我不会用 Triton 系列:Stateful Model 学习笔记
Stateful Models 学习笔记
在 Triton Architecture 的文档中,有一个令我困惑了许久的 feature:Stateful Models。如果你也看不太懂的话,并且想知道或必须知道它是什么东西的话,不妨看看这一篇学习笔记,看看能不能对你有所帮助。下面是我的一点粗浅的理解,如果有错误,恳请您在评论区指出,谢谢~!
链接:https://github.com/triton-inference-server/server/blob/main/docs/architecture.md#stateful-models
概念辨析
在 Triton 中,什么是 Stateful Model 呢?
应用场景:“a stateful model does maintain state between inference requests.” 请求和请求之间,保存了一些状态,所以你希望可以将一连串的请求 (sequence of requests) 发送给同一个模型实例,从而使得模型的状态可以正确的更新。
如果你学习过一些循环神经网络模型的话,你可能会说 RNN、LSTM 等模型就是 Stateful Model。没有错,这些模型确实是有状态的,只不过在 Triton 的某些语境下,Stateful Model 指的是 Stateful Backend(比如上面的那句英语)。状态都是由 Backend 来进行管理的,所以我认为不应该叫 Stateful Model,而应该叫做 Stateful Backend。
将 Stateful Model 叫做 Stateful Backend 是更加合适的,因为一个你不可能去直接导出一个模型,然后利用现有 pytorch backend,tensorflow backend 去用上这个特性。你要用这个特性,不能只靠导出 Model,你需要自己开发一个 Backend 才行。
具体来说,为了使用上 sequence batching,你期望可以从客户端请求那里拿到是否开始、是否结束、一个 sequence id。对于这些信息,你需要在 Custom Backend 里面去获取出来进行处理,现有提供的几个常用的 Backend 并没有这些功能哦。当然你可以使用 Triton Stateful Model 来用上这个 feature。但是呢,不管怎么说,Stateful Model 是和具体的业务强相关的,真正要将这个 feature 用起来,还得自己开发一个 Backend 才行,所以才会说我们应该叫它 Stateful Backend。
用户的 Model 在这里扮演一个什么样的角色呢?你可以理解这个 Model 的输入需要状态向量、数据向量。这些输入的状态向量由 Backend 进行保管,在 Backend 里面,你可以获取到 Start、End、Ready 三种和 Batch Size 等大的一维向量;你也可以拿到一连串请求 (sequence of requests) 的 request id。
Control Inputs
Triton 有四种控制输入:Start、End、Ready、Correlation ID。
文档中提到:“The START tensor must be 1-dimensional with size equal to the batch-size.”,后面的 End 和 Ready 也是和 Batch Size 一样大的一维向量。在 Triton 中,每个实例会开出和 max_batch_size 一样多的 slot,所以 Start、End、Ready 的大小和 max_batch_size 一样多,也和一个 model instance 上的 slot 一样多。
三者的语义分别表示,在对应的 slot 上,是否有一个 request 开始了、结束了、准备好了。对于 Start 和 End,在客户端做请求的时候,只需要设置 infer 接口中对应的选项即可;对于 Ready,由 Triton 来控制。
对于 Correlation ID,表示一连串请求的 id,这一连串的请求都使用这同一个 id,Backend 需要使用这个 id 来找到区分请求。
例子
以官方文档的图为例子。在 Backend 中,我们可以拿到 START 和 READY 两个向量。
- Req0 来了,START 为 [1, 0],表明 Slot0 的请求是一个开始,而 Slot1 不是;READY 为 [1, 0],表明 Slot1 的请求已经准备好了,可以开始推理了。
- Idle。没有请求,Instance0 休息。
- 第一个序列的 Req1 来了,第二个序列的 Req0 来了。此时 START 为 [0, 1],表明 Slot0 的请求不是开始,而 Slot1 的请求是一个开始;READY 为 [1, 1] 表明两个请求都已经准备好了,可以组成一个 Batch 做请求了。
- ...(后面的分析相同了,略)

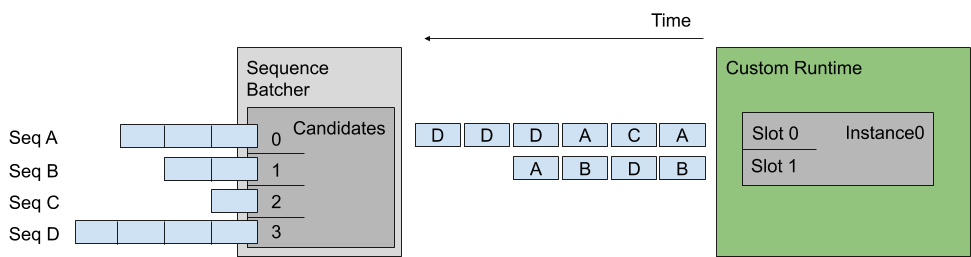
调度策略
direct 策略就是,一个 slot 只处理来自同一个 sequence 的请求;oldest 策略将会从 oldest requests 中形成一个 batch,但是这个 batch 不会包含多余一个来自于同一个 sequence 的 request。对比一下就是,direct 每个 slot 的 请求都是来自同一个 sequence,oldest 每个 slot 的 请求来自不同的 sequence。
这里让我产生困惑的一点是 slot 和 batch 的关系。要明白一点,slot 构成 batch!
Direct 策略
一个 sequence 的请求都由一个 slot 处理。一个 sequence 会占用一个 slot,如果所有的 slot 占满了,那么接下来的 sequence 会进入 backlog 进行等待。这个方法的缺点很明显,就是 sequence 会占用 slot,如果这个 sequence 一直不继续请求,那么这个 slot 就会浪费了。

Oldest 策略
同一个 batch 的请求,都来自不同的 sequence。请求先发送到 Sequence Batcher 排队,Sequence Batcher 负责将请求放入到 slot 中,Oldest 策略中,每个不同的 slot 处理不同的 sequence 的请求,即一个 batch 不会有来自相同 sequence 的请求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号