#include <stdio.h>
#include <string.h>
char prog[800], token[20];
char ch;
int syn,p,m,n,sum;
char * rwtab[6]= {"begin","if","then","while","do","end"};
main()
{
p=0;
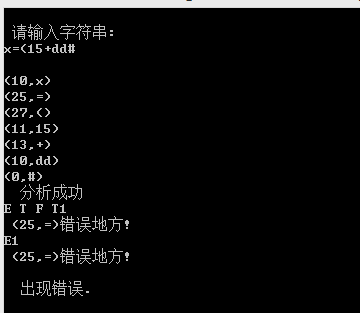
printf("\n 请输入字符串: \n");
do{
ch=getchar();
prog[p++]=ch;
}while (ch!='#');
p=0;
do{
scaner();
switch(syn)
{
case 11: printf("\n(%d,%d)",syn,sum); break;
case -1: printf("\n(%s,出错!)",token);break;
default: printf("\n(%d,%s)",syn, token);
}
}while (syn!=0);
printf("\n 分析成功 \n");
p=0;
scaner();
E();
if (syn==0)
printf("\n 没有错误. \n");
else printf("\n 出现错误. \n");
}
scaner()
{
for (n=0;n<20;n++) token[n]=NULL;
m=0;
sum=0;
ch=prog[p++];
while (ch==' ') {ch=prog[p++];}
if (ch>='a'&& ch<='z')
{while (ch>='a'&& ch<='z'||ch>='0' && ch<='9')
{
token[m++]=ch;
ch=prog[p++];
}
syn=10;p--;
for (n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0) {syn=n+1;break;}
}
else
if(ch>='0' && ch<='9')
{while (ch>='0' && ch<='9') {sum=sum*10+(ch-'0'); ch=prog[p++];}
syn=11;p--;
}
else
switch(ch)
{
case '<': token[m++]=ch;
ch=prog[p++];
if (ch=='>') {syn=21;token[m++]=ch;}
else if (ch=='=') {syn=22;token[m++]=ch;}
else {syn=20;p--;}
break;
case '>': m=0; token[m++]=ch;
ch=prog[p++];
if (ch=='='){syn=24;token[m++]=ch;}
else {syn=23;p--;}
break;
case ':': m=0; token[m++]=ch;
ch=prog[p++];
if (ch=='='){syn=18;token[m++]=ch;}
else {syn=17;p--;}
break;
case '+': syn=13;token[0]=ch;break;
case '-': syn=14;token[0]=ch;break;
case '*': syn=15;token[0]=ch;break;
case '/': syn=16;token[0]=ch;break;
case '=': syn=25;token[0]=ch;break;
case ';': syn=26;token[0]=ch;break;
case '(': syn=27;token[0]=ch;break;
case ')': syn=28;token[0]=ch;break;
case '#': syn=0; token[0]=ch;break;
default: syn=-1;token[0]=ch;
}
}
E()
{printf("E ");
T();
E1();
}
E1()
{printf("E1 ");
if (syn==13) {
scaner();
T();
E1();
}
else {
if (syn!=28 && syn!=0) error();
}
}
T()
{printf("T ");
F();
T1();
}
T1()
{printf("T1 ");
if (syn==15) {
scaner();
F();
T1();
}
else {
if (syn!=28 && syn!=0 && syn!=13) error();
}
}
F()
{printf("F ");
if (syn==27) {
scaner();
E();
if(syn==28) scaner();
else error();
}
else if (syn==11 || syn==10) scaner();
}
error()
{
printf("\n (%d,%s)错误地方! \n",syn, token);
}