PET 模型和代码分析
标题:Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
标题当中的 cloze 一词,根据 Merriam-Webster 上的翻译,大致可以理解为一项阅读理解测试,总结文本。因此,这个标题的意思是,使用 cloze 测试问题进行小样本文本分类和自然语言推理。
摘要
这篇文章提出了 Pattern Exploiting Training,一种半监督训练技术,将输入组织成 cloze 方式的句子,利用预训练语言模型本身的能力解决问题。对于无标注的数据,将获得一个软标签,之后使用标准的监督学习方式,学习这些数据。在小样本的情况下,PET/iPET 可以获得比监督学习更好的效果。
模型
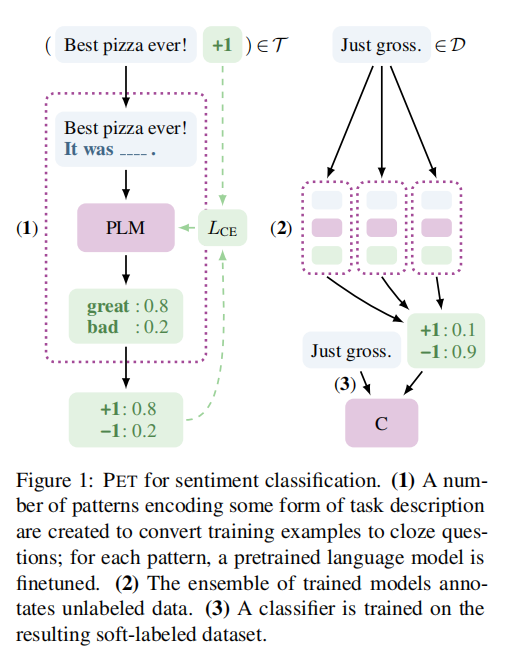
PET
PET 模型分为三个组成部分。
- (1) 是一个 pattern 对应的分类器,利用语言模型 PLM 本身的能力进行分类
- (2) 训练多个 pattern 分类器,输出无监督数据的软标签(logits)
- (3) 使用无监督数据训练最后的分类器。
原始数据(Best pizza ever!)和一个模板(It was <mask>.) 构成一个新的句子,使用预训练语言模型(PLM)预测 mask 的输出结果,这个结果是一个词表长度大小的向量,从这些向量中选出 n 个 label 对应的分类,计算 softmax 和 argmax,得到分类,计算损失。
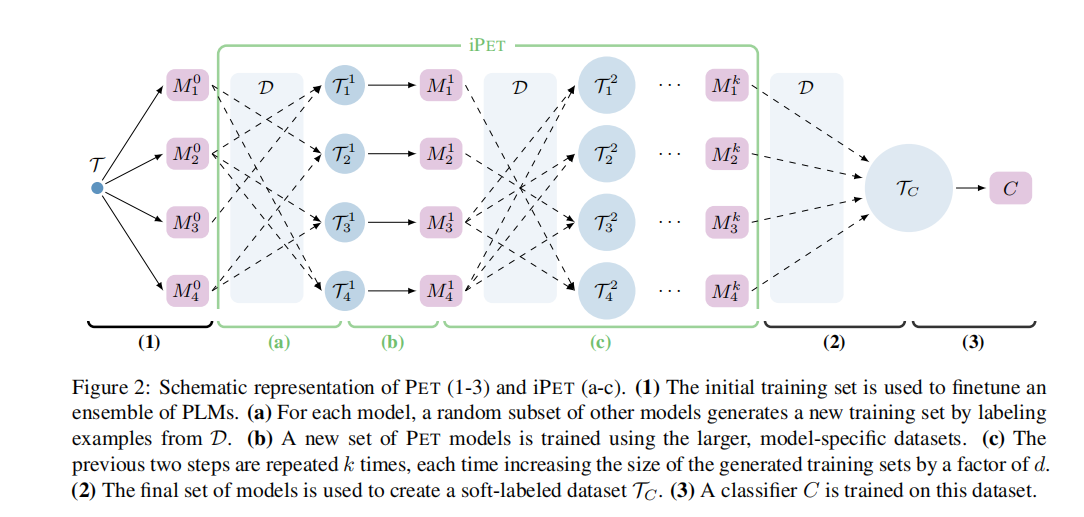
iPET
iPET 在 PET 的基础上,迭代训练模型。一轮一轮进行训练,每一轮训练出来之后,对下一轮的训练集进行扩充。扩充的方法是,选择上一轮中的部分模型的输出结果,对这些模型输出的 logits 加权求和,softmax,argmax 得到标签,从而扩充了数据。每一轮扩充数据的时候,按倍数放大数据量。
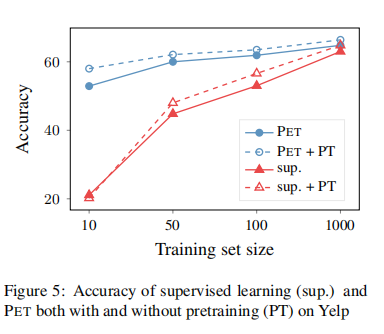
继续预训练
毕竟 PET/iPET 是半监督学习,充分利用了未标注数据,而监督学习没有用,这样比较模型的性能是否存在不公平呢?为此作者还进行了实验,先让模型在语料上进一步微调,然后再进行进一步的实验。结果表明,继续预训练对于监督学习、PET 都有提高,不过 PET 的性能还是要比监督学习好。
代码分析
PET 模型
整体流程分为三步:
- 第一步,训练多个 pattern 对应的模型
- 第二步,合并每个模型输出的无标注数据的 logits
- 第三步,训练最后的分类器。
# Step 1: Train an ensemble of models corresponding to individual patterns
train_pet_ensemble(ensemble_model_config, ensemble_train_config, ensemble_eval_config, pattern_ids, output_dir,
repetitions=ensemble_repetitions, train_data=train_data, unlabeled_data=unlabeled_data,
eval_data=eval_data, do_train=do_train, do_eval=do_eval,
save_unlabeled_logits=not no_distillation, seed=seed)
if no_distillation:
return
# Step 2: Merge the annotations created by each individual model
logits_file = os.path.join(output_dir, 'unlabeled_logits.txt')
merge_logits(output_dir, logits_file, reduction)
logits = LogitsList.load(logits_file).logits
assert len(logits) == len(unlabeled_data)
logger.info("Got {} logits from file {}".format(len(logits), logits_file))
for example, example_logits in zip(unlabeled_data, logits):
example.logits = example_logits
# Step 3: Train the final sequence classifier model
final_model_config.wrapper_type = SEQUENCE_CLASSIFIER_WRAPPER
final_train_config.use_logits = True
train_classifier(final_model_config, final_train_config, final_eval_config, os.path.join(output_dir, 'final'),
repetitions=final_repetitions, train_data=train_data, unlabeled_data=unlabeled_data,
eval_data=eval_data, do_train=do_train, do_eval=do_eval, seed=seed)
第一步
训练一个 pattern 对应的模型,给无监督数据数据打 logits。
每个 train step 外部的主要逻辑是将数据组装起来,一个 batch 包含一组有监督数据和一组无监督数据。每个 train step 中损失的计算,有监督数据计算 CrossEntropy,无监督数据计算 MLM loss,最后两个 loss 加权求和。
inputs = self.generate_default_inputs(labeled_batch)
mlm_labels, labels = labeled_batch['mlm_labels'], labeled_batch['labels']
outputs = self.model(**inputs)
prediction_scores = self.preprocessor.pvp.convert_mlm_logits_to_cls_logits(mlm_labels, outputs[0])
loss = nn.CrossEntropyLoss()(prediction_scores.view(-1, len(self.config.label_list)), labels.view(-1))
if lm_training:
lm_inputs = self.generate_default_inputs(unlabeled_batch)
lm_inputs['labels'] = unlabeled_batch['mlm_labels']
lm_loss = self.model(**lm_inputs)[0]
loss = alpha * loss + (1 - alpha) * lm_loss
return loss
第二步
合并无监督数据的 logits,将第一步每个模型输出的 logits 加权合并起来。
def merge_logits_lists(logits_lists: List[LogitsList], reduction: str = 'mean') -> LogitsList:
assert len(set(len(ll.logits) for ll in logits_lists)) == 1
logits = np.array([ll.logits for ll in logits_lists])
weights = np.array([ll.score for ll in logits_lists])
if reduction == 'mean':
logits = np.mean(logits, axis=0).tolist()
elif reduction == 'wmean':
logits = np.average(logits, axis=0, weights=weights).tolist()
else:
raise ValueError("Reduction strategy '{}' not implemented".format(reduction))
return LogitsList(score=-1, logits=logits)
第三步
训练最终的分类器,使用无监督数据的 logits 进行训练,损失函数使用模型蒸馏用的 loss。
def sequence_classifier_train_step(self, batch: Dict[str, torch.Tensor], use_logits: bool = False,
temperature: float = 1, **_) -> torch.Tensor:
inputs = self.generate_default_inputs(batch)
if not use_logits:
inputs['labels'] = batch['labels']
outputs = self.model(**inputs)
if use_logits:
logits_predicted, logits_target = outputs[0], batch['logits']
return distillation_loss(logits_predicted, logits_target, temperature)
else:
return outputs[0]
蒸馏用的 loss,计算 kl 散度。
def distillation_loss(predictions, targets, temperature):
"""Compute the distillation loss (KL divergence between predictions and targets) as described in the PET paper"""
p = F.log_softmax(predictions / temperature, dim=1)
q = F.softmax(targets / temperature, dim=1)
return F.kl_div(p, q, reduction='sum') * (temperature ** 2) / predictions.shape[0]
细节分析
将 mlm logits 转为 cls logits
在 prompt 里面的 mask 输出的 logits 转成 label 对应的 logits。首先 mask 输出的是一个 50265 维度(词表大小)的词向量,然后从这个向量选出标签下标对应的分量。
def convert_mlm_logits_to_cls_logits(self, mlm_labels: torch.Tensor, logits: torch.Tensor) -> torch.Tensor:
masked_logits = logits[mlm_labels >= 0]
cls_logits = torch.stack([self._convert_single_mlm_logits_to_cls_logits(ml) for ml in masked_logits])
return cls_logits
def _convert_single_mlm_logits_to_cls_logits(self, logits: torch.Tensor) -> torch.Tensor:
# m2c 是 verbalizer 对应的二维向量,每个点的默认值为 -1。
# 第 (i, j) 个元素表示第 i 个类别对应的第 j 个 label,它的值为 tokenizer 对 label 分词得到的 id。
m2c = self.mlm_logits_to_cls_logits_tensor.to(logits.device)
# filler_len.shape() == max_fillers
# filler_len 是为了处理 verbalizer 可能存在一个种类对应多个标签的情况。
filler_len = torch.tensor([len(self.verbalize(label)) for label in self.wrapper.config.label_list],
dtype=torch.float)
filler_len = filler_len.to(logits.device)
# cls_logits.shape() == num_labels x max_fillers (and 0 when there are not as many fillers).
# 因为默认值是 -1,因此需要用 torch.max 过滤掉没有意义的点
# 接着选出 verbalizer 对应的类别
cls_logits = logits[torch.max(torch.zeros_like(m2c), m2c)]
cls_logits = cls_logits * (m2c > 0).float()
# cls_logits.shape() == num_labels
cls_logits = cls_logits.sum(axis=1) / filler_len
return cls_logits
关于 m2c 的更多解释:
# yahoo 的 verbalizer 定义了如下的映射
VERBALIZER = {
"1": [" Society"],
"2": [" Science"],
"3": [" Health"],
"4": [" Education"],
"5": [" Computer"],
"6": [" Sports"],
"7": [" Business"],
"8": [" Entertainment"],
"9": [" Relationship"],
"10": [" Politics"],
}
# m2c 可能会长成下面这个样子
# [[(" Society" 在词表中对应的位置 id)],
# [(" Science" 在词表中对应的位置 id)],
# ...
# [(" Politics" 在词表中对应的位置 id)]]
# 于是我们就可以用以下这行代码选出需要的类别 logits
cls_logits = logits[torch.max(torch.zeros_like(m2c), m2c)]
mlm 是如何进行数据准备的?
MLM 只处理 15% 的数据,并且要去掉 special tokens;在这 15% 的数据当中,80% 使用 MASK 进行遮挡,10% 替换成随机字符,10% 保持不变。RobertaForMaskedLM 接受两个输入,一个是带有 mask 处理的 input_ids,一个是真实的 labels,然后输出的第一值是 MLM loss。
def _mask_tokens(self, input_ids):
""" Prepare masked tokens inputs/labels for masked language modeling: 80% MASK, 10% random, 10% original. """
labels = input_ids.clone()
# We sample a few tokens in each sequence for masked-LM training (with probability 0.15)
probability_matrix = torch.full(labels.shape, 0.15)
special_tokens_mask = [self.tokenizer.get_special_tokens_mask(val, already_has_special_tokens=True) for val in
labels.tolist()]
probability_matrix.masked_fill_(torch.tensor(special_tokens_mask, dtype=torch.bool), value=0.0)
masked_indices = torch.bernoulli(probability_matrix).bool()
# if a version of transformers < 2.4.0 is used, -1 is the expected value for indices to ignore
if [int(v) for v in transformers_version.split('.')][:3] >= [2, 4, 0]:
ignore_value = -100
else:
ignore_value = -1
labels[~masked_indices] = ignore_value # We only compute loss on masked tokens
# 80% of the time, we replace masked input tokens with tokenizer.mask_token ([MASK])
indices_replaced = torch.bernoulli(torch.full(labels.shape, 0.8)).bool() & masked_indices
input_ids[indices_replaced] = self.tokenizer.convert_tokens_to_ids(self.tokenizer.mask_token)
# 10% of the time, we replace masked input tokens with random word
indices_random = torch.bernoulli(torch.full(labels.shape, 0.5)).bool() & masked_indices & ~indices_replaced
random_words = torch.randint(len(self.tokenizer), labels.shape, dtype=torch.long)
input_ids[indices_random] = random_words[indices_random]
# The rest of the time (10% of the time) we keep the masked input tokens unchanged
return input_ids, labels
prompt 是如何进行数据准备的?数据怎么流动?
原始数据集 ->
生成数据集 ->
获取输入特征(input_ids, attention_mask, token_type_ids, mlm_labels 等) ->
-> BERT 编码
-> 截断到最大长度(设置原始文本为 shortenable,pattern 为 not shortenable)
输入到 BERT 中 ->
根据 pattern 的 mlm_labels 提取出 logits ->
计算 loss
iPET 模型
iPET 在 PET 的基础上,迭代训练 pattern 对应的模型。每次迭代训练的时候,会对训练集进行更新,使用无标注数据生成标签补充训练集数据。下一次迭代的时候,将会使用这些新的数据,再加上一开始的训练集。
数据集更新大致有如下流程:
- 更新大小,每次迭代更新数据量变大 5 倍。第一次的数据量是 40 个,第二次的数据量是 240 个,第三次的数据量是 1240 个。
- 选择新的数据,其他 pattern 模型保留 25%,对这些模型输出的 logits 进行加权求和,
- 使用 softmax 加上 argmax 生成标签,选出上述计算的样本容量大小,输出到文件里面。
在代码里面,假设有 6 个 pattern,p0, p1, .., p5。第一步是排除掉当前的 pattern,假设剩下 p1, p2, ..., p5。25% 的作用是用来挑选出 25% 的 pattern,向下取整,假设挑选出来的是 p2,然后使用挑选出来的 pattern 输出的 logits 进行加权求和(如果有多个),计算 softmax,然后挑选出补充集合大小的数量。
实验设置
论文作者在两篇文章的附录部分,附带了对实验具体配置的讨论。
超参数的设置
- batch size,原作者应该用的是 4,累积 4 个 steps 进行一次反向传播。(实验过程中用 4 个样本,且不累加梯度,效果也可以。RoBERTa-Base)
- maximum length,和 batch size 一起,刚好可以让模型塞满一张 1080 Ti 显卡。(代码中默认配置是 256,运行代码过程中可以观察到显存最高达到 11268 MiB)
- learning rate,1e-5。作者发现 5e-5 学习率对监督学习的效果不够稳定。
- 对于每个 PET 模型,training steps,250 steps。每个 PET 模型更新的 step 需要 4x4 个样本,1000 个样本需要跑 4 个 epochs,每个 epochs 运行 1000 / 16 = 62.5 个 steps。在数
据比较充裕的情况下,建议使用 2 ~ 10 个 epochs。每个 step 用一个有标签数组计算交叉熵,三个无标签数据计算 MLM 任务。对于 x-stance 这个任务,需要先运行 3 个 epochs 进行初始化。 - 对于最终的分类器,5000 steps。因此使用一共 20000 个无标注样本。
- 蒸馏使用的 Temperature,2。
- mlm 损失,作者观察到 mlm 损失比交叉熵损失大很多,因此要想办法混合两种损失,作者选用了几个超参数 [1e-3, 1e-4, 1e-5] 进行实验,使用 100 个例子,划分为训练集和验证集,然后找到最大的验证集准确率。
- 每个 pattern 重复训练 3 次,最终模型集成的时候都会用上。(实验过程中,一开始嫌慢,直接只训练一个,集成起来效果也不错)
- iPET 数据集大小,每个迭代 quintuple(五倍)数据量。
- iPET 数据集创建,每次使用其他模型输出的全部数据的 25% 来作为候选集,然后从候选集再挑出固定样本大小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号