
liunx问题
附带要求:
1、了解并配置服务器的最大文件操作数
Linux服务器 设置最大打开文件数永久
vim /etc/security/limits.conf
* soft nofile 65535
* hard nofile 65535
注意“”是要加到文件里面的。这两句话的含义是soft(应用软件)级别限制的最大可打开文件数的限制,hard表示操作系统级别限制的最大可打开文件数的限制,“”表示所有用户都生效。保存这个文件(只有root用户能够有权限)。
执行命令后,配置马上生效。您可以用ulimit -a 查看目前会话中的所有核心配置
ulimit 是一个计算机命令,用于shell启动进程所占用的资源,可用于修改系统资源限制
命令常用参数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
-H 设置硬资源限制.-S 设置软资源限制.-a 显示当前所有的资源限制.-c size:设置core文件的最大值.单位:blocks-d size:设置数据段的最大值.单位:kbytes-f size:设置创建文件的最大值.单位:blocks-l size:设置在内存中锁定进程的最大值.单位:kbytes-m size:设置可以使用的常驻内存的最大值.单位:kbytes-n size:设置内核可以同时打开的文件描述符的最大值.单位:n-p size:设置管道缓冲区的最大值.单位:kbytes-s size:设置堆栈的最大值.单位:kbytes-t size:设置CPU使用时间的最大上限.单位:seconds-v size:设置虚拟内存的最大值.单位:kbytes-u <程序数目> 用户最多可开启的程序数目 |
2、安装tengine并配置负载和后端节点检查,但是要求了解nginx与tengine基本区别
nginx和tengine的区别是:
1、tengine是在nginx上面开发的,包含了nginx的性能。
2、tengine更适合大访问量网站的需求,相比nginx更加的稳定,性能更加的强劲。
据网络测试:
Tengine相比Nginx默认配置,提升200%的处理能力。
Tengine相比Nginx优化配置,提升60%的处理能力。
vim nginx.conf
server {
location /status {
check_status;
#访问日志 结束
access_log off;
#允许一些。ip。地址
allow SOME.IP.ADDRESS
#禁止所有
#全部拒绝
#拒绝所有
deny all;
}
}
在upstream配置如下
check interval=3000 rise=2 fall=5 timeout=1000 type=http;
interval表示每隔3000毫秒向后端发送健康检查包
rise表示如果连续成功次数达到2 服务器就被认为是up
fail表示如果连续失败次数达到5 服务器就被认为是down
timeout表示后端健康请求的超时时间是1000毫秒
type表示发送的健康检查包是http请求
#检查间隔=3000上升=2下降=5超时=1000类型=http;
check_http_send"HEAD / HTTP/1.0\r\n\r\n";
检查http发送头
check_http_expect_alivehttp_2xx http_3xx;
#check_http期望alivehttp
check_http_send 表示http健康检查包发送的请求内容。为了减少传输数据量,推荐采用“head”方法
第45行
check_http_expect_alive 指定HTTP回复的成功状态,默认认为2XX和3XX的状态是健康的。
* 关闭服务
# sbin/nginx -s stop
* 重新加载配置项
# sbin/nginx -s reload
* 校验conf文件夹中nginx.conf文件格式是否正确
# sbin/nginx -t
* 帮助命令
# sbin/nginx -h
配置nginx.conf
vim nginx.conf
server {
location /status {
check_status;
access_log off;
allow SOME.IP.ADDRESS
deny all;
}
}
在upstream配置如下
check interval=3000 rise=2 fall=5 timeout=1000 type=http;
check_http_send"HEAD / HTTP/1.0\r\n\r\n";
check_http_expect_alivehttp_2xx http_3xx;
3、MySQL有几种安装方式,分别怎么安装和卸载,主要进行解压通用版本安装,并且了解mysql中比较常用的命令
安装
yum - y install mysql-servse
- 1
启动mysql服务
service mysqld start
运行端口为3306
- 1
- 2
登陆
mysql -uroot
- 1
语法 :mysql -u账号 -p密码
默认是空密码
库和表
层次关系
库-->表
create database 库名;创建一个库
show database;查看有哪些库
use 库名;进入这个库
show tables;查看表
- 1
- 2
- 3
- 4
- 5
- 6
创建表
CREATE TABLE fruits(
f_id CHAR(10) PRIMARY KEY,
s_id INT NOT NULL,
f_name char(255) NOT NULL,
f_price DECIMAL(8,2) NOT NULL,
);
- 1
- 2
- 3
- 4
- 5
- 6
语法 CREATE TABLE 表名(
列名 类型,约束条件,
);
后面要用,隔开
内容如图所示
| f_id | s_id | f_name | f_price |
|---|
添加数据
INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('a1',101,'apple',5.2);
INSERT INTO fruits(f_id,s_id,f_name,f_price)VALUES('b1',101,'blackberry',10.2);
INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('bs1',102,'orange',11.2);
INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('bs2',105,'melon',8.2);
INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('t1',102,'banana',10.3);
INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('t2',102,'grape', 5.3);
INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('o2',103,'coconut',9.2);
INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('c0',101,'cherry',3.2);
INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('a2',103,'apricot',2.2);
INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES('l2',104,'lemon',6.4);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
格式:
INSERT INTO 表名(列1,列2,列3) VALUES(值1,值2,值3);
如果值的类型是字符型需要加引号。
更新表
uodate fruits set f_name='sss' where s_id=‘101’ ;
- 1
删除表
delete from fruits where s_id=‘102’;
- 1
查询(以刚才创建的表为例)
查询所有字段
select * from fruits
- 1

查询制定字段
select * from fruits where f_name='apple'
- 1

带IN关键字查询
IN(aa,bb)满足条件范围内的一个值即可匹配。
select * from fruits where f_name IN ('apple‘,’orange‘)
- 1
- 2
between and 范围查询用法
select * from fruits where f_price between 5 and 15;
查询价格在5到15之间的全部信息
- 1
- 2
空值查询
SELECT * FROM 表名 WHERE 字段名 IS NULL;
//查询字段名是NULL的记录
SELECT * FROM 表名 WHERE 字段名 IS NOT NULL;
//查询字段名不是NULL的记录
- 1
- 2
- 3
- 4
带AND的多条件查询
selcet * from fruits where s_id=101 and f_price>5;
- 1
带or的多条件查询
selcet * from fruits where s_id=101 or f_price>5;
- 1
关键字DISTINCT(查询结果不重复)
select distinct s_id from fruits;
- 1
对查询结果排序(order by)
select distinct s_id from fruits order by s_id;
通过s_id进行排序,默认升序
select distinct s_id from fruits order by s_id desc;
降序排列
- 1
- 2
- 3
- 4
分组查询(group by)
s_id,count(f_name),group_concat(f_name) from fruits group by s_id;
对分组过后的结果可以进行having过滤
select s_id,count(f_name),group_concat(f_name)
from fruits group by s_id having count(f_name) > 1
- 1
- 2
- 3
- 4
limit限制查询结果的数量
select * from fruits limit 4;
- 1
集合函数查询
select conut(*) from fruits;
select SUM(f_price)from fruits;
select AVG(f_price)from fruits;
select MAX(f_price)from fruits;
select MIN(f_price)from fruits;
- 1
- 2
- 3
- 4
- 5
多表查询
select s.s_id,s.s_name,f.f_name,f.f_id
from 表一 as s ,表二 as f
where f.s_id = s.s_id
//fruits 和suppliers为表名
- 1
- 2
- 3
- 4
表一用s表示,表二用f表示

内连查询inner join表名 on 连接条件
select s.s_id,s.s_name,f.f_name,f.f_id
from 表一 as s INER JOIN表二 as f
ON f.s_id = s.s_id- 1
- 2
- 3

4、redis的密码和持久化设置,redis基本操作命令了解,info信息基本解读
find / -name dump.rdb
find / -name redis.conf
众所周知,redis是内存数据库,它把数据存储在内存中,这样在加快读取速度的同时也对数据安全性产生了新的问题,即当redis所在服务器发生宕机后,redis数据库里的所有数据将会全部丢失。
为了解决这个问题,redis提供了持久化功能——RDB和AOF。通俗的讲就是将内存中的数据写入硬盘中。
一、持久化之全量写入:RDB

[redis@6381]$ more /usr/local/redis/conf/redis.conf save 900 1 save 300 10 save 60 10000 dbfilename "dump.rdb" #持久化文件名称 dir "/data/dbs/redis/6381" #持久化数据文件存放的路径
redis是一款开源的、高性能的键-值存储(key-value store),和memcached类似,redis常被称作是一款key-value内存存储系统或者内存数据库,同时由于它支持丰富的数据结构,又被称为一种数据结构服务器(data structure server)。
编译完redis,它的配置文件在源码目录下 redis.conf ,将其拷贝到工作目录下即可使用,下面具体解释redis.conf中的各个参数:
1 daemonize no
默认情况下,redis 不是在后台运行的,如果需要在后台运行,把该项的值更改为yes。
2 pidfile /var/run/redis.pid
当Redis 在后台运行的时候,Redis 默认会把pid 文件放在/var/run/redis.pid,你可以配置到其他地址。当运行多个redis 服务时,需要指定不同的pid 文件和端口
3 port
监听端口,默认为6379
4 #bind 127.0.0.1
指定Redis 只接收来自于该IP 地址的请求,如果不进行设置,那么将处理所有请求,在生产环境中为了安全最好设置该项。默认注释掉,不开启
5 timeout 0
设置客户端连接时的超时时间,单位为秒。当客户端在这段时间内没有发出任何指令,那么关闭该连接
6 tcp-keepalive 0
指定TCP连接是否为长连接,"侦探"信号有server端维护。默认为0.表示禁用
7 loglevel notice
log 等级分为4 级,debug,verbose, notice, 和warning。生产环境下一般开启notice
8 logfile stdout
配置log 文件地址,默认使用标准输出,即打印在命令行终端的窗口上,修改为日志文件目录
9 databases 16
设置数据库的个数,可以使用SELECT 命令来切换数据库。默认使用的数据库是0号库。默认16个库
10
save 900 1
save 300 10
save 60 10000
保存数据快照的频率,即将数据持久化到dump.rdb文件中的频度。用来描述"在多少秒期间至少多少个变更操作"触发snapshot数据保存动作
默认设置,意思是:
if(在60 秒之内有10000 个keys 发生变化时){
进行镜像备份
}else if(在300 秒之内有10 个keys 发生了变化){
进行镜像备份
}else if(在900 秒之内有1 个keys 发生了变化){
进行镜像备份
}
11 stop-writes-on-bgsave-error yes
当持久化出现错误时,是否依然继续进行工作,是否终止所有的客户端write请求。默认设置"yes"表示终止,一旦snapshot数据保存故障,那么此server为只读服务。如果为"no",那么此次snapshot将失败,但下一次snapshot不会受到影响,不过如果出现故障,数据只能恢复到"最近一个成功点"
12 rdbcompression yes
在进行数据镜像备份时,是否启用rdb文件压缩手段,默认为yes。压缩可能需要额外的cpu开支,不过这能够有效的减小rdb文件的大,有利于存储/备份/传输/数据恢复
13 rdbchecksum yes
读取和写入时候,会损失10%性能
14 rdbchecksum yes
是否进行校验和,是否对rdb文件使用CRC64校验和,默认为"yes",那么每个rdb文件内容的末尾都会追加CRC校验和,利于第三方校验工具检测文件完整性
14 dbfilename dump.rdb
镜像备份文件的文件名,默认为 dump.rdb
15 dir ./
数据库镜像备份的文件rdb/AOF文件放置的路径。这里的路径跟文件名要分开配置是因为Redis 在进行备份时,先会将当前数据库的状态写入到一个临时文件中,等备份完成时,再把该临时文件替换为上面所指定的文件,而这里的临时文件和上面所配置的备份文件都会放在这个指定的路径当中
16 # slaveof <masterip> <masterport>
设置该数据库为其他数据库的从数据库,并为其指定master信息。
17 masterauth
当主数据库连接需要密码验证时,在这里指定
18 slave-serve-stale-data yes
当主master服务器挂机或主从复制在进行时,是否依然可以允许客户访问可能过期的数据。在"yes"情况下,slave继续向客户端提供只读服务,有可能此时的数据已经过期;在"no"情况下,任何向此server发送的数据请求服务(包括客户端和此server的slave)都将被告知"error"
19 slave-read-only yes
slave是否为"只读",强烈建议为"yes"
20 # repl-ping-slave-period 10
slave向指定的master发送ping消息的时间间隔(秒),默认为10
21 # repl-timeout 60
slave与master通讯中,最大空闲时间,默认60秒.超时将导致连接关闭
22 repl-disable-tcp-nodelay no
slave与master的连接,是否禁用TCP nodelay选项。"yes"表示禁用,那么socket通讯中数据将会以packet方式发送(packet大小受到socket buffer限制)。
可以提高socket通讯的效率(tcp交互次数),但是小数据将会被buffer,不会被立即发送,对于接受者可能存在延迟。"no"表示开启tcp nodelay选项,任何数据都会被立即发送,及时性较好,但是效率较低,建议设为no
23 slave-priority 100
适用Sentinel模块(unstable,M-S集群管理和监控),需要额外的配置文件支持。slave的权重值,默认100.当master失效后,Sentinel将会从slave列表中找到权重值最低(>0)的slave,并提升为master。如果权重值为0,表示此slave为"观察者",不参与master选举
24 # requirepass foobared
设置客户端连接后进行任何其他指定前需要使用的密码。警告:因为redis 速度相当快,所以在一台比较好的服务器下,一个外部的用户可以在一秒钟进行150K 次的密码尝试,这意味着你需要指定非常非常强大的密码来防止暴力破解。
25 # rename-command CONFIG 3ed984507a5dcd722aeade310065ce5d (方式:MD5('CONFIG^!'))
重命名指令,对于一些与"server"控制有关的指令,可能不希望远程客户端(非管理员用户)链接随意使用,那么就可以把这些指令重命名为"难以阅读"的其他字符串
26 # maxclients 10000
限制同时连接的客户数量。当连接数超过这个值时,redis 将不再接收其他连接请求,客户端尝试连接时将收到error 信息。默认为10000,要考虑系统文件描述符限制,不宜过大,浪费文件描述符,具体多少根据具体情况而定
27 # maxmemory <bytes>
redis-cache所能使用的最大内存(bytes),默认为0,表示"无限制",最终由OS物理内存大小决定(如果物理内存不足,有可能会使用swap)。此值尽量不要超过机器的物理内存尺寸,从性能和实施的角度考虑,可以为物理内存3/4。此配置需要和"maxmemory-policy"配合使用,当redis中内存数据达到maxmemory时,触发"清除策略"。在"内存不足"时,任何write操作(比如set,lpush等)都会触发"清除策略"的执行。在实际环境中,建议redis的所有物理机器的硬件配置保持一致(内存一致),同时确保master/slave中"maxmemory""policy"配置一致。
当内存满了的时候,如果还接收到set 命令,redis 将先尝试剔除设置过expire 信息的key,而不管该key 的过期时间还没有到达。在删除时,
将按照过期时间进行删除,最早将要被过期的key 将最先被删除。如果带有expire 信息的key 都删光了,内存还不够用,那么将返回错误。这样,redis 将不再接收写请求,只接收get 请求。maxmemory 的设置比较适合于把redis 当作于类似memcached的缓存来使用。
28 # maxmemory-policy volatile-lru
内存不足"时,数据清除策略,默认为"volatile-lru"。
volatile-lru ->对"过期集合"中的数据采取LRU(近期最少使用)算法.如果对key使用"expire"指令指定了过期时间,那么此key将会被添加到"过期集合"中。将已经过期/LRU的数据优先移除.如果"过期集合"中全部移除仍不能满足内存需求,将OOM.
allkeys-lru ->对所有的数据,采用LRU算法
volatile-random ->对"过期集合"中的数据采取"随即选取"算法,并移除选中的K-V,直到"内存足够"为止. 如果如果"过期集合"中全部移除全部移除仍不能满足,将OOM
allkeys-random ->对所有的数据,采取"随机选取"算法,并移除选中的K-V,直到"内存足够"为止
volatile-ttl ->对"过期集合"中的数据采取TTL算法(最小存活时间),移除即将过期的数据.
noeviction ->不做任何干扰操作,直接返回OOM异常
另外,如果数据的过期不会对"应用系统"带来异常,且系统中write操作比较密集,建议采取"allkeys-lru"
29 # maxmemory-samples 3
默认值3,上面LRU和最小TTL策略并非严谨的策略,而是大约估算的方式,因此可以选择取样值以便检查
29 appendonly no
默认情况下,redis 会在后台异步的把数据库镜像备份到磁盘,但是该备份是非常耗时的,而且备份也不能很频繁。所以redis 提供了另外一种更加高效的数据库备份及灾难恢复方式。开启append only 模式之后,redis 会把所接收到的每一次写操作请求都追加到appendonly.aof 文件中,当redis 重新启动时,会从该文件恢复出之前的状态。但是这样会造成appendonly.aof 文件过大,所以redis 还支持了BGREWRITEAOF 指令,对appendonly.aof 进行重新整理。如果不经常进行数据迁移操作,推荐生产环境下的做法为关闭镜像,开启appendonly.aof,同时可以选择在访问较少的时间每天对appendonly.aof 进行重写一次。
另外,对master机器,主要负责写,建议使用AOF,对于slave,主要负责读,挑选出1-2台开启AOF,其余的建议关闭
30 # appendfilename appendonly.aof
aof文件名字,默认为appendonly.aof
31
# appendfsync always
appendfsync everysec
# appendfsync no
设置对appendonly.aof 文件进行同步的频率。always 表示每次有写操作都进行同步,everysec 表示对写操作进行累积,每秒同步一次。no不主动fsync,由OS自己来完成。这个需要根据实际业务场景进行配置
32 no-appendfsync-on-rewrite no
在aof rewrite期间,是否对aof新记录的append暂缓使用文件同步策略,主要考虑磁盘IO开支和请求阻塞时间。默认为no,表示"不暂缓",新的aof记录仍然会被立即同步
33 auto-aof-rewrite-percentage 100
当Aof log增长超过指定比例时,重写log file, 设置为0表示不自动重写Aof 日志,重写是为了使aof体积保持最小,而确保保存最完整的数据。
34 auto-aof-rewrite-min-size 64mb
触发aof rewrite的最小文件尺寸
35 lua-time-limit 5000
lua脚本运行的最大时间
36 slowlog-log-slower-than 10000
"慢操作日志"记录,单位:微秒(百万分之一秒,1000 * 1000),如果操作时间超过此值,将会把command信息"记录"起来.(内存,非文件)。其中"操作时间"不包括网络IO开支,只包括请求达到server后进行"内存实施"的时间."0"表示记录全部操作
37 slowlog-max-len 128
"慢操作日志"保留的最大条数,"记录"将会被队列化,如果超过了此长度,旧记录将会被移除。可以通过"SLOWLOG <subcommand> args"查看慢记录的信息(SLOWLOG get 10,SLOWLOG reset)
38
hash-max-ziplist-entries 512
hash类型的数据结构在编码上可以使用ziplist和hashtable。ziplist的特点就是文件存储(以及内存存储)所需的空间较小,在内容较小时,性能和hashtable几乎一样.因此redis对hash类型默认采取ziplist。如果hash中条目的条目个数或者value长度达到阀值,将会被重构为hashtable。
这个参数指的是ziplist中允许存储的最大条目个数,,默认为512,建议为128
hash-max-ziplist-value 64
ziplist中允许条目value值最大字节数,默认为64,建议为1024
39
list-max-ziplist-entries 512
list-max-ziplist-value 64
对于list类型,将会采取ziplist,linkedlist两种编码类型。解释同上。
40 set-max-intset-entries 512
intset中允许保存的最大条目个数,如果达到阀值,intset将会被重构为hashtable
41
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
zset为有序集合,有2中编码类型:ziplist,skiplist。因为"排序"将会消耗额外的性能,当zset中数据较多时,将会被重构为skiplist。
42 activerehashing yes
是否开启顶层数据结构的rehash功能,如果内存允许,请开启。rehash能够很大程度上提高K-V存取的效率
43
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
客户端buffer控制。在客户端与server进行的交互中,每个连接都会与一个buffer关联,此buffer用来队列化等待被client接受的响应信息。如果client不能及时的消费响应信息,那么buffer将会被不断积压而给server带来内存压力.如果buffer中积压的数据达到阀值,将会导致连接被关闭,buffer被移除。
buffer控制类型包括:normal -> 普通连接;slave ->与slave之间的连接;pubsub ->pub/sub类型连接,此类型的连接,往往会产生此种问题;因为pub端会密集的发布消息,但是sub端可能消费不足.
指令格式:client-output-buffer-limit <class> <hard> <soft> <seconds>",其中hard表示buffer最大值,一旦达到阀值将立即关闭连接;
soft表示"容忍值",它和seconds配合,如果buffer值超过soft且持续时间达到了seconds,也将立即关闭连接,如果超过了soft但是在seconds之后,buffer数据小于了soft,连接将会被保留.
其中hard和soft都设置为0,则表示禁用buffer控制.通常hard值大于soft.
44 hz 10
Redis server执行后台任务的频率,默认为10,此值越大表示redis对"间歇性task"的执行次数越频繁(次数/秒)。"间歇性task"包括"过期集合"检测、关闭"空闲超时"的连接等,此值必须大于0且小于500。此值过小就意味着更多的cpu周期消耗,后台task被轮询的次数更频繁。此值过大意味着"内存敏感"性较差。建议采用默认值。
45
# include /path/to/local.conf
# include /path/to/other.conf
额外载入配置文件。
上面是redis配置文件里默认的RDB持久化设置,前三行都是对触发RDB的一个条件,例如第一行的意思是每900秒钟里redis数据库有一条数据被修改则触发RDB,依次类推;只要有一条满足就会调用BGSAVE进行RDB持久化。第四行dbfilename指定了把内存里的数据库写入本地文件的名称,该文件是进行压缩后的二进制文件,通过该文件可以把数据库还原到生成该文件时数据库的状态。第五行dir指定了RDB文件存放的目录。
配置文件修改需要重启redis服务,我们还可以在命令行里进行配置,即时生效,服务器重启后需重新配置
[redis@iZ254r8s3m6Z redis]$ bin/redis-cli 127.0.0.1:6379> CONFIG GET save #查看redis持久化配置 1) "save" 2) "900 1 300 10 60 10000" 127.0.0.1:6379> CONFIG SET save "21600 1000" #修改redis持久化配置 OK
而RDB持久化也分两种:SAVE和BGSAVE
SAVE是阻塞式的RDB持久化,当执行这个命令时redis的主进程把内存里的数据库状态写入到RDB文件(即上面的dump.rdb)中,直到该文件创建完毕的这段时间内redis将不能处理任何命令请求。
BGSAVE属于非阻塞式的持久化,它会创建一个子进程专门去把内存中的数据库状态写入RDB文件里,同时主进程还可以处理来自客户端的命令请求。但子进程基本是复制的父进程,这等于两个相同大小的redis进程在系统上运行,会造成内存使用率的大幅增加。
(本人在生产中就碰到过这问题,redis本身内存使用率就60%,总的内存使用率在百分之七八十左右,持久化的时候立马飙到百分之一百三十多,告警邮件是每天几十封/(ㄒoㄒ)/~~ 最后根据需求选择了AOF持久化)
二、持久化之增量写入:AOF
与RDB的保存整个redis数据库状态不同,AOF是通过保存对redis服务端的写命令(如set、sadd、rpush)来记录数据库状态的,即保存你对redis数据库的写操作,以下就是AOF文件的内容
1 [redis@iZ]$ more appendonly.aof 2 *2 3 $6 4 SELECT 5 $1 6 0 7 *3 8 $3 9 SET 10 $47 11 DEV_USER_LEGAL_F9683BE0E27F1A06C0CB869CEC7E3B22 12 $11 13 ¬ 14 *3 15 $3 16 SET 17 $47
先让我们看看如何配置AOF
1 [redis@iZ]$ more ~/redis/conf/redis.conf 2 dir "/data/dbs/redis/6381" #AOF文件存放目录 3 appendonly yes #开启AOF持久化,默认关闭 4 appendfilename "appendonly.aof" #AOF文件名称(默认) 5 appendfsync no #AOF持久化策略 6 auto-aof-rewrite-percentage 100 #触发AOF文件重写的条件(默认) 7 auto-aof-rewrite-min-size 64mb #触发AOF文件重写的条件(默认)
要弄明白上面几个配置就得从AOF的实现去理解,AOF的持久化是通过命令追加、文件写入和文件同步三个步骤实现的。当reids开启AOF后,服务端每执行一次写操作(如set、sadd、rpush)就会把该条命令追加到一个单独的AOF缓冲区的末尾,这就是命令追加;然后把AOF缓冲区的内容写入AOF文件里。看上去第二步就已经完成AOF持久化了那第三步是干什么的呢?这就需要从系统的文件写入机制说起:一般我们现在所使用的操作系统,为了提高文件的写入效率,都会有一个写入策略,即当你往硬盘写入数据时,操作系统不是实时的将数据写入硬盘,而是先把数据暂时的保存在一个内存缓冲区里,等到这个内存缓冲区的空间被填满或者是超过了设定的时限后才会真正的把缓冲区内的数据写入硬盘中。也就是说当redis进行到第二步文件写入的时候,从用户的角度看是已经把AOF缓冲区里的数据写入到AOF文件了,但对系统而言只不过是把AOF缓冲区的内容放到了另一个内存缓冲区里而已,之后redis还需要进行文件同步把该内存缓冲区里的数据真正写入硬盘上才算是完成了一次持久化。而何时进行文件同步则是根据配置的appendfsync来进行:
appendfsync有三个选项:always、everysec和no:
1、选择always的时候服务器会在每执行一个事件就把AOF缓冲区的内容强制性的写入硬盘上的AOF文件里,可以看成你每执行一个redis写入命令就往AOF文件里记录这条命令,这保证了数据持久化的完整性,但效率是最慢的,却也是最安全的;
2、配置成everysec的话服务端每执行一次写操作(如set、sadd、rpush)也会把该条命令追加到一个单独的AOF缓冲区的末尾,并将AOF缓冲区写入AOF文件,然后每隔一秒才会进行一次文件同步把内存缓冲区里的AOF缓存数据真正写入AOF文件里,这个模式兼顾了效率的同时也保证了数据的完整性,即使在服务器宕机也只会丢失一秒内对redis数据库做的修改;
3、将appendfsync配置成no则意味redis数据库里的数据就算丢失你也可以接受,它也会把每条写命令追加到AOF缓冲区的末尾,然后写入文件,但什么时候进行文件同步真正把数据写入AOF文件里则由系统自身决定,即当内存缓冲区的空间被填满或者是超过了设定的时限后系统自动同步。这种模式下效率是最快的,但对数据来说也是最不安全的,如果redis里的数据都是从后台数据库如mysql中取出来的,属于随时可以找回或者不重要的数据,那么可以考虑设置成这种模式。
相比RDB每次持久化都会内存翻倍,AOF持久化除了在第一次启用时会新开一个子进程创建AOF文件会大幅度消耗内存外,之后的每次持久化对内存使用都很小。但AOF也有一个不可忽视的问题:AOF文件过大。你对redis数据库的每一次写操作都会让AOF文件里增加一条数据,久而久之这个文件会形成一个庞然大物。还好的是redis提出了AOF重写的机制,即我们上面配置的auto-aof-rewrite-percentage和auto-aof-rewrite-min-size。AOF重写机制这里暂不细述,之后本人会另开博文对此解释,有兴趣的同学可以看看。我们只要知道AOF重写既是重新创建一个精简化的AOF文件,里面去掉了多余的冗余命令,并对原AOF文件进行覆盖。这保证了AOF文件大小处于让人可以接受的地步。而上面的auto-aof-rewrite-percentage和auto-aof-rewrite-min-size配置触发AOF重写的条件。
Redis 会记录上次重写后AOF文件的文件大小,而当前AOF文件大小跟上次重写后AOF文件大小的百分比超过auto-aof-rewrite-percentage设置的值,同时当前AOF文件大小也超过auto-aof-rewrite-min-size设置的最小值,则会触发AOF文件重写。以上面的配置为例,当现在的AOF文件大于64mb同时也大于上次重写AOF后的文件大小,则该文件就会被AOF重写。
最后需要注意的是,如果redis开启了AOF持久化功能,那么当redis服务重启时会优先使用AOF文件来还原数据库。
5、zookeeper基本操作和了解
6、通过Java命令看进程,看Java进程的堆栈信息
jps(Java Virtual Machine Process Status Tool)
是java提供的一个显示当前所有java进程pid的命令,适合在linux/unix平台上简单察看当前java进程的一些简单情况。
很多人都是用过unix系统里的ps命令,这个命令主要是用来显示当前系统的进程情况,有哪些进程以及进程id。
jps 也是一样,它的作用是显示当前系统的java进程情况及进程id。
我们可以通过它来查看我们到底启动了几个java进程(因为每一个java程序都会独占一个java虚拟机实例)
并可通过opt来查看这些进程的详细启动参数。
1.使用方法:
注:在当前命令行下打jps(jps存放在JAVA_HOME/bin/jps,使用时为了方便需将JAVA_HOME/bin/加入到Path) 。
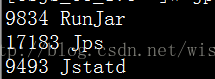
$> jps
23991 Jps
23651 Resin
2.常用参数:
-q 只显示pid,不显示class名称,jar文件名和传递给main方法的参数
$> jps -q
28680
23789
-m 输出传递给main方法的参数,在嵌入式jvm上可能是null
$> jps -m
28715 Jps -m
23789 BossMain
-l 输出应用程序main class的完整package名或者应用程序的jar文件完整路径名
$> jps -l
28729 sun.tools.jps.Jps
23789 com.asiainfo.aimc.bossbi.BossMain
23651
23651 Resin -socketwait 32768 -stdout /resin/log/stdout.log -stderr /resin/log/stderr.log
23651 com.caucho.server.resin.Resin
-v 输出传递给JVM的参数
$> jps -v
-V 隐藏输出传递给JVM的参数
$> jps -V
jps是jdk提供的一个查看当前java进程的小工具, 可以看做是JavaVirtual Machine Process Status Tool的缩写。非常简单实用。
命令格式:jps [options ] [ hostid ]
[options]选项 :
-q:仅输出VM标识符,不包括classname,jar name,arguments in main method
-m:输出main method的参数
-l:输出完全的包名,应用主类名,jar的完全路径名
-v:输出jvm参数
-V:输出通过flag文件传递到JVM中的参数(.hotspotrc文件或-XX:Flags=所指定的文件
-Joption:传递参数到vm,例如:-J-Xms512m
[hostid]:
[protocol:][[//]hostname][:port][/servername]
命令的输出格式 :
lvmid [ [ classname| JARfilename | "Unknown"] [ arg* ] [ jvmarg* ] ]
1)jps
2)jps –l:输出主类或者jar的完全路径名

3)jps –v :输出jvm参数

4)jps –q :仅仅显示java进程号
5)jps -mlv10.134.68.173

jps -lvm 这个命令可以显示出程序,对应的进程号等,有关参数这里不讲述,如下:
查看对应程序的堆栈信息,就是找到进程号,执行jstack命令
jstack -l 5659 这样就可以看堆栈信息了,这个是实时刷的,可以 写入一个文件中进行查看: jstack -l 5659 > 1.txt
7、mysql,mysqldump命令的操作,mysql基本操作命令
linux环境使用mysqldump备份或者导出数据库
1.安装mysqldump命令 yum -y install holland-mysqldump.noarch (如果已经安装请忽略)
2.使用命令导出数据库全部信息(所有表)
mysqldump -h主机名 -P端口 -u数据库用户名 -p数据库密码 (–database) 数据库名 > 文件名.sql
例如:mysqldump -h1.1.1.1 -P3306 -uroot -p123456 xxxxx > /backfile1.sql
-h表示host,1.1.1.1是数据库ip,这里也可以是数据库域名
-P表示端口,3306是数据库端口
-u表示数据库用户名,root是数据库用户名
-p表示数据库密码,12345是密码
xxxxx是数据库名
/backfile1.sql表示要把备份数据库信息导出到的文件
3.使用命令导出数据库指定表数据
mysqldump -h1.1.1.1 -P3306 -uroot -p123456 xxxxx --tables table_1 table_2 > /backfile2.sql
table_1 table_2指的表名
mysqldump -h127.0.0.1 -P3306 -uroot -p123456 crm2 > backfile1.sql
8、怎样通过命令查看网络情况和io使用情况
备份/恢复案例
#数据库备份/恢复实验一:数据库损坏 备份: 1. # mysqldump -uroot -p123 --all-databases > /backup/`date +%F`_all.sql 2. # mysql -uroot -p123 -e 'flush logs' //截断并产生新的binlog 3. 插入数据 //模拟服务器正常运行 4. mysql> set sql_log_bin=0; //模拟服务器损坏 mysql> drop database db; 恢复: 1. # mysqlbinlog 最后一个binlog > /backup/last_bin.log 2. mysql> set sql_log_bin=0; mysql> source /backup/2014-02-13_all.sql //恢复最近一次完全备份 mysql> source /backup/last_bin.log //恢复最后个binlog文件 #数据库备份/恢复实验二:如果有误删除 备份: 1. mysqldump -uroot -p123 --all-databases > /backup/`date +%F`_all.sql 2. mysql -uroot -p123 -e 'flush logs' //截断并产生新的binlog 3. 插入数据 //模拟服务器正常运行 4. drop table db1.t1 //模拟误删除 5. 插入数据 //模拟服务器正常运行 恢复: 1. # mysqlbinlog 最后一个binlog --stop-position=260 > /tmp/1.sql # mysqlbinlog 最后一个binlog --start-position=900 > /tmp/2.sql 2. mysql> set sql_log_bin=0; mysql> source /backup/2014-02-13_all.sql //恢复最近一次完全备份 mysql> source /tmp/1.log //恢复最后个binlog文件 mysql> source /tmp/2.log //恢复最后个binlog文件 注意事项: 1. 完全恢复到一个干净的环境(例如新的数据库或删除原有的数据库) 2. 恢复期间所有SQL语句不应该记录到binlog中
9、查找指定文件,查看某个文件大小和权限

 浙公网安备 33010602011771号
浙公网安备 33010602011771号