
机器学习---12
import csv
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
# 词性pos赋值
def get_word_pos(tag):
if tag.startswith('J'):
return nltk.corpus.wordnet.ADJ
elif tag.startswith('V'):
return nltk.corpus.wordnet.VERB
elif tag.startswith('N'):
return nltk.corpus.wordnet.NOUN
elif tag.startswith('R'):
return nltk.corpus.wordnet.ADV
else:
return ''
#预处理
def pre(data):
#分割单词
word = []
for sent in nltk.sent_tokenize(data):
for words in nltk.word_tokenize(sent):
word.append(words)
#消除常用单词
stops = stopwords.words('english')
word = [w.lower() for w in word if w not in stops]
#消除特斯符号
sep = '\.,:;?!-"\'_=!@#$%^&*()'
word = [w.strip(sep) for w in word]
#消除一些单词位短的单词
newword = []
for w in word:
if len(w) >= 2:
newword.append(w)
lr = WordNetLemmatizer()
tag = nltk.pos_tag(newword)
#根据pos还原单词
newtag = []
for i,ts in enumerate(tag):
if ts:
po = get_word_pos(tag[i][1])
if po:
wd =lr.lemmatize(ts[0],pos=po)
newtag.append(wd)
else:
newtag.append(ts[0])
else:
newtag.append(ts[0])
newstr=' '.join(newtag)
return newstr
#邮件信息导入
file_path=r'SMSSpamCollectio'
sms=open(file_path,'r',encoding='utf-8')
sms_data=[]
sms_label=[]
csv_reader=csv.reader(sms,delimiter='\t')
for line in csv_reader:
sms_label.append(line[0])
sms_data.append(pre(line[1]))
sms.close()
#完成单词处理
#数据划分—训练集和测试集数据划分
from sklearn.model_selection import train_test_split
x_train,x_test, y_train, y_test = train_test_split(sms_data, sms_label, test_size=0.2, random_state=0, stratify=sms_label)
# print(len(x_train))
# print(len(x_test))
# 将其向量化
from sklearn.feature_extraction.text import TfidfVectorizer
TV = TfidfVectorizer()
x_train_tv = TV.fit_transform(x_train)
x_test_tv = TV.transform(x_test)
print(x_train_tv.toarray().shape)
print(x_test_tv.toarray().shape)
import numpy as np
a = np.flatnonzero(x_train_tv.toarray())
#选择多项式朴素贝叶斯分类器模型
from sklearn.naive_bayes import MultinomialNB
clf = MultinomialNB().fit(x_train_tv, y_train)
y_mnb_pre = clf.predict(x_test_tv)
#预测结果
print(y_mnb_pre)
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
# 混淆矩阵
cm = confusion_matrix(y_test, y_mnb_pre)
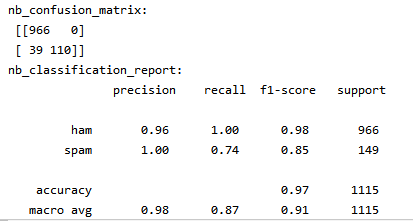
print('nb_confusion_matrix:\n',cm)
# 主要分类指标的文本报告
cr = classification_report(y_test, y_mnb_pre)
print('nb_classification_report:\n',cr)
print((cm[0][0]+cm[1][1])/np.sum(cm))
结果:
1.读取
2.数据预处理
3.数据划分—训练集和测试集数据划分
from sklearn.model_selection import train_test_split
4.文本特征提取
sklearn.feature_extraction.text.CountVectorizer
sklearn.feature_extraction.text.TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
观察邮件与向量的关系

第一个数据是训练数据训练后的向量
第二个数据是测试数据的通过训练模型转换后的向量
两者分类得出的单词数据的精准度其实是比直接总的一个数据来训练要精准
虽然单词量没有后者的多,但是重要单词的验证次数会比其他单词的要多。

4.模型选择
from sklearn.naive_bayes import GaussianNB ×
from sklearn.naive_bayes import MultinomialNB √
MNB模型更适合离散型的数据分类
5.模型评价:混淆矩阵,分类报告
from sklearn.metrics import confusion_matrix
说明混淆矩阵的含义
官方:

混淆矩阵是通过将每个实测像元的位置和分类与分类图像中的相应位置和分类相比较计算的。
理解:

结合垃圾邮件来说明的话,上图中矩阵分为了4个数据,位置对应的说明如下:
正确邮件 垃圾邮件
------------|-------------------------------------|----------------------------------
正确邮件|【把正确邮件当正确邮件 | 把垃圾邮件当正确邮件】
垃圾邮件|【把正确邮件当垃圾邮件 | 把垃圾邮件当垃圾邮件】
就是一个误差模型,把已经知道的结果,和通过训练后得出的结果进行检验,简单说明就是。如果按照你的模型来预测结果,把所有的预测结果分类展示。
from sklearn.metrics import classification_report
说明准确率、精确率、召回率、F值分别代表的意义
先看看官方的:

结合垃圾邮件分类的:
| 精确率 | 召回率 | F1 | 总数 | |
| 正确邮件 | 0.96 | 1.00 | 0.98 | 996 |
| 垃圾邮件 | 1.00 | 0.74 | 0.85 | 149 |
| 分类正确率 | 0.97 | 1115 | ||
| macro平均值 | 0.98 | 0.87 | 0.91 | 1115 |
| weighted平均值 | 0.97 | 0.97 | 0.96 | 1115 |
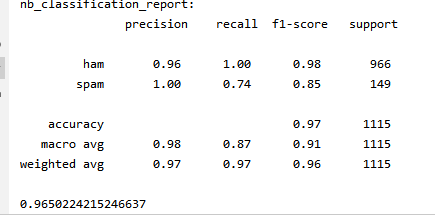
都是用上面混淆矩阵来计算的
6.比较与总结
如果用CountVectorizer进行文本特征生成,与TfidfVectorizer相比,效果如何?
CountVectorizer()函数只考虑每个单词出现的频率;然后构成一个特征矩阵,每一行表示一个训练文本的词频统计结果。其思想是,先根据所有训练文本,不考虑其出现顺序,只将训练文本中每个出现过的词汇单独视为一列特征,构成一个词汇表(vocabulary list),该方法又称为词袋法(Bag of Words)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号