NLP 文献阅读:文本对抗攻击
TextAttack
TextAttack 主要用于 NLP 对抗样本攻击,提供了一系列文本对抗攻击的算法。TextAttack 在 README 里面,列举了不同攻击算法的特性,这些特性如下:
- Goal Function:untargeted/targeted 两种方式。对于分类算法,untargeted 让分类器分错即可,而 targeted 不仅要分类错误,还要让分类器给出指定类别。目前 TextAttack 大多以 untargeted 为主。
- ConstraintEnforced:约束条件,比如 bert-attack 和 bae 会使用 USE 计算语义相似度;其它的约束条件有:扰动率、词向量距离、POS 词性一致、LM 相似度概率、编辑距离。
- Transformation:变换方式,比如 bert-attack 使用 BERT 掩码预测 Token。其它的变换方式有:基于 Counter-fitted/HowNet/WordNet 词向量的替换、命名实体提取扩展替换、字符的插入删除交换替换、基于梯度的单词替换。
- SearchMethod:搜索方法,一般用的是贪心算法。计算单词重要性之后,从最重要的开始尝试替换。其它的搜索算法有:遗传算法、粒子群优化算法(Particle Swarm Optimization)、束搜索(beam search)。

TextFooler
重要性
TextFooler 的单词重要性如下所示,注意下面的公式只对预测正确的样本有效。如果两者预测相等,那么就是预测同一类的差值;如果预测不相等,那么重要性就是预测当前类的差值,加上,预测另一类的差值。
同义词替换
本文使用了 Counter-fitting 词向量,这个词向量更加适合找到同义词。同义词替换的流程如下:
- 同义词提取:利用余弦相似度,提取大于阈值的同义词。
- POS,词性检查,只保留词性一致的单词
- 语义相似度检查,利用了 Universal Sentence Encoder(USE)计算句子向量,计算余弦相似度。
- 如果最后有单词经过了过滤,那么选择 USE 最相似的单词;如果最后没有单词经过过滤,那么选择使预测概率下降最大的词。
流程
TextFooler 和后文中的 BERT-ATTACK、BAE、CLARE 都是遵循着 “重要性排序”(2 ~ 3 行)、“贪心替换”(6 ~ 8 行)、“单词过滤”(10 ~ 19 行)的基本框架,如果可以攻击成功,选择最相似的单词,如果不能攻击成功,选择概率下降最大的单词。重复这个过程(第 8 行),不断进行操作,直到攻击成功或者不能操作为止。

BERT-ATTACK/BAE/CLARE
这三者都是 2020 年的工作,主要创新点是使用 BERT Masked LM 预测单词做替换。BAE 于 4 Apr 2020 挂在 arXiv,BERT-ATTACK 于 21 Apr 2020 挂在 arXiv,而 CLARE 则最晚,于 16 Sep 2020 挂在 arXiv。
操作
三者的共同点都是使用了 BERT 做 Masked LM 预测单词进行替换,每个模型提出的支持的操作不同:
- BAE:支持插入和替换两种操作。
- BERT-ATTACK:仅支持替换。
- CLARE:支持替换、插入、合并三种操作。
重要性
- BAE:将单词从句子中删除掉,预测概率下降的多少。
- BERT-ATTACK:对单词进行掩码,重要性为预测概率在掩码前后的差值。
- CLARE:单个单词中挑选出概率变化最大的操作,句子所有单词中挑选出概率变化最大的一个单词进行操作。
其他
- 三者都是用了 USE 计算句子余弦相似度,经过实践,有时候将单词从 like 变成 hate,仍然可以通过检测,这说明 USE 可能还不够好。
- BERT-ATTACK 考虑了分词,分词的结果可能会将一个单词变成 sub-words,因此预测出多个 sub-words 的组合还要逆向进行分词。
A2T
标题:Towards Improving Adversarial Training of NLP Models
对抗训练是用来提升模型鲁棒性的一种方式,一般是将原始样本和对抗样本混合一起做训练。最新的研究中大多使用了 sentence encoders (比如 USE 计算语义相似度)来对生成的对抗样本进行约束,sentence encoders 计算速度慢导致了对抗样本的生成速度慢,因此想要用对抗训练来提高模型性能,仍然是有挑战的。此外,对抗训练的收益如何也是未知的,对抗训练是否会导致模型在原始数据集上的性能下降,这仍然是需要探索的。
这篇文章提出了一种简单高效的对抗训练方法 A2T(Attacking to Training),使用了基于梯度的单词重要性排序方法,这篇文章的主要贡献如下:
- 对抗训练 A2T 和 A2T-MLM 都有助于提高对抗鲁棒性(A2T 使用 counter-fitted 词向量找同义词,A2T-MLM 使用 Masked LM 找同义词)
- 使用 A2T 做对抗训练有正则化的效果,可以提高模型原始精度;然后 A2T-MLM 则有损于原始精度
- 引入了 LIME 和 AOPC 两个指标,可以帮助展示 A2T 可以提高模型的可解释性。
对抗训练流程
A2T 的主要工作流程如下图所示。首先使用干净的数据训练 N 个 epochs,然后生成对抗样本,混入原始数据集一起训练。作者发现只使用一部分数据集来生成对抗样本进行训练,效果会更好,本文作者使用了 20% 的数据集来生成对抗样本。
下图的 Gamma 表示生成对抗样本的比例。左图可以看到在 0.2 时攻击成功率是最低的;右图可以看到 0.2 对于提高原始精度和跨领域精度是有益的。

加速计算
A2T 使用了两种方法来加速计算:
(1)TextFooler 和 BAE 都是用了 Deletion-based 的方式来计算,每个单词的重要性为删掉这个单词前后预测概率的差值,这种方式的计算次数和序列长度有关系,100 个单词就需要 Victim Model 计算 100 次。A2T 使用了 Gradient-based 的方式计算重要性:\(I(x_i) = || \nabla_{e_i} \bold{L}(\theta, x, y) ||_1\),只需要 Victim Model 计算一次就可以计算出相对于嵌入层的梯度,将梯度的 “1-范数” 作为重要性,也就是向量所有元素绝对值之和。
(2)使用资源占用低、计算速度更快的 DistilBERT 作为 sentence encoder,对句子相似度进行评估。

实验分析和结论
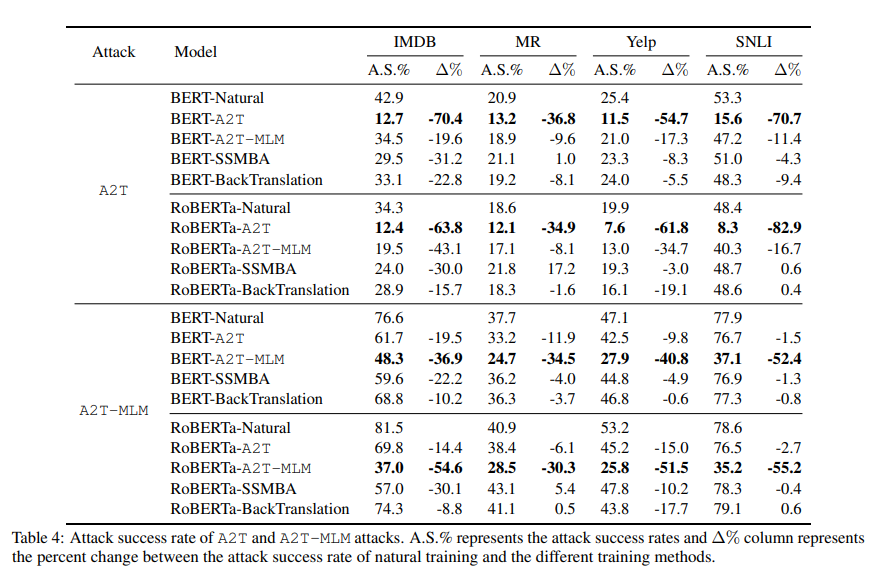
- 表格中的 A.S.% 表示攻击成功率;\(\Delta\)% 表示攻击成功率的降幅,比如 A2T 攻击 BERT-Natural 成功率是 42.9%,而攻击 BERT-A2T 成功率是 12.7%,那么降幅就是 \(1 - 0.429 / 0.127 = 0.704\)。结果表明,A2T 对抗训练可以更好抵抗 A2T 的攻击,A2T-MLM 对抗训练可以更好抵抗 A2T-MLM 的攻击。
- SSMBA 和回译法(backtranslation)可以帮助提高模型鲁棒性,对于较小的数据集数据增强对鲁棒性有损。
- 对比 A2T 对抗训练和 A2T-MLM 对抗训练,A2T 比 A2T-MLM 在原始精度(original accuracy)和跨领域精度(cross-domain accuracy)更好。这表明了 counter-fitted 词向量的方式比 MLM 生成更加高质量的对抗样本。MLM 会生成更加符合概率、语法的词语,但是可能改变了句子的语义,容易导致生成样本的真实语义和原始标签对应不上。
- 对比 BERT 和 RoBERTa 模型,BERT 比 RoBERTa 更容易受到 A2T 攻击,而 RoBERTa 比 BERT 更容易受到 A2T-MLM 的攻击(BERT 攻击成功率是 76.6%,RoBERTa 攻击成功率是 81.5%)。RoBERTa 比 BERT 更容易受攻击的原因是,RoBERTa 的泛化性能更好,因此对于生成样本的真实语义和原始标签对不上的情况,RoBERTa 会更好预测出来真实语义对应的标签,而这却被视为预测错误。
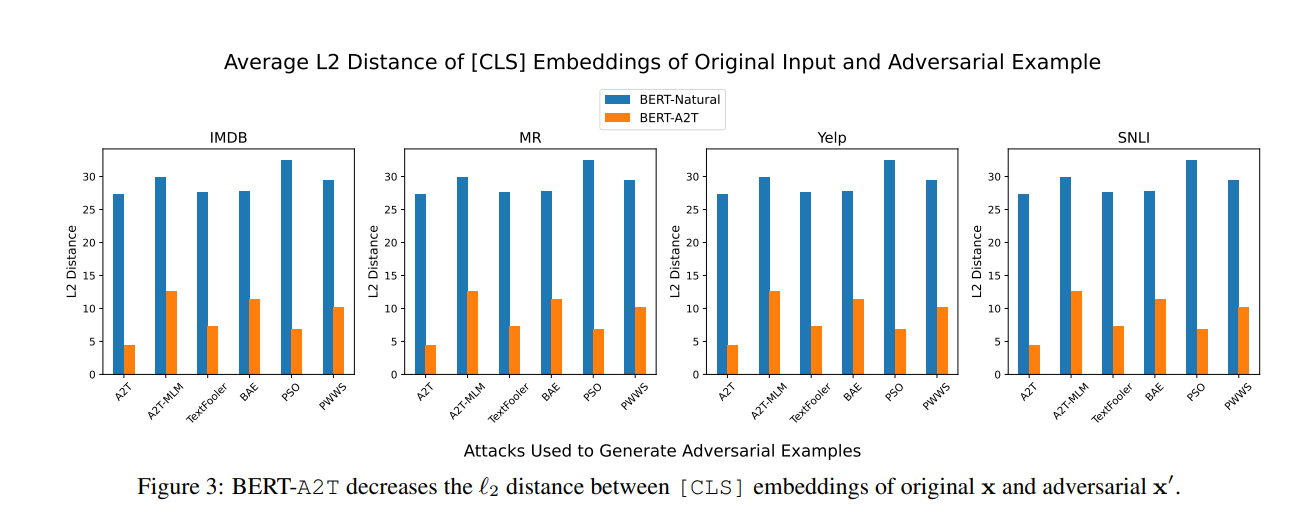
原始样本和对抗样本 [CLS] Embedding 的距离
经过对抗训练之后,[CLS] 之间的距离将减少,说明对抗训练可以使到原始样本和对抗样本的分类距离变近。
攻击成功率对比
文献中没有对比攻击成功率,通过文章中的 Table 4 和 Table 5 可以看到攻击成功率,下面简单摘出 IMDB 数据集上的攻击成功率。显然,这篇文章提出的方法在攻击成功率上是没有优势的,但是它的速度相比而言是要更快的。
| 攻击方法 | 模型 | 攻击成功率 |
|---|---|---|
| A2T | BERT-Natural/RoBERTa-Natural | 42.9%/34.3% |
| A2T-MLM | BERT-Natural/RoBERTa-Naturall | 76.6%/81.5% |
| TextFooler | BERT-Natural/RoBERTa-Natural | 85.0%/95.2% |
| BAE | BERT-Natural/RoBERTa-Natural | 60.5%/65.5% |
| PWWS | BERT-Natural/RoBERTa-Natural | 87.5%/96.6% |
| PSO | BERT-Natural/RoBERTa-Natural | 43.8%/34.8% |
DeepWordBug
标题:Black-box Generation of Adversarial Text Sequences to Evade Deep Learning Classifiers
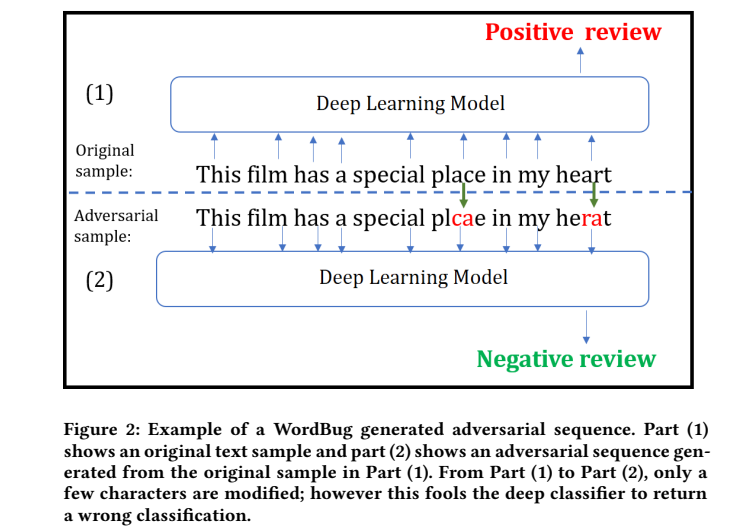
DeepWordBug 遵循着常见的文本对抗攻击套路,先对单词的重要性进行排序,然后对单词做扰动。DeepWordBug 对单词间的字符进行扰动,通过对单词的字符替换、删除、插入、交换,达到文本攻击的目的。
重要性排序
本文提出了四种重要性排序函数。
- Replace-1 Score(R1S):将 \(x_i\) 替换成 “unknown” 前后的预测概率差值。
- Temporal Head Score(THS):第一个单词到当前单词的序列的预测概率,第一个单词到前一个单词的序列的预测概率,两者的差值
- Temporal Tail Score(TTS):当前单词到最后一个单词的序列的预测概率,后一个单词到最后一个单词的序列的预测概率,两者的差值
- Combined Score(CS):THS 和 TTS 的加权平均。
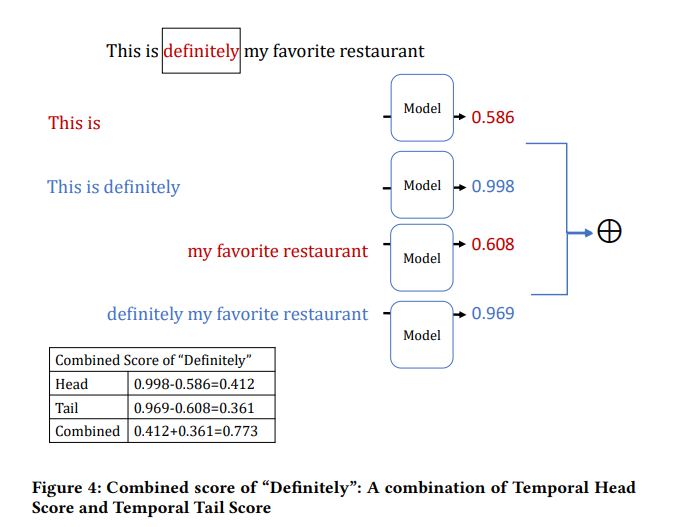
单词变换
本文提出了使用交换、替换、删除、插入字符四种攻击方式,单词将会拼写错误,转为模型不认识的词语,即发生了 “out-of-vocabulary”。人仍然可以理解包含有少量拼写错误的句子,通过对攻击添加 “编辑距离” 约束,可以限制句子单词的修改次数。
实验结果
实验部分攻击的模型是 Word-LSTM 和 Char-CNN,一个是对单词级别建模,一个是对字符级别建模。实验部分主要对比不同的重要性评估函数,使用了 Random 和 Gradient 两种。
编辑距离的影响: 编辑的越多,准确率就下降越多。
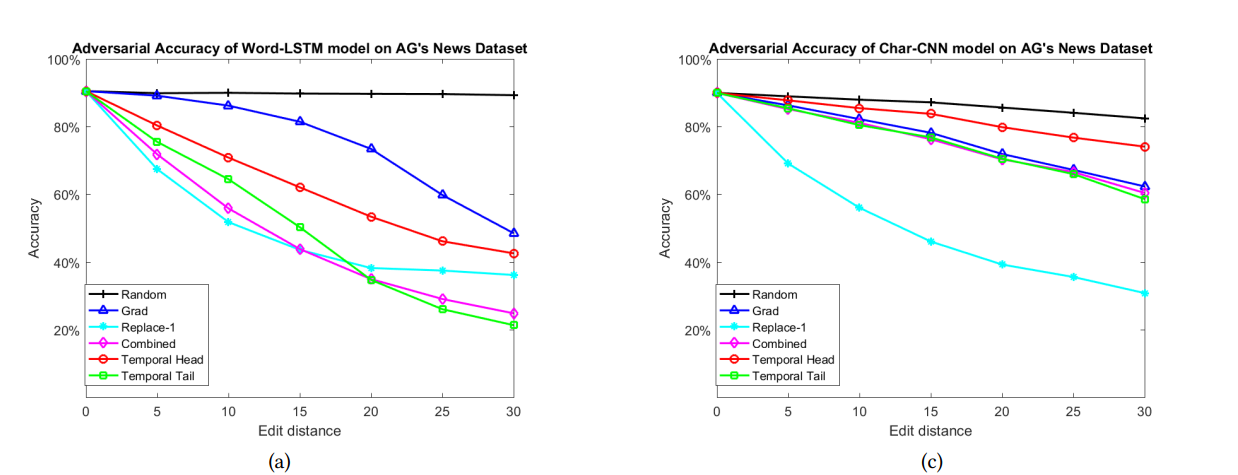
重要性函数的选择: 从下图可以看到,Replace 的性能是好且相对稳定的,随机攻击的方式最差,基于梯度的攻击效果并不显著。
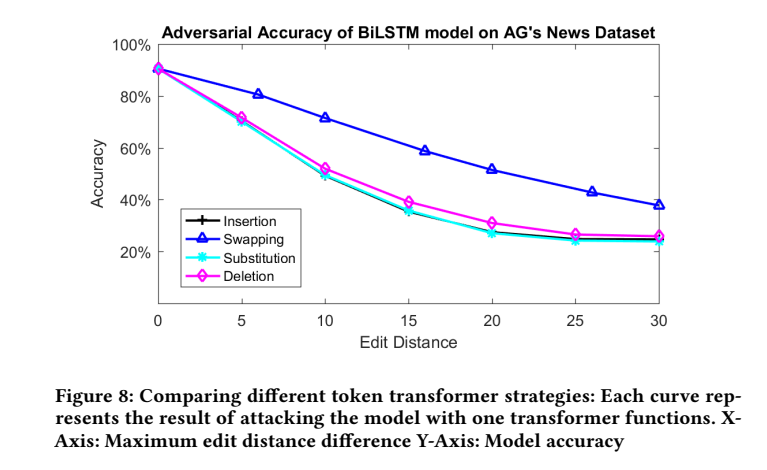
攻击方式: 本文使用 Word-LSTM 在 AG's News 数据集上,评估仅使用一种攻击方式的准确率影响,交换(swap)比其他三种要差一些,可能是因为其他方式一次只改动了一个字符,而 swap 改动了两个,而改动的数量会受到 “编辑距离” 的约束。另外不管是哪种方式,只要发生了改动,很大概率只是将单词变成了一个 “unknown”。
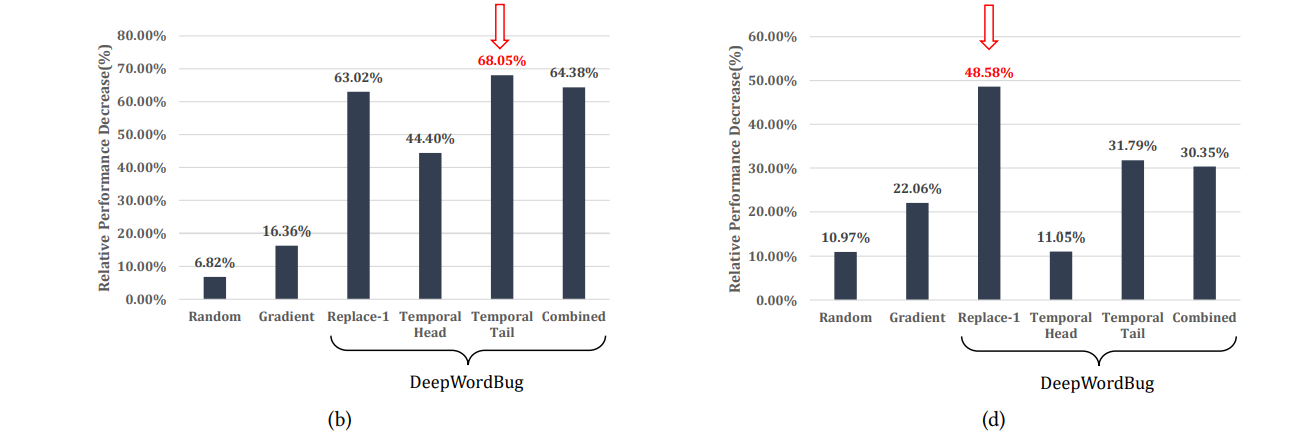
可转移性: 将一个模型生成的对抗样本输入到另一个模型进行攻击,可以看到这些对抗样本是可以转移的,可能是因为单词的重要性是固有的,不会因为换了一个模型就不重要了,所以将一个重要单词替换成 “unknown”,同样也可以攻击其他模型。
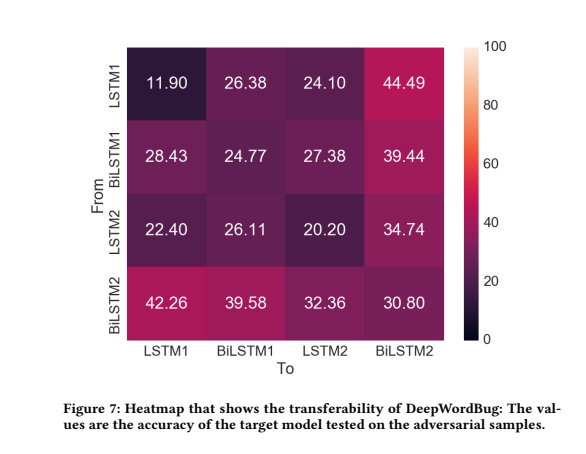
总结和思考
- 重要性评估的部分,如果使用的是黑盒攻击,那么是不是不能拿到预测的概率呢?应该只能拿到预测的标签吧。
- 攻击可能不需要四种方式,只需要将单词换成 unknown 即可,比如在 BERT 里面直接换成
[UNK]岂不是更好?
PWWS
标题:Generating Natural Language Adversarial Examples through Probability Weighted Word Saliency
执行流程
PWWS 算是比较早期探索文本对抗攻击的工作,所以回过头来看,这个工作似乎看上去比较简单。基本上和前文说的 TextFooler 等工作方法一致,计算重要性(2、10、11 行)、选择同义词进行替换(3 行)、不断替换直到攻击成功或者词语用完(12 ~ 16 行)。

重要性
单词替换选择近义词集合中,可以使到概率下降最大的一个。
PWWS 定义单词的显著性(saliency)如下公式:
其中 \(\bold{x}\) 表示原始序列,\(\bold{\hat{x}_i}\) 表示将第 \(i\) 个单词替换成 “unknown”。
最后评分函数定义为如下公式,\(\phi\) 函数是 softmax 函数,经过 softmax 函数可以算出每个单词的相对显著性,\(\phi(S(x))_i\) 表示计算了 softmax 之后,第 \(i\) 个分量的值。最后将评分定义为显著性和概率差值的乘积。
TextAttack-Search-Benchmark
摘要
前面我们已经看到多种文本攻击方法的基本流程,重要性计算、近义词搜索和过滤、不断替换直到成功,因此可以认为这个基本流程是对攻击文本求解空间的搜索问题。这篇文章分析了对抗文本生成过程的几个要素:搜索算法(search algorithm)、搜索空间(search space)、搜索代价(search budget)。这篇文章尝试解决的问题如下:
- 过往提出一个新的攻击算法的时候,搜索方法和搜索空间都有所改变,没有经过消融实验是难以知道攻击成功率上升的真实原因。
- 过往的研究没有合理考虑 “攻击耗时” 这个因素,然而下游任务(对抗训练)往往需要快速生成对抗样本。
为了解决以上问题,本文提供了一个可复现的对抗文本攻击 benchmark,这篇文章的贡献如下:
- 有时间约束或攻击长序列的时,建议使用贪心算法和单词重要性排序;其他情况,使用束搜索(beam search)和粒子群算法(particle swarm optimization),攻击成功率相对高。
- PWWS 和基因算法的性能相比贪心算法,攻击率低且耗时。
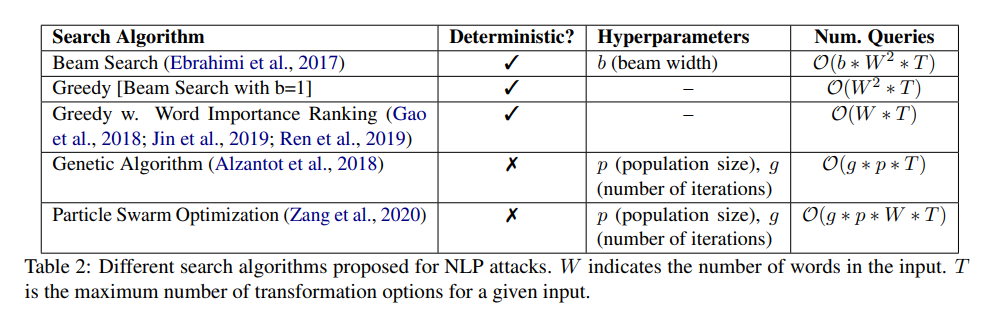
搜索算法
这篇文章用的搜索算法如下。
(1)Beam Search:每次扰动之后保存 top-b,下一次扰动对这 top-b 个样本进行操作
(2)Beam Search(b=1):每次扰动之后,只保留最好的一个样本
(3)Greedy With WIR:开始的时候计算一次单词重要性(UNK、DEL、PWWS、Gradient),后面都一直用这个重要性(替换了单词之后,重要性应该会动态改变,这种做法的好处就是速度快)
(4)Genetic Algorithm:每个迭代过程对群体进行扰动,群体中每个句子选择一个单词进行扰动,保留最好的部分,进行杂交;预测概率降的多的为更优秀的群体,杂交过程尽可能更优秀的群体。
(5)Particle Swarm Optimization:每个迭代过程对群体进行扰动,群体中每个句子对每个单词进行扰动,并采样出一个句子;杂交的时候,和这次迭代最好的杂交,也和历史最好的杂交。
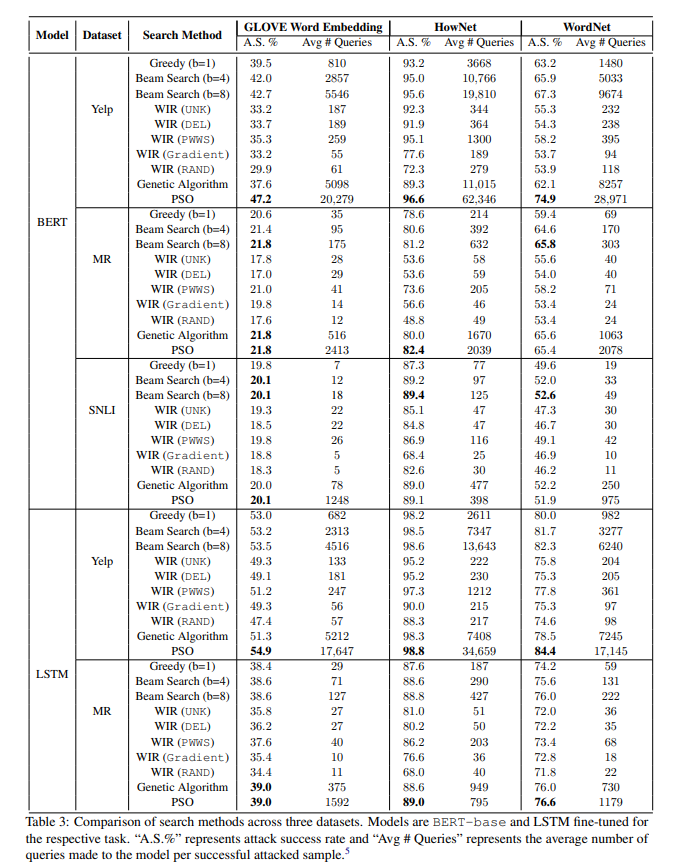
实验结果和分析
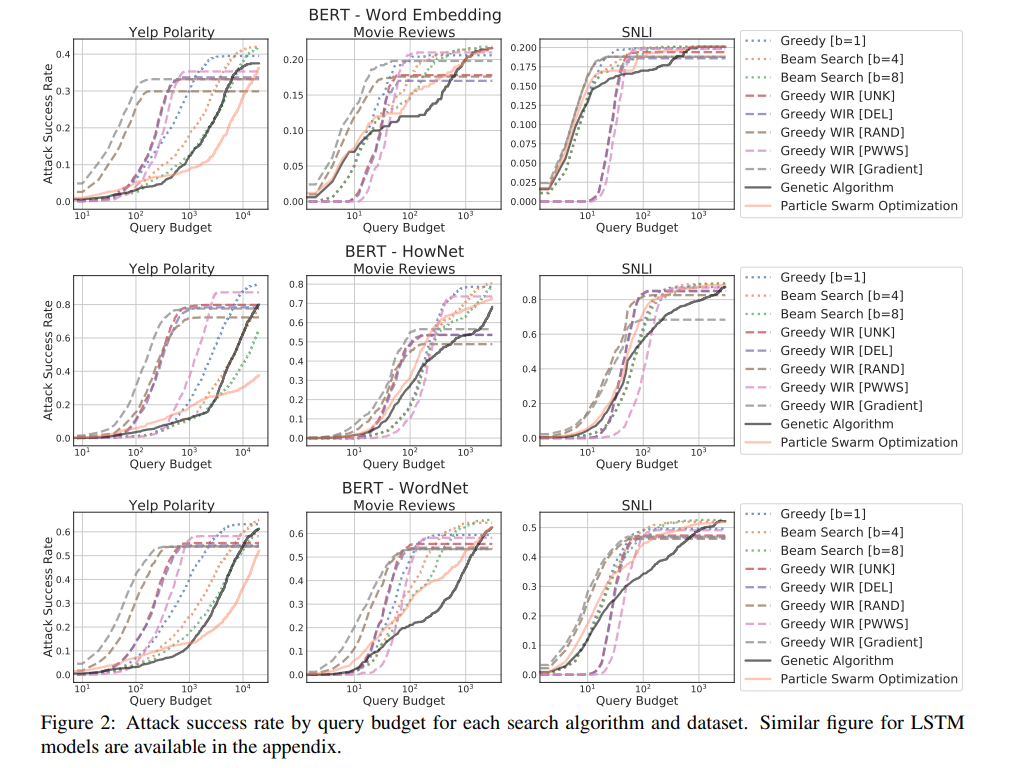
攻击率比较
Beam search(b=8)和 PSO 的攻击率最好,但是 PSO 的平均查询数量币 Beam Search 高了几倍,而攻击成功率仅高了一点。
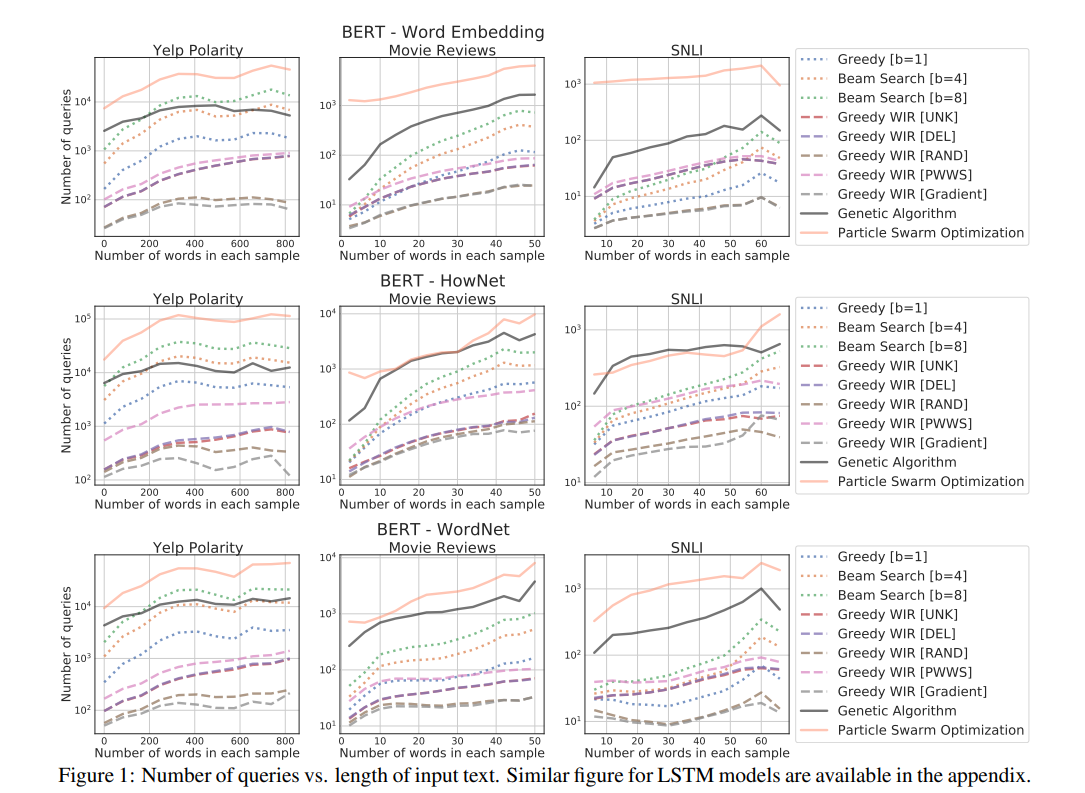
运行时间分析
查看上图中的平均查询数量,对搜索算法的性能可以有个大概的了解,比如 PSO 最多,WIR(Gradient)最少,下图同样可以看到这个趋势。
限定查询次数的性能
如下图,在限定查询次数较少的情况下,WIR 等方法相对会好一些;而查询次数很多或者不做限制的情况下,复杂的搜索算法(PSO 等)性能会更好。WIR 的方法中,Gradient 性能最好。PWWS 比较尴尬,攻击成功率和效率都不够优秀。
结论
如果运行时间不考虑在内的话,束算法和粒子群算法最好;如果运行时间要考虑在内的话,贪心算法加单词重要性会更好。(看图表感觉 Gradient 效果还不错的样子;)
SSDA/DPCA
算法核心
本文基于分类边界理论提出了一种改进对抗文本攻击的流程,文本攻击前进行预处理:加入弱化副词、减少强化副词。
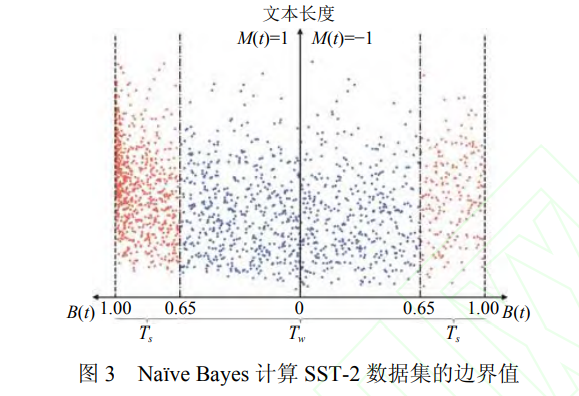
分类边界理论
如下图,正中间的线表示分类边界,左边是正类,右边是负类,中心线将整个数据集划分成两份。红点的部分比蓝点的部分距离中心线更远,如果分别对红点和蓝点进行对抗攻击,那么处在中心线旁边的蓝点将更容易受到对抗攻击,于是红点的攻击成功率要低于蓝点的攻击成功率。
副词
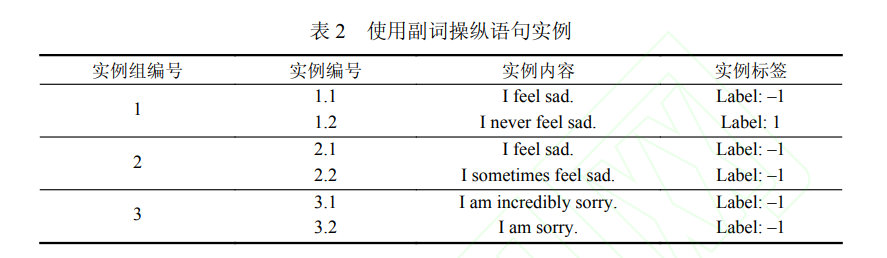
基于分类边界理论,本文提出的算法对数据集进行预处理,使之靠近分类边界而又不超过边界。文中写道:“利用副词操作语句的思想来源于自然语言规律: 副词在语句中大部分时候起强调作用, 而非决定语句含义. 副词能够操纵语句使其远离或迫近分类边界, 又很少直接逾越边界, 因此是实现语句稀释的重要工具.”
如表 2 可见,第一个例子将句子的标签逆转了;第二对句子的语义进行了弱化;第三个句子对句子进行了强化。因此,并非所有的副词是可以随便加的,需要根据情况进行增减。
增稀释池/删稀释池
增稀释池(pfA)中的词语是弱化副词,增加到语句中;删稀释池(pfD)中的词语是强化副词,从语句中剔除。
DPCA 算法:一种构建稀释池的方法,给出种子词语构成初始队列,从队列中取出词语加入到结果集,从 HowNet 中取出不在结果集的同义词加入到队列中,重复过程,直到队列为空。
SSDA 算法:第一,判断每个单词是否强化副词,尝试删除,检查是否更加靠近分类边界但又不越过分类边界。第二,判断每个单词是否形容词,尝试插入弱化副词,从中选出距离分类边界最近的副词。
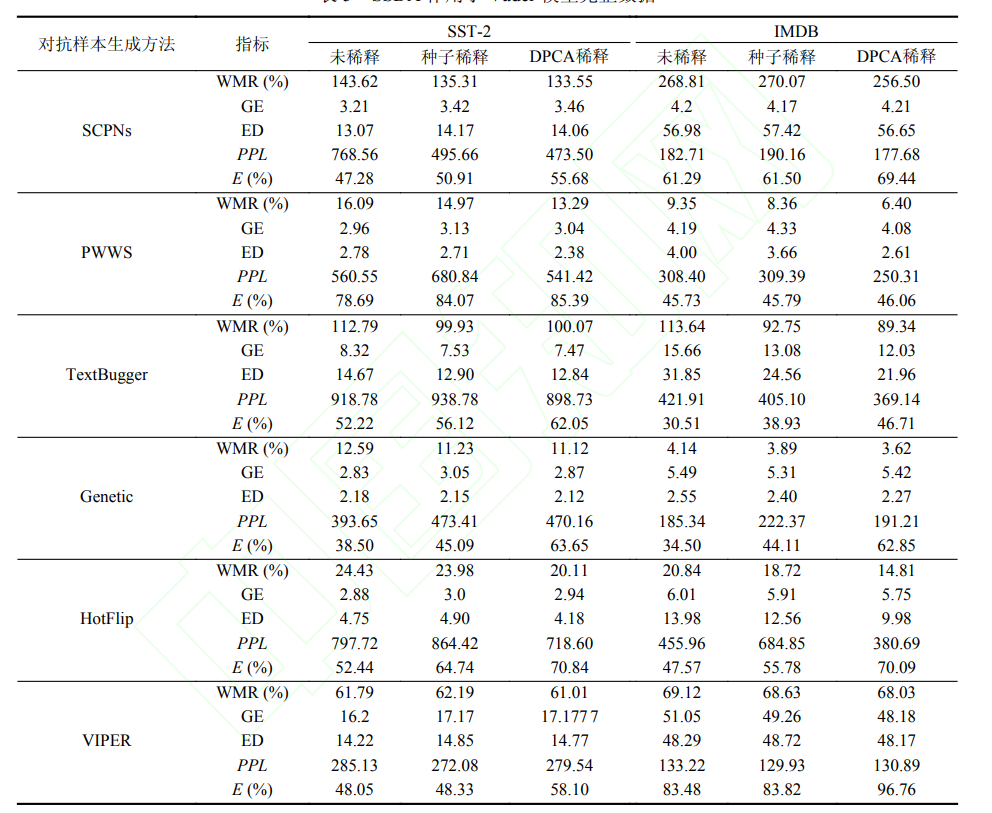
实验结果
本文所提的方法生成的样本更加高质量且使到攻击成功率提升。个人认为作者基于分类边界理论,结合语言学的知识,提出的算法是直观的,从实验也可以看到效果比较显著(虽然这看上去就是一个预处理流程)。不过对实验部分的结果存疑:作者是否有将预处理的修改统计到总的修改次数当中呢?
参考链接
[1] 文本生成评价指标:https://zhuanlan.zhihu.com/p/144182853

 浙公网安备 33010602011771号
浙公网安备 33010602011771号