selenium中处理验证码问题1-获取验证码图片
selenium中处理验证码问题:
- 验证码:
- 基本作用:可以实现当前访问页面的数据安全性、还可以减少用户的并发数;实现大流量的分流
- 类型:1.纯数字、纯字母 2.汉字组合 3.数学运算题 4.滑动 5.图片(选不同的、选相同、选给出已知性、成语顺序,汉字顺序......) 6.短信 7.语音 8.邮箱
- 验证码的实现:
- 在开发验证码时,必然会有对应的验证码资源库;(通常情况下会有两种:本地资源库、网络资源库)
- 本地资源:开发会设定相关的验证码的资源信息;通常定义在某种容器类型中;[0,1,2,3,4,5,6,7,8,9,A,......“男”,“女”,“天”,“地”.......]
- 网络资源:相关的数据全部都是调用第三方接口或者在网络上进行爬取相关数据;
- 解决验证码:
- 1.让开发人员将验证码直接屏蔽操作
- 2.让开发人员提供一个万能验证码
- 3. 如果是本地资源库图片的形式的话,则可以将服务器存储资源文件夹中所有图片全部删除只留一张
- 4.打码平台完成
![]()
- 5.使用机器语言学习验证码(比如:光学字符扫描模块(部分))-------需要大量的精力人力物力大量的时间,非一朝一夕可以学会。
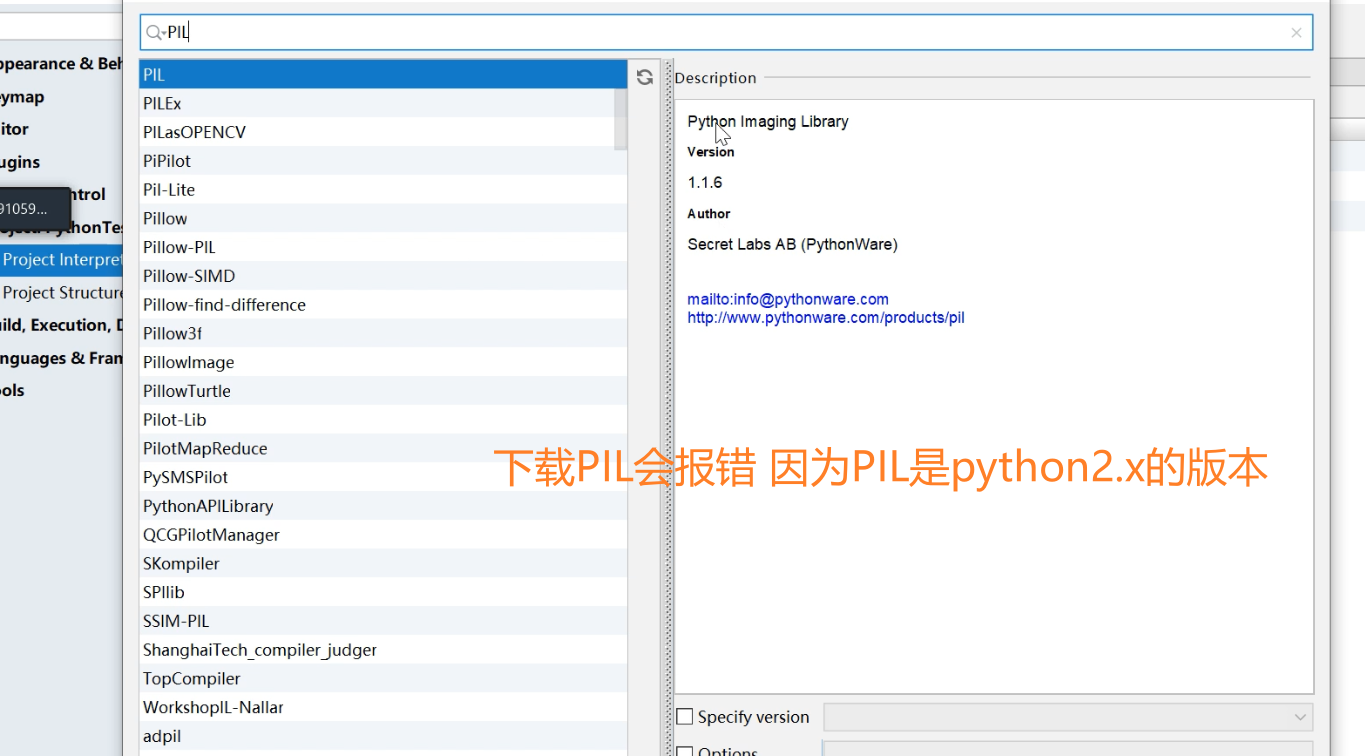
- 通过代码获取验证码:使用第三方扩展模块:PIL(图像处理模块:Python Imaging library python的图像处理库)模块;因为PIL是属于python2.x版本所使用的;在python3.x版本中现如今主要使用的模块是Pillow、Pillow-PIL等
- 注意:如何需要进行页面截图,并且是截取页面中的某一个部分图片的话,则一定要注意当前计算机的布局填充率(影响截图的范围位置)
- :
![]()
- 网址:https://python-pillow.org/
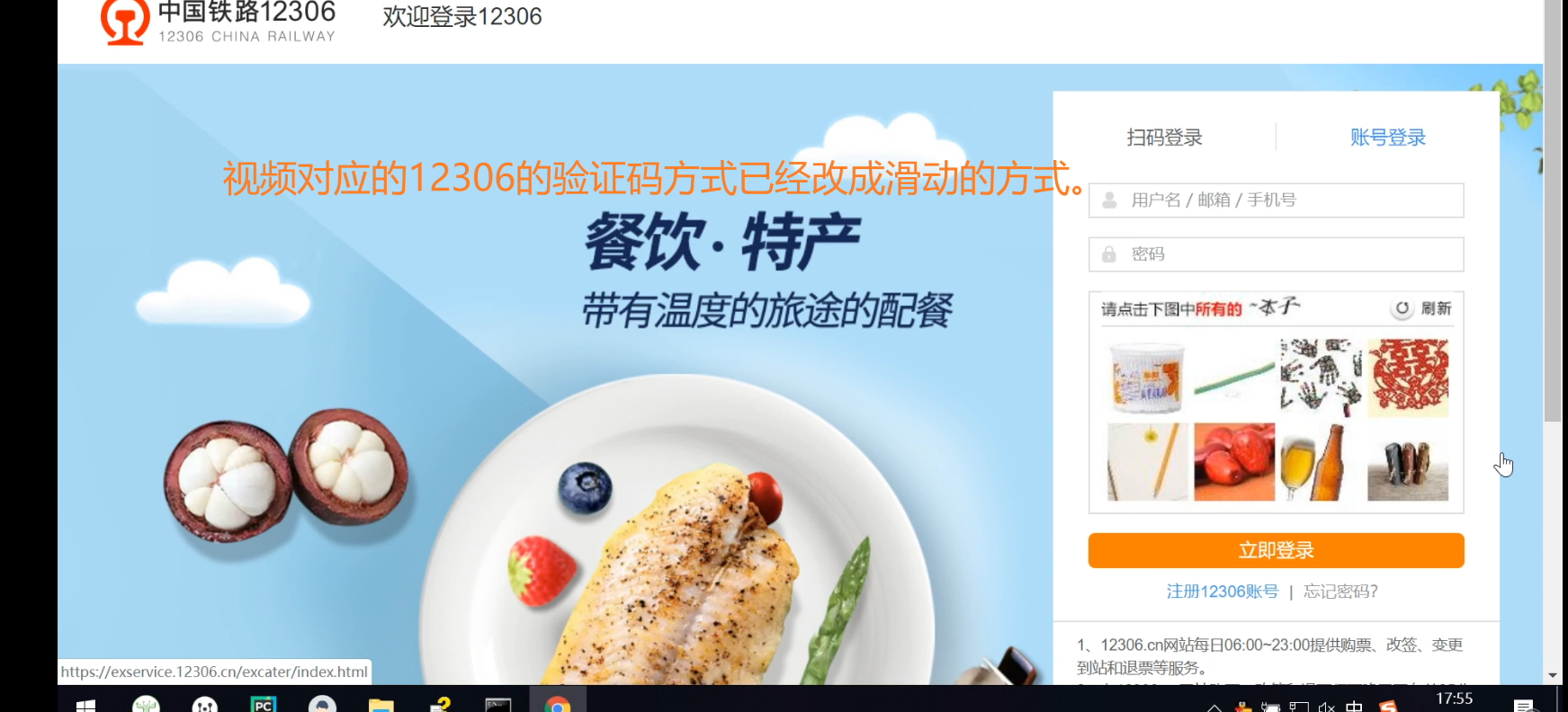
因为对应案例的12306这种验证码的方式取消了,下面的代码展示只能参考思想,代码不能直接使用,记住验证码的获取过程(整个页面到只获取验证码图片的过程)
获取验证码的图片验证:windows的页面填充布局会影响截取的效果
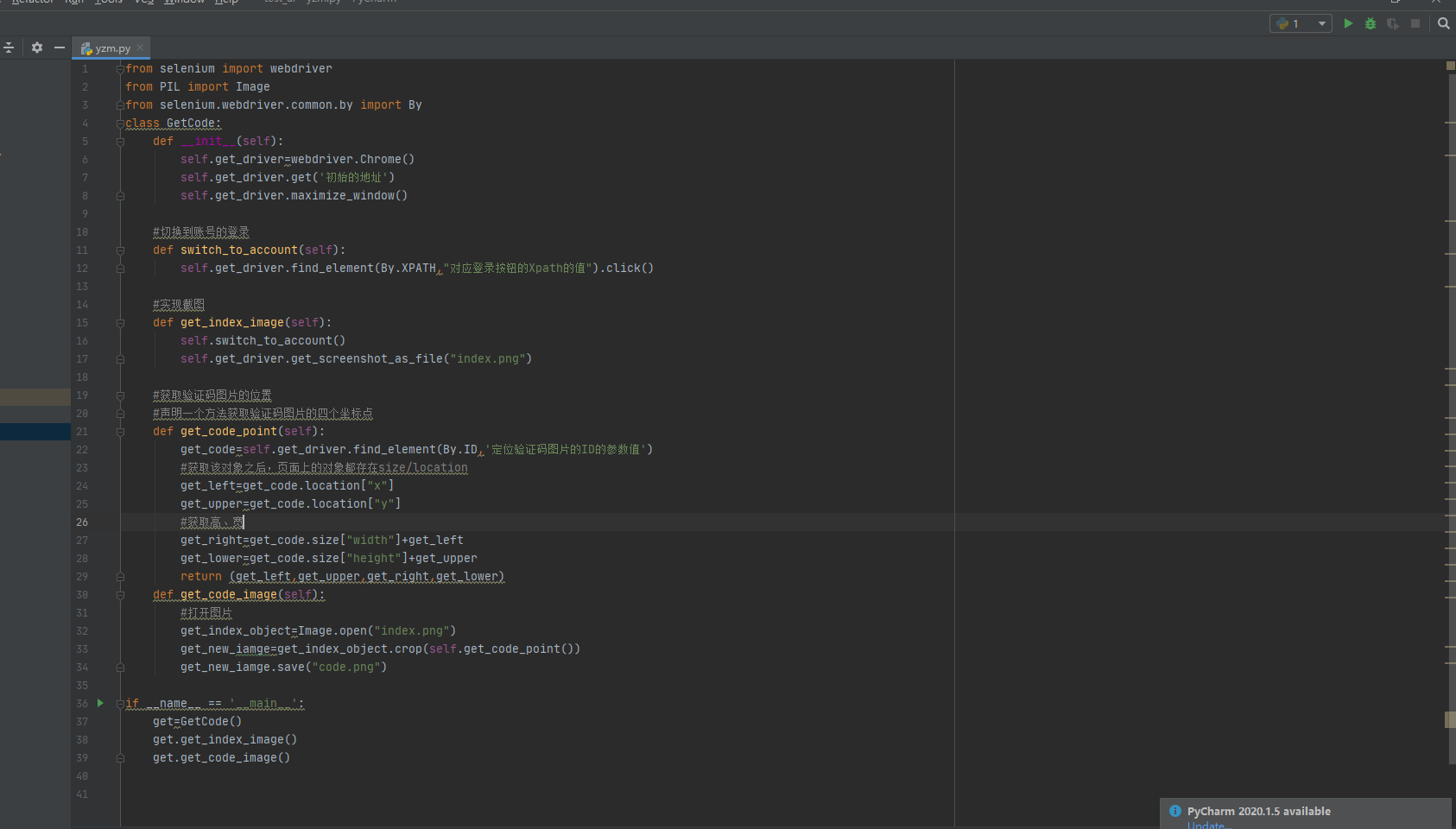
demo:不要无脑复制代码 要了解为什么这样子
from selenium import webdriver
from PIL import Image
from selenium.webdriver.common.by import By
class GetCode:
def __init__(self):
self.get_driver=webdriver.Chrome()
self.get_driver.get('初始的地址')
self.get_driver.maximize_window()
#切换到账号的登录
def switch_to_account(self):
self.get_driver.find_element(By.XPATH,"对应登录按钮的Xpath的值").click()
#实现截图
def get_index_image(self):
self.switch_to_account()
self.get_driver.get_screenshot_as_file("index.png")
#获取验证码图片的位置
#声明一个方法获取验证码图片的四个坐标点
def get_code_point(self):
get_code=self.get_driver.find_element(By.ID,'定位验证码图片的ID的参数值')
#获取该对象之后,页面上的对象都存在size/location
get_left=get_code.location["x"]
get_upper=get_code.location["y"]
#获取高、宽
get_right=get_code.size["width"]+get_left
get_lower=get_code.size["height"]+get_upper
return (get_left,get_upper,get_right,get_lower)
def get_code_image(self):
#打开图片
get_index_object=Image.open("index.png")
get_new_iamge=get_index_object.crop(self.get_code_point())
get_new_iamge.save("code.png")
if __name__ == '__main__':
get=GetCode()
get.get_index_image()
get.get_code_image()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号