(TimeoutException)
- 注意:此方法的使用比较复杂,需要会对此方法进行重写优化
- 使用时,需要提前导出相关的包:
- # 导入显示等待的类
■ from selenium.webdriver.support.wait import WebDriverWait
■ from selenium.webdriver.support import expected_conditions as EC
- 重写显示等待定位元素方法
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def wait_for_element(driver, locator, timeout=10):
try:
element = WebDriverWait(driver, timeout).until(
EC.presence_of_element_located(locator)
)
return element
except TimeoutException:
print("等待超时,未找到元素: {}".format(locator))
return None
# 使用示例
driver = webdriver.Chrome()
driver.get("https://www.example.com")
element_locator = (By.ID, "my_element_id")
element = wait_for_element(driver, element_locator)
if element:
# 执行后续操作
element.click()
使用前提,需要导包
#导入显示等待的类
from selenium.webdriver.support.wait import WebDriverWait
# 导入 Selenium 的 expected_conditions 模块,并将其重命名为 EC
from selenium.webdriver.support import expected_conditions as EC
'''
expected_conditions 模块定义了等待条件,即在使用显示等待时所需的条件。
expected_conditions 模块提供了一系列的预定义条件,例如:
presence_of_element_located(locator): 判断元素是否存在
visibility_of_element_located(locator): 判断元素是否可见
element_to_be_clickable(locator): 判断元素是否可点击
text_to_be_present_in_element(locator, text_): 判断元素中的文本是否
包含指定的文本
这些条件可以与 WebDriverWait 对象一起使用,
以在等待指定条件成立后继续进行测试操作。
例如,EC.presence_of_element_located(locator) 条件
可以与 WebDriverWait 一起使用,
使脚本等待直到指定的元素出现在页面上才继续执行后续操作。
'''
示例代码:
import time
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.maximize_window()
time.sleep(2)
driver.find_element(By.XPATH, '//*[@id="kw"]').send_keys("美女")
driver.find_element(By.XPATH, '//*[@id="su"]').click()
el1 = WebDriverWait(driver, 3).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="1"]/div/h3/a'))
)
print(el1)
- 隐式等待
- 元素会在第一次定位不到的时候才进行触发等待的时间,启动隐式等待
- 有效时间,如果元素加载完毕并且定位到该元素,就继续执行操作
- 如果没有在有效时间定位到该元素就是出现定位不到元素的异常(NoSuchElementException)
代码示例:
import time
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
driver.maximize_window()
time.sleep(2)
driver.find_element(By.XPATH, '//*[@id="kw"]').send_keys("美女")
driver.find_element(By.XPATH, '//*[@id="su"]').click()
# el1 = WebDriverWait(driver, 3).until(
# EC.presence_of_element_located((By.XPATH, '//*[@id="1"]/div/h3/a'))
# )
# print(el1)
# el1.click()
driver.implicitly_wait(20)
driver.find_element(By.XPATH, '//*[@id="1"]/div/h3/a').click()
扩展:
1.为什么在web自动化测试过程中需要等待?
在进行web自动化测试时,等待是非常重要的步骤。
这是因为web应用程序的加载和响应时间是不确定的,
可能会受到网络延迟、服务器响应速度、页面元素加载时间等因素的影响。
如果没有适当的等待机制,测试脚本可能会在元素加载完成之前执行操作,
从而导致测试失败或产生不准确的结果。
下面介绍三种常见的等待方式以及它们之间的区别和使用场景:
1. 隐式等待(Implicit Wait):
- 设置一个全局等待时间,对整个测试过程中的每个元素查找或操作都会生效。
- 当使用此等待方式时,如果元素立即被找到,则操作会立即继续执行;
- 如果元素没有立即找到,则会等待指定的时间再继续执行。
- 使用场景:适用于整个测试过程中大部分元素查找时间相对稳定的情况。
2. 显式等待(Explicit Wait):
- 设置等待时间和条件,只对指定的某个元素或某个条件满足时生效。
- 在等待时间内,会定期检查条件是否满足,如果满足,则立即继续执行下一步操作;如果超过等待时间仍未满足条件,则会抛出超时异常。
- 使用场景:适用于需要等待特定条件出现或消失的情况,
- 例如元素可见、元素存在、元素可点击等。
3. 强制等待(Thread.sleep):
- 暂停测试脚本的执行固定时间。
- 不会进行条件判断,无论元素是否加载完成,都会等待指定的时间再继续执行。
- 使用场景:适用于简单的等待,例如页面跳转或刷新后的等待。
区别:
- 隐式等待是全局设置,应用于整个测试过程,
- 而显式等待和强制等待是针对特定的操作或条件。
- 隐式等待是等待元素的存在,而显式等待是等待条件的出现或消失。
- 隐式等待和显式等待都会根据设定的等待时间进行条件判断,
- 但显式等待可以自定义条件。
总结:
- 如果网页的加载时间比较稳定,且需要等待的元素比较相似,可以使用隐式等待。
- 如果需要等待特定条件的出现或消失,可以使用显式等待。
- 强制等待适用于简单的等待,但并不推荐在实际的自动化测试中频繁使用,
- 因为它会浪费执行时间,而且无法自动适应页面加载速度的变化。

