我不会用 Triton 系列:上手指北
摘要
本篇文章介绍了如何上手使用 Triton,本文将使用 Pytorch 导出 Resnet50 模型,将其部署到 Triton。Resnet50 是一个预训练模型,我们可以直接使用它预训练时的任务,即图像分类。部署好了之后,会介绍如何使用 Python 客户端进行请求,客户端发送一张图片,Triton 返回分类的结果。之后我们会使用 Triton 提供的客户端工具 model_analyzer 来分析不同配置下的延迟和吞吐,暴力搜索出延迟最小的方案。
这篇文章剩下的部分,将会简单介绍如何使用 Triton 的其他特性,比如模型热更新的方法和规则。另外,还有一些 Triton 文档中没有写的小细节,这些东西可以通过 ModelConfig 的 protobuf 定义 看到,本文将会一一介绍。
代码:https://github.com/zzk0/triton/tree/master/quick
服务端部署
首先,我们需要一个模型,以 Resnet50 为例子。
Pytorch 导出模型
咱们先使用 Pytorch 导出 Resnet50 模型,Resnet50 是一个图片分类模型,模型的类别有 1000 类。使用 torchscript 保存模型。
保存模型的代码如下,非常的简单。这个模型可以接受的图片大小是可变的,不一定是 244, 244。
import torch
import torchvision.models as models
resnet50 = models.resnet50(pretrained=True)
resnet50.eval()
image = torch.randn(1, 3, 244, 244)
resnet50_traced = torch.jit.trace(resnet50, image)
resnet50(image)
resnet50_traced.save('model.pt')
使用 Triton 部署模型
现在我们已经有了模型文件了,接下来我们把它部署到 Triton 上面。
第一步,拉取 Triton 镜像
以 r21.10 版本为例子,运行下面的命令拉取镜像。
docker pull nvcr.io/nvidia/tritonserver:21.10-py3
第二步,配置模型
按照下面的方式组织文件目录结构。
quick/
└── resnet50_pytorch # 模型名字,需要和 config.txt 中的名字对上
├── 1 # 模型版本号
│ └── model.pt # 上面保存的模型
├── config.pbtxt # 模型配置文件
├── labels.txt # 可选,分类标签信息,注意格式
├── resnet_client.py # 客户端脚本,可以不放在这里
└── resnet_pytorch.py # 生成 model.pt 的脚本,可以不放在这里
下面给出模型的配置信息 config.pbtxt。模型的输入是,[ N, 3, -1, -1 ] 的图片,输出是 [ N, 1000 ] 维度的分类向量,还指定了分类的文件名,用于获取分类结果。
name: "resnet50_pytorch"
platform: "pytorch_libtorch"
max_batch_size: 128
input [
{
name: "INPUT__0"
data_type: TYPE_FP32
dims: [ 3, -1, -1 ]
}
]
output [
{
name: "OUTPUT__0"
data_type: TYPE_FP32
dims: [ 1000 ]
label_filename: "labels.txt"
}
]
第三步,启动服务
启动服务的方法有两种,一种是用 docker 启动并执行命令,一种是进入 docker 中然后手动调用命令。
第一种,docker 启动并执行命令:
docker run --gpus=all --rm -p8000:8000 -p8001:8001 -p8002:8002 -v/home/percent1/triton/triton/quick:/models nvcr.io/nvidia/tritonserver:21.10-py3 tritonserver --model-repository=/models
第二种,进入 docker,然后运行命令:
docker run --gpus=all --network=host --shm-size=2g -v/home/percent1/triton/triton/quick:/models -it nvcr.io/nvidia/tritonserver:21.10-py3 # 进入 docker
./bin/tritonserver --model-store=/models # 启动 triton
启动之后,我们可以看到以下输出,表明我们已经启动完成。
使用下面的命令,检查是否已经准备好了
root@oneflow-15:/workspace# curl -v localhost:8000/v2/health/ready
* Trying 127.0.0.1:8000...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8000 (#0)
> GET /v2/health/ready HTTP/1.1
> Host: localhost:8000
> User-Agent: curl/7.68.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Content-Length: 0
< Content-Type: text/plain
<
* Connection #0 to host localhost left intact
客户端请求
请求例子
客户端脚本如下,我们先读取一张图片的数据,然后转换成 [ N, 3, -1, -1 ] 的格式,之后发送请求做分类。因为在模型配置文件中,我们指定了标签信息的文件,所以我们可以在分类的时候指定是否获取分类结果。在 InferRequestedOutput 类中,我们可以指定 class_count 参数,设置数量,表示获取 topN 分类结果。
脚本有几个步骤组成:设置客户端,读取数据,设置一次请求的输入和输出,发起请求,获取结果,输出结果。
import numpy as np
import tritonclient.http as httpclient
import torch
from PIL import Image
if __name__ == '__main__':
triton_client = httpclient.InferenceServerClient(url='127.0.0.1:8000')
image = Image.open('./cat.jpg')
image = image.resize((224, 224), Image.ANTIALIAS)
image = np.asarray(image)
image = image / 255
image = np.expand_dims(image, axis=0)
image = np.transpose(image, axes=[0, 3, 1, 2])
image = image.astype(np.float32)
inputs = []
inputs.append(httpclient.InferInput('INPUT__0', image.shape, "FP32"))
inputs[0].set_data_from_numpy(image, binary_data=False)
outputs = []
# outputs.append(httpclient.InferRequestedOutput('OUTPUT__0', binary_data=False, class_count=3)) # class_count 表示 topN 分类
outputs.append(httpclient.InferRequestedOutput('OUTPUT__0', binary_data=False)) # 获取 1000 维的向量
results = triton_client.infer('resnet50_pytorch', inputs=inputs, outputs=outputs)
output_data0 = results.as_numpy('OUTPUT__0')
print(output_data0.shape)
print(output_data0)
以下是请求的结果,是一只猫 meow~

客户端接口实例
因为 Triton 没有提供相关的 API 文档,我们只好自己看代码了。
下面展示客户端的其他接口使用方法。
import tritonclient.http as httpclient
if __name__ == '__main__':
triton_client = httpclient.InferenceServerClient(url='127.0.0.1:8000')
model_repository_index = triton_client.get_model_repository_index()
server_meta = triton_client.get_server_metadata()
model_meta = triton_client.get_model_metadata('resnet50_pytorch')
model_config = triton_client.get_model_config('resnet50_pytorch')
statistics = triton_client.get_inference_statistics()
shm_status = triton_client.get_cuda_shared_memory_status()
sshm_status = triton_client.get_system_shared_memory_status()
server_live = triton_client.is_server_live()
server_ready = triton_client.is_server_ready()
model_ready = triton_client.is_model_ready('resnet50_pytorch')
# 启动命令: ./bin/tritonserver --model-store=/models --model-control-mode explicit --load-model resnet50_pytorch
# Triton 允许我们使用客户端去加载/卸载模型
triton_client.unload_model('resnet50_pytorch')
triton_client.load_model('resnet50_pytorch')
triton_client.close()
with httpclient.InferenceServerClient(url='127.0.0.1:8000'):
pass
性能测量和优化
这一节会介绍 Triton 提供的性能相关的客户端接口,客户端工具,仅仅是介绍作用,没有实操。下一节,我们将选择其中一个工具进行性能调优。
Triton 提供了两个接口,直接使用上面的 Python 客户端就可以获取到这些数据了。
Triton 到底提供了哪些客户端工具呢?熟练使用这些客户端工具可以帮助我们做好性能测量和优化。从软件演进的角度来看,下面的工具一个比一个更加自动化。
- perf_analyzer,可以测量吞吐延迟等。文档
- model_analyzer,利用 perf_analyzer 来进行性能分析,测量 GPU 内存和利用率。仓库
- model_navigator,自动化部署模型。仓库
Metrics
文档:https://github.com/triton-inference-server/server/blob/main/docs/metrics.md
Metrics 提供了四类数据:GPU 使用率;GPU 内存情况;请求次数统计,请求延迟数据。其中 GPU 使用情况是每个 GPU 每秒的情况,因此向 metrics 接口获取数据的时候,可以获取到当前秒 GPU 的使用情况。
statistics
文档:https://github.com/triton-inference-server/server/blob/main/docs/protocol/extension_statistics.md
Statistics 统计信息可以使用客户端工具获得,它记录了从 Triton 启动以来发生的所有活动。
性能测量工具 perf_analyzer
文档:https://github.com/triton-inference-server/server/blob/main/docs/perf_analyzer.md
这个工具藏在哪里了呢?文档也没告诉你。我是在另一个项目中,看见了别人是怎么用的才知道的。
模型分析工具 model_analyzer
英伟达的开发者专门写了一篇文章介绍这个工具:https://developer.nvidia.com/blog/maximizing-deep-learning-inference-performance-with-nvidia-model-analyzer/
model_analyzer 可以通过 pip 安装,输入 model-analyzer --help 我们可以看到如下输出。model_analyzer 实际上是由三个子命令 (subcommand) 组成的。
root@oneflow-15:/workspace# model-analyzer --help
usage: model-analyzer [-h] [-q] [-v] [-m {online,offline}] {profile,analyze,report} ...
positional arguments:
{profile,analyze,report}
Subcommands under Model Analyzer
profile Run model inference profiling based on specified CLI or config options.
analyze Collect and sort profiling results and generate data and summaries.
report Generate detailed reports for a single config
optional arguments:
-h, --help show this help message and exit
-q, --quiet Suppress all output except for error messages.
-v, --verbose Show detailed logs, messags and status.
-m {online,offline}, --mode {online,offline}
Choose a preset configuration mode.
模型自动化部署 model_navigator
仓库地址:https://github.com/triton-inference-server/model_navigator
官方的介绍称这是一个自动化工具。第一步,会将模型转换成可用的格式,并应用一些 Triton 后端优化。第二步,它使用 Triton Model Analyzer 来找到最好的模型配置,以提供性能。
性能测量
上一节我们介绍了有哪些客户端接口和工具帮助我们做性能测量,这一节我们将选择一个工具来实际测量一下模型的性能。NVIDIA 提供了三个工具,perf_analyzer, model_analyzer, model_nagivator。perf_analyzer 只能测量吞吐和延迟,model_analyzer 在这基础上还可以获得 GPU 内存和使用率。因此,这一节将采用 model_analyzer 来分析测量模型的性能。
安装
英伟达的文档中讲到了如何安装 model_analyzer: https://github.com/triton-inference-server/model_analyzer/blob/main/docs/install.md
不过其实有点小坑。文档中说你可以通过拉取 Docker,在 Docker 中使用 model_analyzer。你可以拉取到 tritonserver:21.10-py3-sdk 这个镜像,但是在这个镜像里面没有 tritonserver,而 model_analyzer 使用本地模式需要依赖 tritonserver,所以这种方式可以说你根本就没安装hhh
这里我们直接进入 docker 里面,使用 pip 进行安装,文档说要安装 DCGM,在 docker 里面早就装好了,别听他的。
nvidia-docker run --rm --runtime=nvidia --shm-size=2g --network=host -it --name triton-server -v `pwd`:/triton nvcr.io/nvidia/tritonserver:21.10-py3 bash
pip3 install triton-model-analyzer -i https://pypi.tuna.tsinghua.edu.cn/simple
测量
运行下面的命令,测量指定模型
model-analyzer profile --model-repository /triton/triton/quick/ --profile-models resnet50_pytorch
接下来就会遇到错误:
2021-11-17 13:58:54.831 INFO[perf_analyzer.py:258] Running perf_analyzer ['perf_analyzer', '-m', 'resnet50_pytorch_i5', '-b', '1', '-u', 'localhost:8001', '-i', 'grpc', '--concurrency-range', '1', '--measurement-mode', 'count_windows'] failed with exit status 1 : error: failed to create concurrency manager: input INPUT__0 contains dynamic shape, provide shapes to send along with the request
因为我们的模型使用了 dynamic shape,所以导致 triton 不知道应该发送怎么样的向量给 server。所以这里我们把 shape 从 [3, -1, -1] 改为 [3, 224, 224] 就好。model_analyzer 会设置 \(2^n\) 的并发度做性能测试,这个 concurrency 我猜测应该是线程数量。之后会不断提高模型实例的数量来测,直到 GPU 利用率或者显存满了。另外会分别再测试一组是否开启 dynamic batching 这个选项,之后还会测试 preferred batch size 大小。
输入上面的命令,重新启动测试。之后需要挺长时间的,先睡个觉吧。
测试好了之后,先输入下面的命令安装依赖。生成分析报告和详细报告。
wget https://github.com/wkhtmltopdf/packaging/releases/download/0.12.6-1/wkhtmltox_0.12.6-1.focal_amd64.deb
apt update
apt install ./wkhtmltox_0.12.6-1.focal_amd64.deb -f
mkdir analysis_results
model-analyzer analyze --analysis-models resnet50_pytorch -e analysis_results
model-analyzer report --report-model-configs resnet50_pytorch_i15,resnet50_pytorch_i30 -e analysis_results
model_analyzer 会尝试搜索两种不同的配置,一种是最小化延迟的 online mode,一种是最大化吞吐的 offline mode。默认情况下搜索延迟最小化的方案。
model_analyzer 相关链接
model_analyzer 通过暴力搜索选项来找到最好的配置,这些选项有些是 triton 自动配置的,一些是需要你手动配置才会搜索的。
更多的模型配置选项可以参考这个 模型配置搜索文档。
上面那个文档的缺点就是没有告诉你启动的时候,怎么才可以使用那些配置文件,所以你需要去翻一翻这个 CLI 文档
详细报告
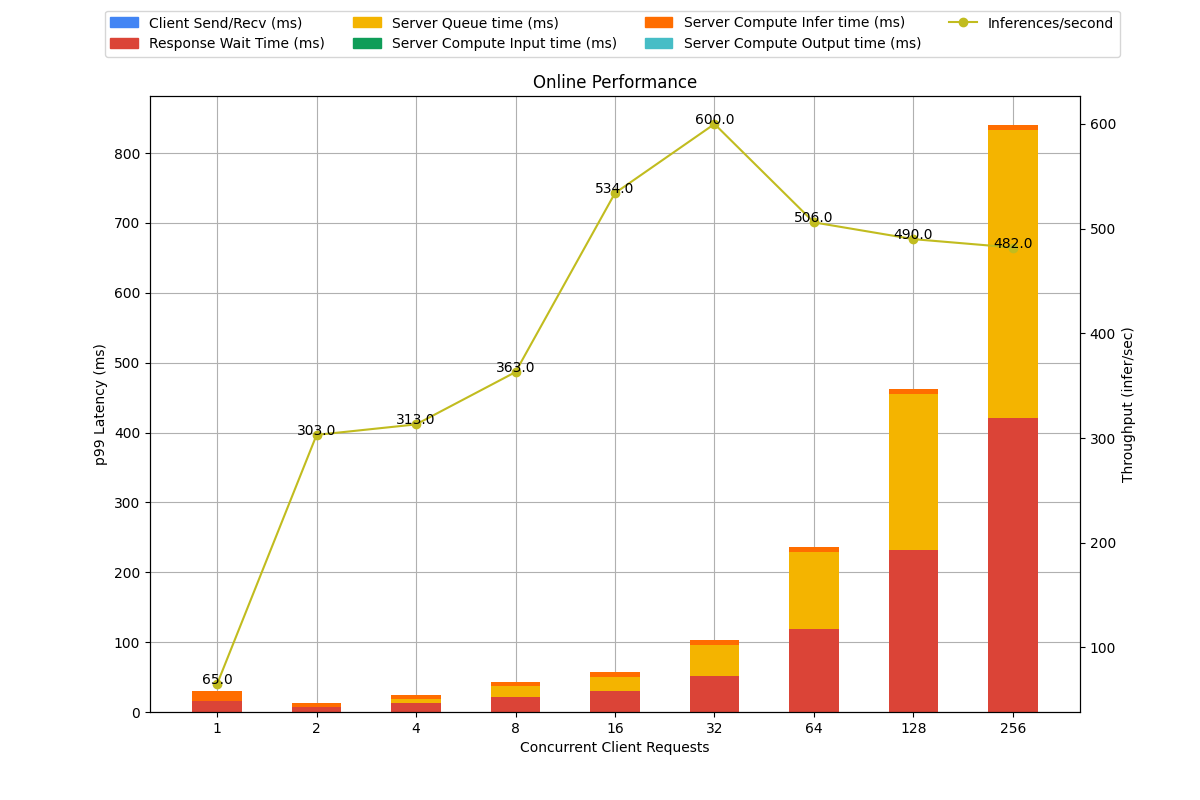
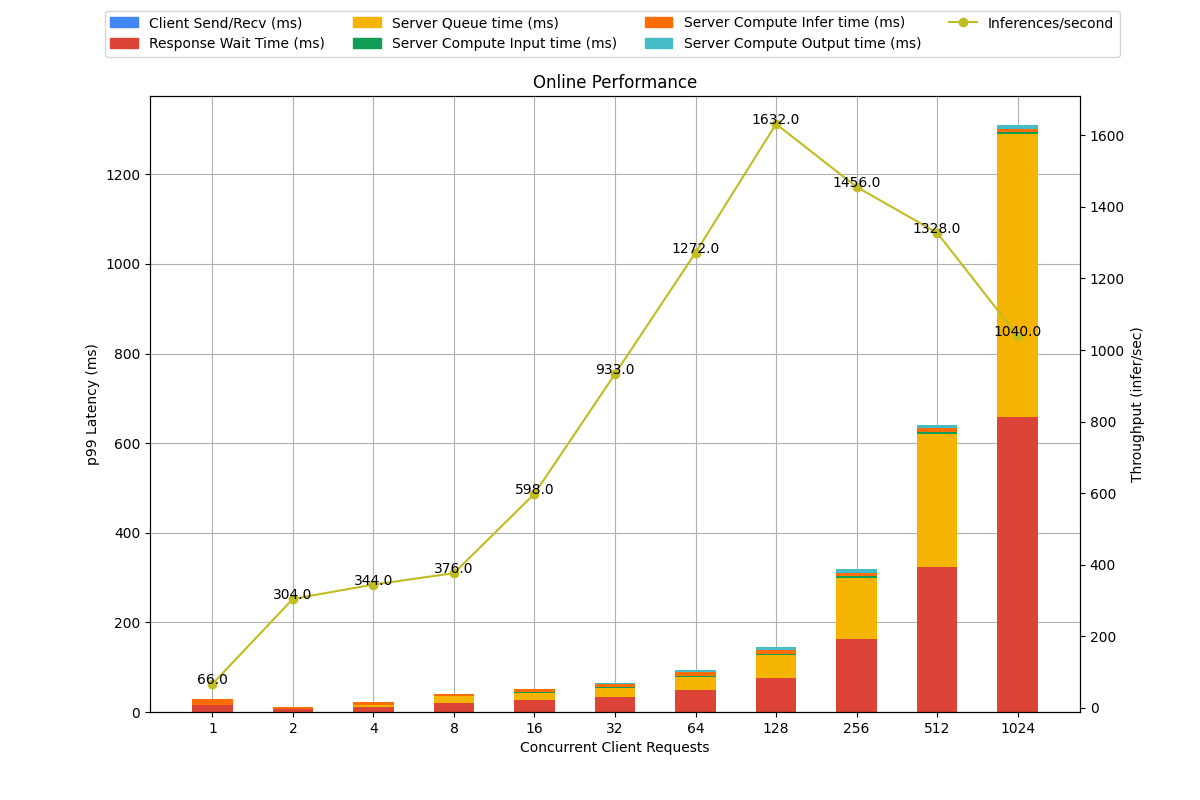
我们可以看看 online mode 下,最好的两个配置的详细报告。因为这是个多目标优化问题,所以究竟该选择怎么样的配置取决于业务场景的约束。triton 对这个的处理过于简单,比如 online mode 直接选择延迟最小的那个配置。实际上是因为这个问题和业务场景太相关,并且需要的配置项太多了,以至于只能简化处理。复杂的逻辑、业务相关的逻辑需要交给用户自己去做选择。
Server: Preferred Batch size 2, Instance Group 1/GPU
Server: Preferred Batch size 16, Instance Group 1/GPU
至此,基本的流程已经走完了。下面是其他相关东西的简介。
性能调优选项和指标
选项
上面 model_analyzer 在帮我们测量性能的时候,会尝试搜索不同配置下的性能。影响性能的选项有哪些呢?
- Instance Group,每个设备上使用多少个模型实例。模型实例占内存,但可以提高利用率
- Dynamic Batching,是否开启 batching。将请求积攒到一定数量后,再做推理。
- Preferred Batch Sizes,可以设置不同的数值,在一定的排队时间内,如果达到了其中一个数值,就马上做请求,而不用等待其他请求。
- Model Rate Limiter,约束模型的执行。
- Model Queue Policy,排队时间等待策略。
- Model Warmup,避免第一次启动的延迟。
- Model Response Cache,这是最近增加的特性,是否开启缓存。如果遇到了相同的请求,就会使用缓存。
指标
Serving 在不同的场景,需要不同的优化目标。目标是多个的,复杂的,并不是那么的单一。大家都想最小化延迟的同时,又要最大化吞吐。目标严重依赖于应用场景,因此只有确立目标,才可以往那个方向尽可能的优化。
- 延迟
- 吞吐
- GPU 利用率
- GPU 内存占用
- GPU 功耗
- 业务相关的指标:比如在尽可能少的设备上放尽可能多的模型
Triton 其他特性简介
模型热更新
在启动 tritonserver 的时候,带上选项 --model-control-mode=poll 就可以启动模型热更新了。另外还可以指定 --repository-poll-secs 设置轮询模型仓库的时间。
Agent
https://www.cnblogs.com/zzk0/p/15553394.html
Agent 扩展了 Triton 在加载卸载 “模型” 时候的功能。比如可以在加载模型的时候,进行 md5 校验。再比如对模型进行解密。
Rate Limiter
https://www.cnblogs.com/zzk0/p/15542015.html
从效果上来说,Rate Limiter 的作用是限制了请求分发到模型实例上。从实现上来说,Rate Limiter 引入了 “Resource” 的概念,表示一个模型实例需要的资源,当系统中存在足够的资源,这个模型就会执行。如果资源不够,那么一个请求需要等待其他模型实例释放资源。最终的表现就是好像限制了速度一样。
Model Warmup
https://www.cnblogs.com/zzk0/p/15538894.html
启动的时候进行一次前向传播,Warmup。避免来自客户端的第一次请求因为 Backend 启动造成的延迟。
很简单,在 config.pbtxt 中加入以下配置即可,不过模型的输入名字,输入的向量维度需要按照需要进行适当调整。
model_warmup [
{
name: "random_input"
batch_size: 1
inputs: {
key: "INPUT0"
value: {
data_type: TYPE_FP32
dims: [224, 224, 3]
random_data: true
}
}
}
]
Stateful Model
https://www.cnblogs.com/zzk0/p/15510825.html
Sequence Batching,将来自同一批的请求定向到同一个模型实例,以保证模型的状态可以持续更新。Python Backend 也支持 Stateful Model(ps. 第一次在 issue 里面尝试回答问题,帮助他人。结果翻车了hhh
Ensemble Model
https://www.cnblogs.com/zzk0/p/15517120.html
模型流水线(pipeline),将模型的输入输出串联起来。不过因为模型配置的方式太过于死板,不能支持灵活的数据格式、不能支持控制流,这种方式不能很好的支持业务需要,此时可以尝试使用 Python Backend。
perf_analyzer 的使用
具体使用参考文档:https://github.com/triton-inference-server/server/blob/main/docs/perf_analyzer.md
使用下面命令启动 Docker。
docker run --rm --runtime=nvidia --shm-size=2g --network=host -it --name triton-server-sdk -v `pwd`:/triton nvcr.io/nvidia/tritonserver:21.10-py3-sdk bash
性能测量:
perf_analyzer -m resnet50_pytorch --shape INPUT__0:3,224,224 # 数字之间不要有空格
perf_client # 就是 perf_analyzer
常用参数:
--percentile=95,一般置信度是和置信区间一起使用的,比如结果落在某个置信区间上的概率是 95% 这样子。这里的置信度应该是有别于 “置信区间的置信度” 的。它是用来测量延迟的,如果没有指定,会使用所有的请求算延迟的平均值,如果指定了,那么会使用 95% 的请求来计算。(至于是哪个 95% 文档没说,应该是去掉高的和低的,中间的 95%)--concurrency-range 1:4,concurrency 表示并行度,每次请求需要等待服务器响应才会开始下一次。并行度为 4,则表示会同时有四个请求一起发送,一起等待,这样子。这个参数将会使用 1 到 4 的并行度去测量吞吐和延迟。-f perf.csv,输出 CSV--shape INPUT__0:3,224,224,设定输入的测试数据形状。
其他参数使用 -h 选项查看吧。
问:perf_analyzer 是如何测量的?
测区间内的吞吐和延迟,不断重复直到获得一个稳定的值。什么是稳定?从
--stability-percentage的帮助信息我们可以看到,“最近三次的测量都在稳定值范围内” 判定为稳定。另外还要看--percentile这个参数,因为需要使用这个参数来计算延迟,比如指定了 95,那么会使用 95% 的请求来计算参数。
下面附上 resnet50 的单个模型实例压测数据,单个模型实例,放在 0 号 gpu 上,gpu 是 V100:
Inferences/Second vs. Client Average Batch Latency
Concurrency: 1, throughput: 68.4 infer/sec, latency 14600 usec
Concurrency: 2, throughput: 119.6 infer/sec, latency 16677 usec
Concurrency: 3, throughput: 252.6 infer/sec, latency 11868 usec
Concurrency: 4, throughput: 287.4 infer/sec, latency 13893 usec
Custom Operations
自定义算子,自定义 layer:https://github.com/triton-inference-server/server/blob/main/docs/custom_operations.md
如果 Backend 支持自定义算子、layer,可以通过设置 LD_PRELOAD 环境变量的方式来预加载。
Model Configuration
https://github.com/triton-inference-server/server/blob/main/docs/model_configuration.md
输入输出形状
- -1 表示可变
- shape 的 rank >= 1,即不允许 0-dim 向量
- max_batch_size 会和声明的 shape 组成输入
- 不支持 batching 的 backend, max_batch_size 必须为 0
- reshape,可以将 triton 接收的输入变成模型需要的输入。可以将 [batch-size, 1] 变成 [batch-size]。前者的产生是因为 triton 不支持 0-dim 向量,后者是模型需要的。通过设置
reshape: { shape: [] }来去掉多余的维度。 - is_shape_tensor: 看文档的意思,客户端请求的时候,不需要带上 batch 维度,triton 会将 batch 维填充到 shape tensor 前。
- allow_ragged_batch: 输入的向量形状可以不一样
batching
- dynamic_batching,开启 batching
- preferred_batch_size,设置大小,当达到其中一个大小,就马上进行推理
- max_queue_delay_microseconds,batching 的排队等待时间
instance group
- 默认情况下,每个 gpu 都有模型实例,指定 gpu 则不会每个 gpu 都开模型实例。
- Name, Platform and Backend,名字要和文件夹对上,platform 和 backend 取决于后端是否在 triton 的列表中
For TensorRT, 'backend' must be set to tensorrt or 'platform' must be set to tensorrt_plan.
For PyTorch, 'backend' must be set to pytorch or 'platform' must be set to pytorch_libtorch.
For ONNX, 'backend' must be set to onnxruntime or 'platform' must be set to onnxruntime_onnx.
For TensorFlow, 'platform must be set to tensorflow_graphdef or tensorflow_savedmodel. Optionally 'backend' can be set to tensorflow.
For all other backends, 'backend' must be set to the name of the backend and 'platform' is optional.
model control mode
https://github.com/triton-inference-server/server/blob/main/docs/model_management.md
启动的时候,指定 --model-control-mode 设置模型控制模式。
- NONE,默认启动所有的模型。
- EXPLICIT,可以使用客户端来启动、卸载模型。启动的时候,可以带上参数
--load-model设置需要加载的模型 - POLL,模型热更新。
ragged batching
https://github.com/triton-inference-server/server/blob/main/docs/ragged_batching.md
允许将不同形状的输入组成一个 batch。出发点是,变长输入,在客户端发送请求的时候,需要 padding。为了避免 padding,triton 提供了相关的选项允许客户端发送变长的输入。
这些变长的输入会组成一个向量。比如 [1, 3], [1, 4], [1, 5] 三个向量会变成一个 [12] 的一维向量,并且 triton 提供了一个额外的输入 INDEX(名字可以自定义) 来保存额外的信息,以重建原始的输入。这个额外的输入有四种模式。
比如 BATCH_ACCUMULATED_ELEMENT_COUNT 模式,INDEX 可以是 [3, 7, 12] 这样的一个向量,表示每个输入向量结束的位置。(这个下标应该是从 1 开始的hhh,在模型的配置文件中可以看到 BATCH_ACCUMULATED_ELEMENT_COUNT_WITH_ZERO 开始是 0, BATCH_ACCUMULATED_ELEMENT_COUNT 开始是 1.
另外还有两种模式,BATCH_ELEMENT_COUNT 表示 INDEX 的元素表示每个输入的大小。BATCH_MAX_ELEMENT_COUNT_AS_SHAPE INDEX 将表示输入向量的最大值。
Shared Memory
https://github.com/triton-inference-server/server/blob/main/docs/protocol/extension_shared_memory.md
Shared Memory 允许客户端使用共享内存的数据,无需通过 HTTP 或者 gRPC 来进行数据通信。共享内存需要注册、注销操作,另外还可以获取状态。
模型放置
这个其实就是 instance group 的作用,比如下面的配置,将会在 2,3 两张卡上各放置一个模型。
instance_group [
{
count: 1
kind: KIND_GPU
gpus: [ 2, 3 ]
}
]
总结
这篇文章前半部分是一个上手介绍,包括导出模型、部署到 Triton、性能测量等。后半部分是 Triton 中一些琐碎的细节,主要是模型配置的细节,而不少细节是服务于实际业务需求的,这一点一定要想明白。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号