Serving System 调研
Serving System
本文记录了对 Serving System 的理解,Serving System 顾名思义其实是一个 “系统”。更具体一点,它和 “Web 后台管理系统” 并不存在本质上的区别,都是 “管理系统”!
管理的是什么东西呢?模型、设备。Serving System 可以说是一个 “微服务应用”,因为 Serving System 通常只需要提供 Http 或者 RPC 接口给其他服务调用。在 Web 开发中一些常见的问题和需求,Serving System 同样存在,比如负载均衡、性能监控、运行日志、请求排队等。通常来讲,一个 Web 系统开发好了之后,需要部署到云端上面,这时就需要部署和运维。因此 Serving System 如果提供了 docker 容器,运维人员用起来就很方便了。当设备和机器的数量上去了,构成了一个集群,此时又需要借助 Kubernetes 等工具来进行容器编排和弹性扩展。
Serving System 中存在的需求和挑战
前三点和框架的运行时(Runtime)关系不大:
- 易用性:用户只要给出模型的文件和接口配置文件,一行命令启动,即可提供 Http 或者 RPC 接口。
- 模型格式、模型管理、模型存储、模型版本控制。
- 容器化管理,方便部署。
以下几点和框架关系密切:
- 提供 C API,用户可以将模型推理内嵌到自己的应用中
- 模型转换,训练的模型不一定是可以直接部署的,需要转换成 Serving 需要的格式,比如动态图。
- 模型 pipeline,结合具体的业务场景,有些需求需要多个模型互相协作。
- batching、dynamic batching,将请求积攒到一定数量后再进行推理。
- streaming inference,音视频流数据的处理。
- 模型热更新,如何在不停机的情况下更新模型。
- 分布式推理,需求应该是很少的。
现有的 Serving System
现有的 Serving System 的完善程度各不相同,有的框架只提供了推理 API,还算不上 System,有的框架有完整的 System,一行命令启动服务。下面介绍几种常见的 Serving System。
TensorFlow-Serving
TensorFlow 有专门的 Serving System,叫做 TensorFlow-Serving,提供模型管理的功能。有人说 TF-Serving 太重,不好扩展,直接抽取 C++ 部分的代码出来用,这个操作简直 666 啊。
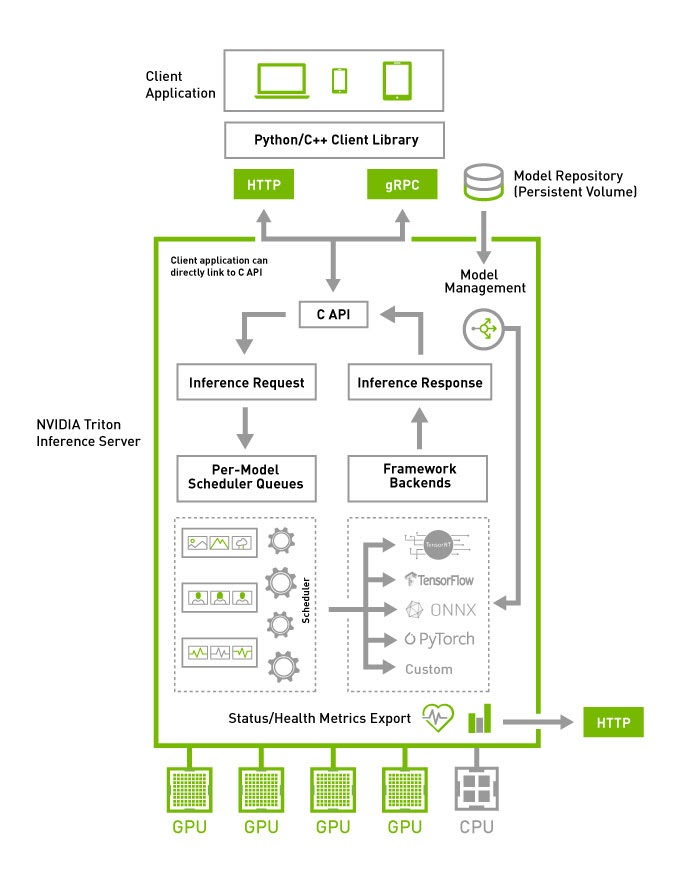
NVIDIA Triton
NVIDIA Triton 特点是提供了容器,可以用 Kubernetes 来容器编排和弹性扩展。另一个特点是共享内存,用户可以使用共享内存来减少 HTTP/gRPC 的调用时间。
Pytorch
Pytorch 只提供了推理 API,需要自己写调用逻辑,写服务接口。
https://pytorch.org/blog/model-serving-in-pyorch/
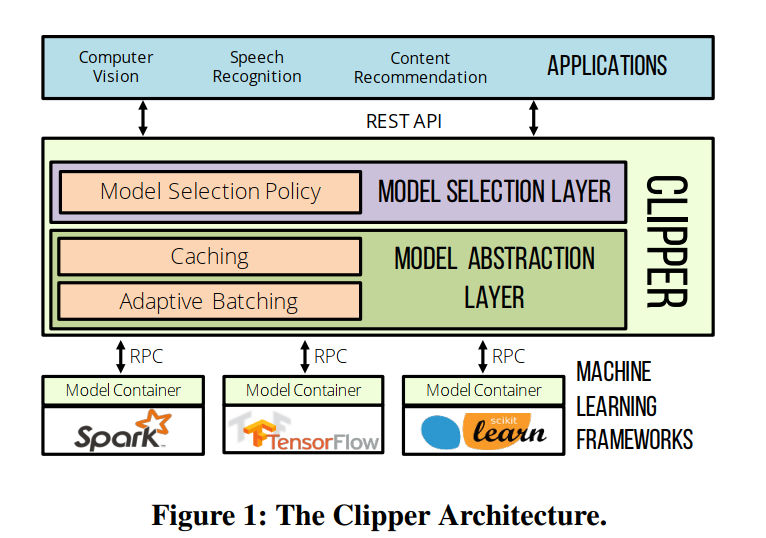
Clipper
比较偏向学术的一个工作,Clipper 引入了 Caching、Batching、Adaptive model selection 等机制来提供推理速度、预测精度。
Paddle Serving
Paddler Serving 服务化部署框架,有容器,支持多模型 pipeline,提供了预处理和后处理操作!(这个真的很重要)
https://github.com/PaddlePaddle/Serving
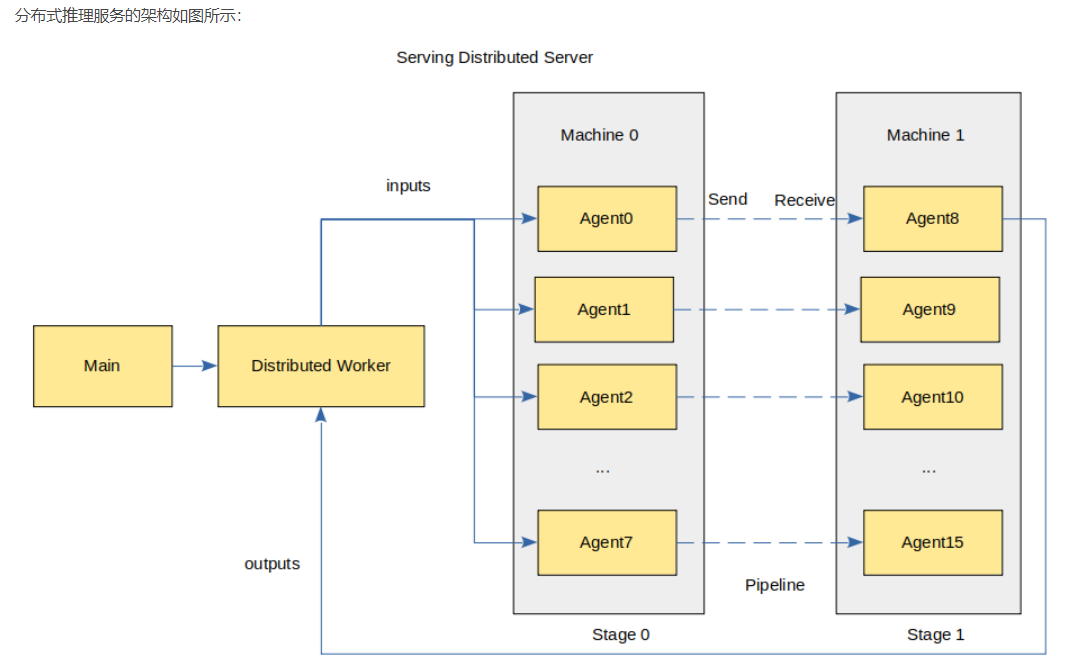
MindSpore Serving
特点是分布式推理服务,支持多卡推理。
Serving System 和 AI 编译器的联系
这里列举我道听途说的几个:TVM,XLA,MLIR。
AI 编译器的出现很大程度是和硬件发展有关系,这让我想起来师兄说的 “系统的发展全靠硬件来推动”。正如 NVM 的出现推动了操作系统和数据库的发展一样,各种计算加速设备的出现则推动了编译器在神经网络中的应用。在写一个框架的时候,计算部分的代码和具体的硬件密切相关,如果不想每一种硬件都写一份代码的话,最好利用编译器来生成。AI 编译器的输入是用户定义的计算图,输出是某个具体硬件设备的可执行文件。既然涉及到了编译器,那么还可以对计算图做图优化、算子融合,提高性能。
AI 编译器在部署上用的比较多,这和 Serving System 就存在一定的联系了。两者都是做模型部署的工作,AI 编译器更加关注硬件、性能,而 Serving System 更加关注系统层面的管理。
Serving System 和推理库的联系
Serving System 不一定需要限定推理的后端,比如 NVIDIA Triton 就支持多种不同的框架 TensorFow,TensorRT,ONNX Runtime。前面提到了 Serving System 中面对的挑战,比如模型管理,dynamic batching 等,而推理只是其中的一个部分,完全可以做模块化,用户想换哪个换哪个。
Java 中有 DJL Deep Java Library,它就好像 Java 中的日志工具 Slf4j 一样,提供了一些接口,具体实现依赖于具体 Jar,想要更换不同的实现,只要换一个 Jar 就好了,你甚至可以自己实现一个。DJL 的道理也是一样的,DJL 提供了统一的接口,如果需要使用不同的实现换个 Jar 包就好。因为缺少一定的实践经验,下面的说法纯属瞎说,不负责的啊:因为不同框架的计算图、内存排布方式存在差异,所以我认为现实并非那么理想,换 Jar 包的同时,还要换 checkpoint 计算图才行。对于一个 Java 程序员来说,有了这种东西,再加上 Java 的生态圈,写一个 Serving System 的难度就减了不少。不过 Serving System 自有 Serving System 的难题,比如 dynamic shape,所以还是要在这些地方下功夫。
一点思考
如果让我来给一个框架写 Serving System,我应该怎么做呢?
你可能会觉得,没必要写 Serving System,将计算图导出到别的格式,然后用别的框架去推理就好了。比如导出 ONNX 模型,然后用 TensorRT 去做推理。
现阶段(2021 年),一个训练框架即使不做 Serving System,至少也得把推理的 API 做好。因为当前还没有统一的算子“规范”,每个框架的算子实现方式、算子支持程度、内存排布方式略有不同,用户导出模型的过程随时有可能会遇到算子不支持的情况,这样的用户体验就不好了。用户可能想要的就是,我用你的接口导出模型,然后一行命令直接运行,给我提供 HTTP 或者 RPC 接口。要做到这一点,最好就是在原框架的运行时上面做推理,因为运行时是一样的,所以并不会存在算子不支持这样的情况。哦是吗?if、while 算子支持么?于是这里就涉及了部署前模型转换的难题了,用户训练的时候用动态图,部署的时候应该如何处理呢?这我就完全搞不懂了,还得多多历练才行啊...
-O-
Over
参考链接
[1] https://kubernetes.io/zh/docs/tutorials/kubernetes-basics/deploy-app/deploy-intro/
[2] https://www.paddlepaddle.org.cn/tutorials/projectdetail/1555945
[3] https://pytorch.org/blog/model-serving-in-pyorch/
[4] https://zhuanlan.zhihu.com/p/305546437

 浙公网安备 33010602011771号
浙公网安备 33010602011771号