
输入流和输出流
在说乱码产生的原因时,我们先了解一下输入流和输出流的概念来帮助理解。
输入流
输入流就是把数据(键盘输入、鼠标、扫描仪等等外设设备)读入到内存(程序)中。
从文件的角度来说,输入流就是读数据。
输出流
输出流就是把内存(程序)中的数据输出到外设或其他地方.
从文件的角度来说,输出流就是写数据。
简单了解几种编码方式(想深入了解的可自行查找相关知识)
iso8859-1编码
属于单字节编码,最多能表示的字符范围是0-255,应用于英文系列。比如,字母a的编码为0x61=97。
GB2312/GBK编码
这就是汉字的国标码,专门用来表示汉字,是双字节编码,而英文字母和iso8859-1一致(兼容iso8859-1编码)。其中gbk编码能够用来同时表示繁体字和简体字,而 gb2312只能表示简体字,gbk是兼容gb2312编 码的。
unicode编码
这是最统一的编码,可以用来表示所有语言的字符,而且是定长双字节(也有四字节的)编码,包括英文字母在内。所以可以说它是不兼容iso8859-1编码的,也不兼容任何编码。不过,相对于iso8859-1编码来说,uniocode编码只是在前面增加了一个0字节,比如字母a为"00 61"。需要说明的是,定长编码便于计算机处理(注意GB2312/GBK不是定长编码),而unicode又可以用来表示所有字符,所以在很多软件内部是使用 unicode编码来处理的,比如java。
UTF编码
考虑到unicode编码不兼容iso8859-1编码,而且容易占用更多的空间:因为对于英文字母,unicode也需要两个字节来表示。所以unicode不便于传输和存储。因此而产生了utf编码,utf编码兼容iso8859-1编码,同时也可以用来表示所有语言的字符,不过,utf编码是不定长编码,每一个字符的长度从1-6个字节不等。另外,utf编码自带简单的校验功能。一般来讲,英文字母都是用一个字节表示,而汉字使用三个字节。
乱码产生的原因
下面是我个人简单的理解,希望能够帮助理解。
首先你必须得知道不同类型的文件编码形式是不同的,不同的编码形式转换二进制数据时每次形式也不同。
当你将以x类型存储的a文件以另一种类型y打开为新文件b时,其过程如下:
数据的取出:以x类型存储的a文件中的信息会通过输出流将其转化为一种基本的二进制数据,这就像一种翻译的过程,然后就像一串流水一样存储在缓冲区里。
数据的取入:当你想要以另一种类型y来打开a文件时,此时y会通过输入流从缓冲区里来读取这一串二进制数据来放入新的文件b中。
问题就出在数据的转换:假设类型x转换二进制数据时是以2个字节来依次转换的,而方式y是以4个字节来依次转换的,此时b文件中存储的信息是以读入的二进制数据按照4个字节的周期来“翻译”的,所以很理所当然的就出现了乱码的情况。
下面是更加生动形象的例子
这个过程就像你将英文翻译为中文,而你又将中文翻译为日语。这很显然的英文和日语是不同类型的语言,就像在一个不懂日语的英国人眼里,日语就是乱码。同理,在一个不懂英语的日本人眼里,英语就是乱码。
下列我将一个jpg类型的图片以txt打开,很显然会出现乱码
下面为原图

下面我以txt类型打开
很显然图片类型的文件必须要以打开图片的方式打开,所以一定会出现乱码。
在JAVA中再试一试
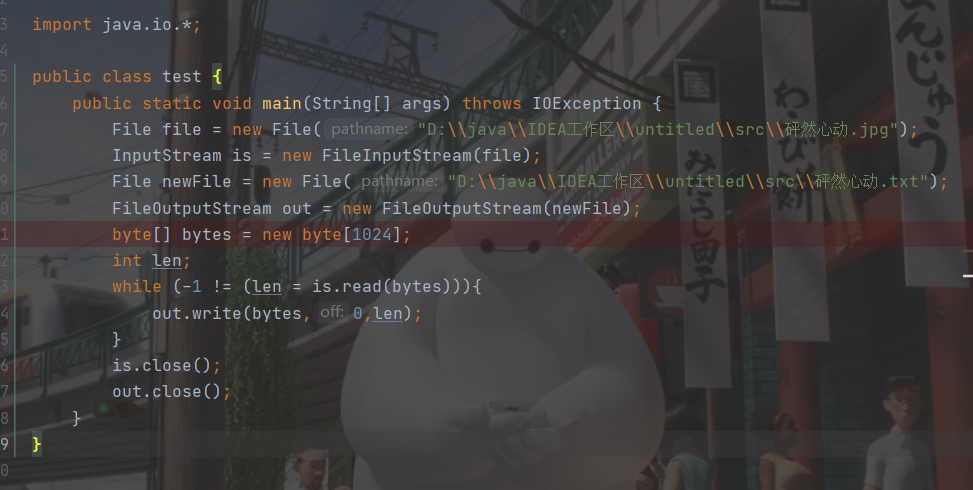
此时打开txt文档同样发生乱码

后将txt文档转换为jpg模式,发现变回了原来的样子。
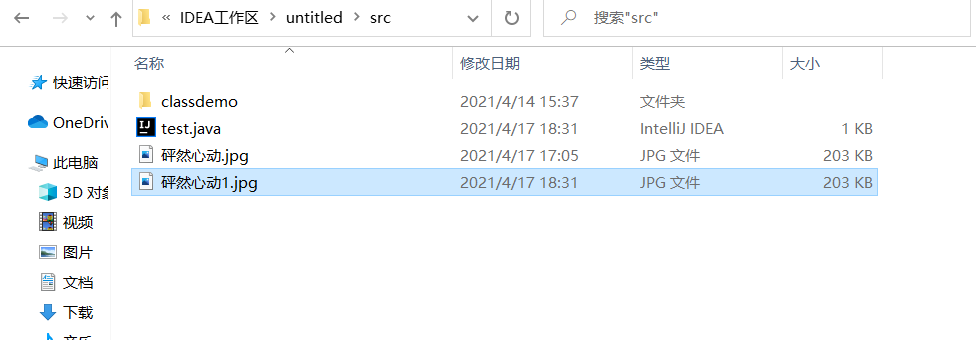
这个例子很形象的说明了虽然发生了乱码,但是最基本的二进制数据还是不变的,只是“翻译”不同而已。


