OneFlow: 从 Op 到 Job
前言
前面在初始化 Session 的时候,通过 CurJobAddOp 将 Op 加入到计算图当中。在启动 Session 之前,需要将这些 Op 组成的计算图编译成 JobSet。这篇文章主要分析如何从一个个 op 变成一个 Job,Job 如何在 Complete 函数内进行优化的。
流程分析
上一篇文章中,_CompileJob 将会去调用用户定义的 Job 函数,将 Op 加入到计算图中。这个过程执行完成之后,会调用 CurJobBuildAndInferCtx_Complete,生成 Job 或 JobSet(如果用户定义了多个 Job)。Complete 的时候,会执行一些 Pass,将计算图进行改写优化。
# python/oneflow/compatible/single_client/framework/compiler.py: 44
def Compile(session, function_desc, config_proto):
with InterpretScope(session, function_desc, config_proto):
_CompileJob(session, function_desc)
session.StashJob(function_desc.job_func.__name__)
oneflow._oneflow_internal.CurJobBuildAndInferCtx_Complete()
session.StashJob(
function_desc.job_func.__name__,
function_desc.job_func.__name__ + "_after_complete",
)
CurJobBuildAndInferCtx_Complete
Complete 的时候做了什么呢?它的输入是什么?输出又是什么?输入和输出都是 job,问题是这个输入的 job 是从哪里来的呢?我们可以看到 job 和 mut_job 等方法的调用,这些方法返回的都是类成员 job_。这个 job_ 是怎么构造来的呢?
// oneflow/core/job/job_build_and_infer_ctx.cpp: 960
Maybe<void> LazyJobBuildAndInferCtx::Complete() {
CHECK_GT_OR_RETURN(job().net().op_size(), 0)
<< " Sorry, nn.Graph need at least 1 op in net, but get 0 now.";
CHECK_NOTNULL(Global<JobDesc>::Get());
Global<JobDesc>::Delete();
auto scope = std::make_unique<GlobalJobDescScope>(mut_job()->job_conf(), job_id());
JobPassCtx job_pass_ctx(GlobalJobDesc());
auto DoPass = [&](const std::string& pass_name) -> Maybe<void> {
return JobPass4Name(pass_name)(mut_job(), &job_pass_ctx);
};
// ... DoPass
return Maybe<void>::Ok();
}
Job 是哪里来的
来看看构造函数,和 SetJobConf,这两个函数都会修改 JobBuildAndInferCtx 内部的 job_ 成员。
// oneflow/core/job/job_build_and_infer_ctx.cpp: 103
JobBuildAndInferCtx::JobBuildAndInferCtx(Job* job, int64_t job_id)
: job_(job), job_id_(job_id), unique_op_name_index_(0) {
is_job_conf_frozen_ = false;
has_job_conf_ = false;
}
Maybe<void> JobBuildAndInferCtx::SetJobConf(const JobConfigProto& job_conf) {
CHECK_OR_RETURN(!is_job_conf_frozen_) << Error::JobConfFrozenError();
CHECK_OR_RETURN(!has_job_conf_) << Error::JobConfRepeatedSetError();
has_job_conf_ = true;
CHECK_EQ_OR_RETURN(job_->job_conf().job_name(), job_conf.job_name())
<< Error::JobNameNotEqualError() << "job name you set: " << job_conf.job_name()
<< " not equal to origin job name: " << job_->job_conf().job_name();
job_->mutable_job_conf()->CopyFrom(job_conf);
CHECK_ISNULL_OR_RETURN(Global<JobDesc>::Get());
Global<JobDesc>::New(job_conf, job_id_);
return Maybe<void>::Ok();
}
- 如果你对上一篇还有点印象的话,会记得,在 CurJobAddOp 之前,需要调用 SetJobConf。下面是运行 lenet_model.py 的 JobConf。所以 SetJobConf 会对 JobBuildAndInferCtx 的 job_ 成员进行初始化。
job_name: "train_job"
train_conf {
}
- 设置了 JobConf 之后,就可以进行添加算子,调用 CurJobAddOp,然后调用 AddAndInferConsistentOp,最后到了 AddAndInferOp。AddAndInferOp 特别长,主要是进行一些 SBP 属性的推理,对于 SBP 我完全是不懂呢,所以先跳过。总之这个 AddAndInferOp 里面调用了一个重要的方法:AddOpAndUpdateJobParallelViewConf。正如名字暗示的那样,AddOp!
// oneflow/core/job/job_build_and_infer_ctx.cpp: 546
Maybe<OpAttribute> JobBuildAndInferCtx::AddAndInferConsistentOp(const OperatorConf& op_conf) {
CHECK_OR_RETURN(op_conf.has_scope_symbol_id());
const auto& scope = Global<symbol::Storage<Scope>>::Get()->Get(op_conf.scope_symbol_id());
const auto& parallel_desc = *JUST(scope.GetParallelDesc(op_conf));
const auto* job_desc = JUST(scope.job_desc());
return AddAndInferOp(op_conf, parallel_desc.parallel_conf(), job_desc, false);
}
// TODO(): add handle error of same interface op blob between jobs
Maybe<OpAttribute> JobBuildAndInferCtx::AddAndInferOp(const OperatorConf& op_conf,
const ParallelConf& origin_parallel_conf,
const JobDesc* job_desc,
bool is_mirrored_parallel_view) {
// ...
AddOpAndUpdateJobParallelViewConf(*new_op_conf, parallel_desc, nd_sbp_sig_conf,
is_mirrored_parallel_view);
// ...
return op->GetOpAttributeWithoutOpNameAndLbn();
}
- AddOpAndUpdateJobParallelViewConf 这个方法的最后一行,将 Op 添加到了 job_ 里面。于是呢,在我们调用 Complete 的时候,我们可以找到这个 Op,找到整个计算图。
// oneflow/core/job/job_build_and_infer_ctx.cpp: 176
void JobBuildAndInferCtx::AddOpAndUpdateJobParallelViewConf(
const OperatorConf& operator_conf, const ParallelDesc& parallel_desc,
const cfg::NdSbpSignature& nd_sbp_signature, bool is_mirrored_parallel_view) const {
auto* op_name2sbp_sig =
job_->mutable_job_parallel_view_conf()->mutable_op_name2sbp_signature_conf();
auto* op_name2nd_sbp_sig =
job_->mutable_job_parallel_view_conf()->mutable_op_name2nd_sbp_signature_conf();
if (nd_sbp_signature.bn_in_op2nd_sbp().size() > 0) {
nd_sbp_signature.ToProto(&(*op_name2nd_sbp_sig)[operator_conf.name()]);
if (parallel_desc.hierarchy()->NumAxes() == 1) {
cfg::SbpSignature sbp_signature;
NdSbpSignatureToSbpSignature(nd_sbp_signature, &sbp_signature);
sbp_signature.ToProto(&(*op_name2sbp_sig)[operator_conf.name()]);
}
}
auto* op_name2is_mirrored_parallel_view =
job_->mutable_job_parallel_view_conf()->mutable_op_name2is_mirrored_parallel_view();
if (is_mirrored_parallel_view) {
(*op_name2is_mirrored_parallel_view)[operator_conf.name()] = true;
}
job_->mutable_net()->add_op()->CopyFrom(operator_conf);
}
proto 定义
Job
前面的 job_ 其实就是一个 Proto 的 message,不妨将它的定义找来看一看。一个 Job 由 5 个部分组成,其中 DLNetConf 就是计算图,JobConfigProto 表示这个 job 的配置(train 或者 predict)。
// oneflow/core/job/job.proto: 29
message Job {
optional DLNetConf net = 1;
optional Placement placement = 2;
required JobConfigProto job_conf = 3;
optional JobParallelViewConf job_parallel_view_conf = 4;
optional JobHelperConf helper = 5;
}
DLNetConf
DLNetConf 是一个由 OperatorConf 构成的计算图。
message DLNetConf {
repeated OperatorConf op = 1;
}
OperatorConf
OperatorConf 定义了一个算子,算子的名字,算子的设备等信息。
message OperatorConf {
required string name = 1;
optional string device_tag = 4 [default = "invalid_device"];
repeated string ctrl_in_op_name = 7;
optional int64 scope_symbol_id = 8;
optional uint32 stream_index_hint = 9;
optional string pass_tag = 10;
oneof op_type {
// ...
}
}
Complete
既然我们知道了 Job 是怎么来的,它长什么样,那么我们就可以开始尝试着将它画出来!每个 Pass 之后就画一张图看看。OneFlow 中提供了 Graph 基类,里面不仅仅有一些常用的图算法,还有可视化,可以将图转为 .dot 文件。OneFlow 中还提供了一个 OpGraph 类,它接收一个 Job 对象,然后可以调用可视化的方法。
初始计算图
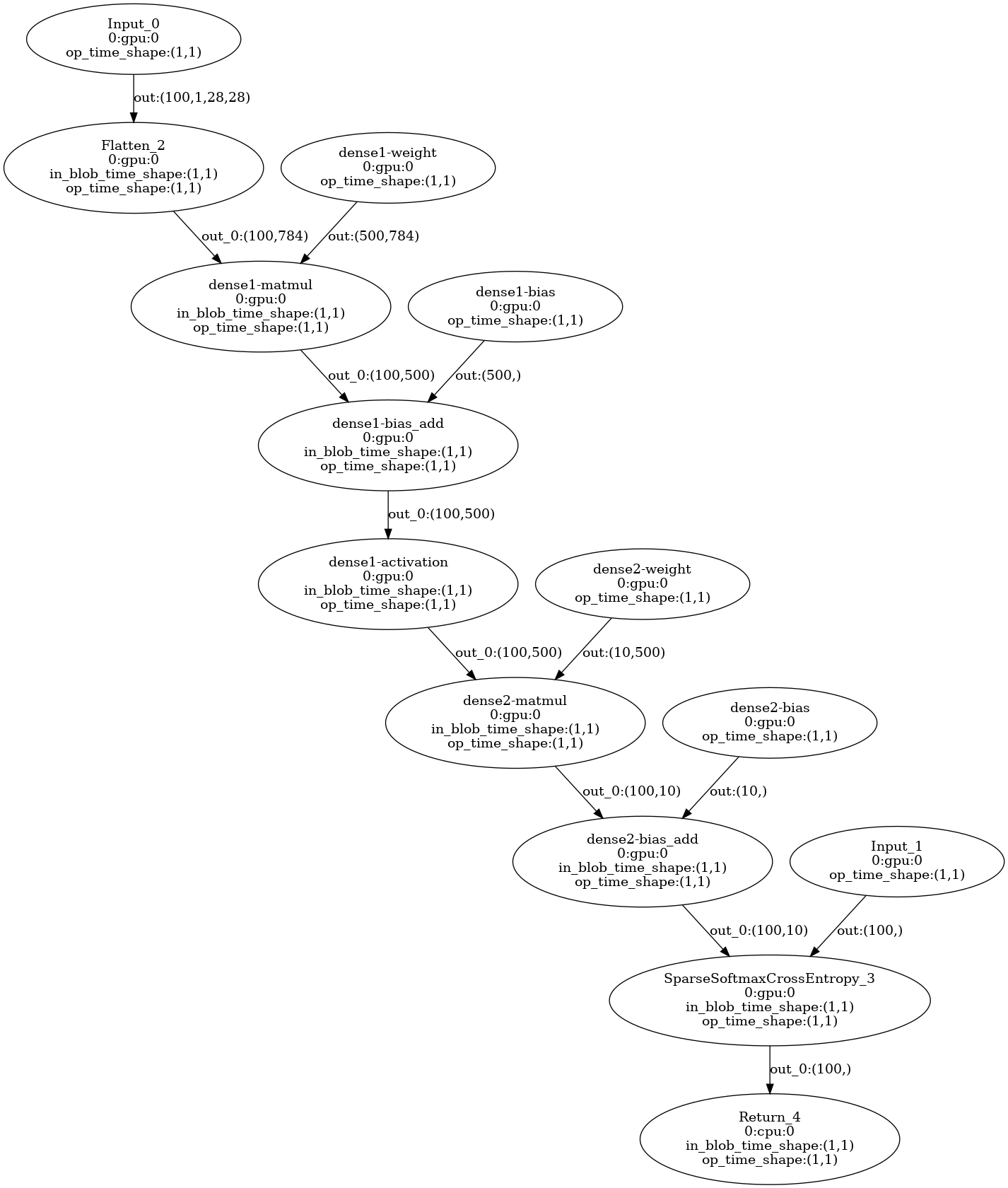
Complete 之前的计算图,就是用户定义的那样,按照 Job 函数里面的算子进行构图,调用 CurJobAddOp 加入到 Job 对象里面。下面就是在 Complete 开始之前可视化出来的计算图。文末附有训练脚本,这次为了方便查看,选择了只有几个节点的 mlp 识别手写字体模型。
最终计算图
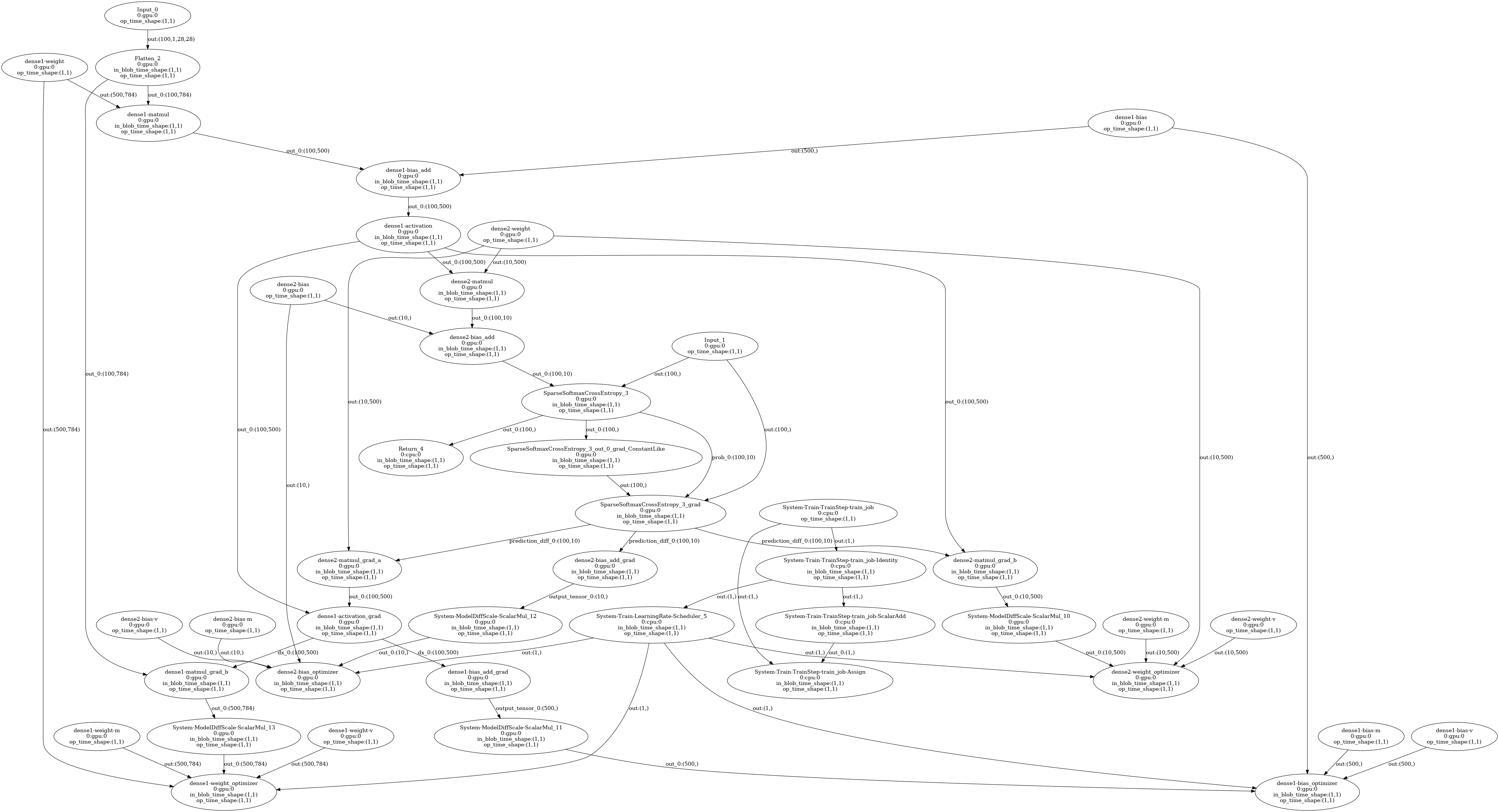
在 Complete 中的 Pass 中,并不是所有的 Pass 都会改写计算图,有的计算图可能因为没有配置,所以不执行。目前肉眼可见对计算图改变最大的 Pass 是:GenerateBackwardAndOptimizerOpConfs。这个 Pass 会生成后向算子和优化器节点。
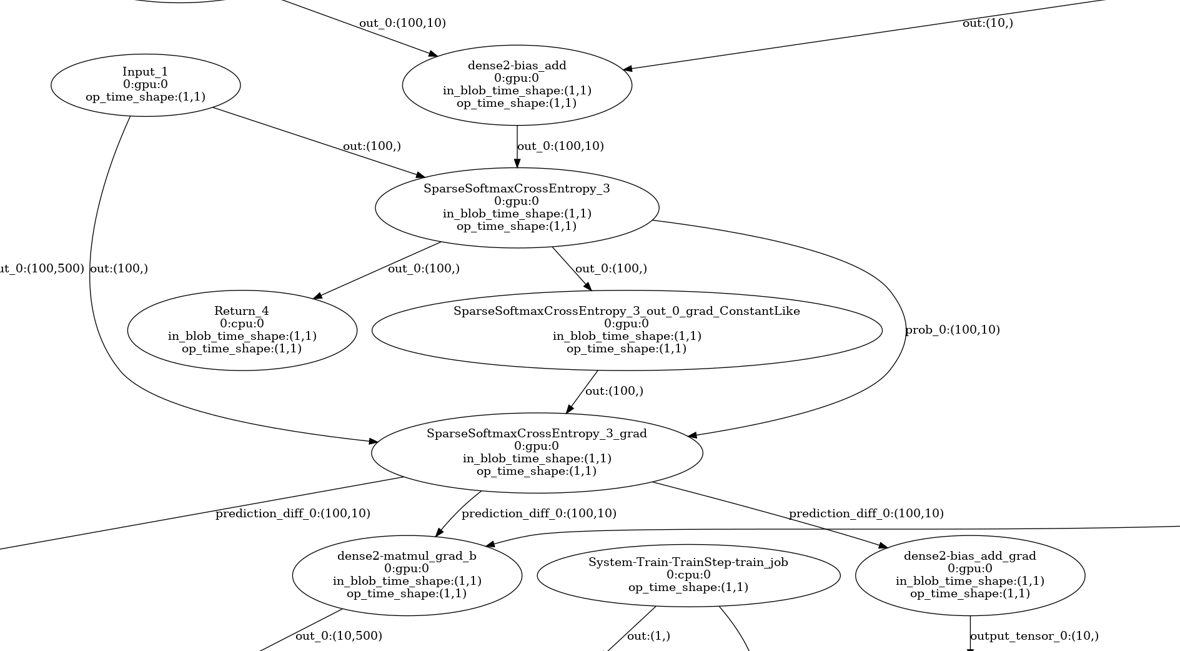
损失函数节点
损失函数节点,接受 Input_1 和 dense2-bias_add 两个节点的输出,Input_1 是标签,dense2-bias_add 是前向传播计算的结果。用这两个节点的值就可以计算出损失。在损失函数节点后面,有三个节点,一个是 Return_4,这个节点输出损失,还有另外两个节点用来输出损失函数的梯度,这两个节点的值我猜想应该是 1。
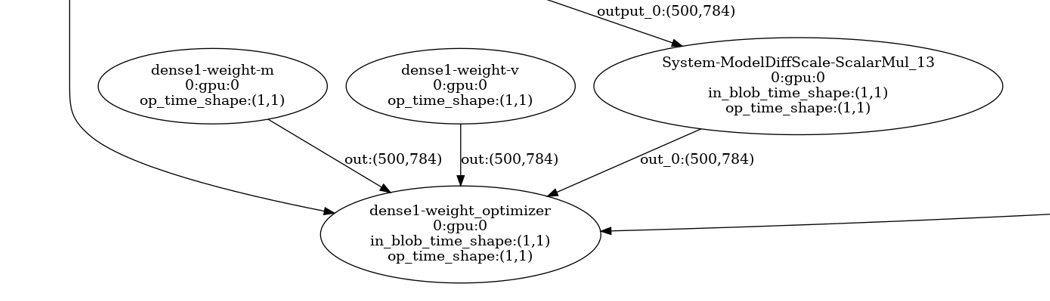
Optimizer 节点
这个训练脚本使用的是 Adam 优化器,Adam 在之前的博客中有记录,对于 dense1 这个权重矩阵,它需要记录动量和梯度平方和,也就是需要两个额外的和 dense1 形状一样的权重矩阵。
附:mlp 识别手写字体
from oneflow.compatible import single_client as flow
from oneflow.compatible.single_client import typing as tp
import numpy as np
BATCH_SIZE = 100
flow.enable_eager_execution(False)
def mlp_model(images, labels, train=True):
# [batch_size, image_sizes] -> [batch_size, pixels]
# reshape = flow.reshape(images, [images.shape[0], -1])
reshape = flow.flatten(images, start_dim=1)
# dense, [batch_size, pixels] -> [batch_size, 500]
initializer1 = flow.random_uniform_initializer(-1 / 28.0, 1 / 28.0)
hidden = flow.layers.dense(
reshape,
500,
activation=flow.nn.relu,
kernel_initializer=initializer1,
bias_initializer=initializer1,
name="dense1"
)
# dense, [batch_size, 500] -> [batch_size, logits]
initializer2 = flow.random_uniform_initializer(
-np.sqrt(1 / 500.0), np.sqrt(1 / 500.0)
)
logits = flow.layers.dense(
hidden,
10,
kernel_initializer=initializer2,
bias_initializer=initializer2,
name="dense2"
)
if train:
loss = flow.nn.sparse_softmax_cross_entropy_with_logits(labels, logits)
return loss
else:
return logits
@flow.global_function(type="train")
def train_job(
images: tp.Numpy.Placeholder((BATCH_SIZE, 1, 28, 28), dtype=flow.float),
labels: tp.Numpy.Placeholder((BATCH_SIZE,), dtype=flow.int32),
) -> tp.Numpy:
with flow.scope.placement("gpu", "0:0"):
loss = mlp_model(images, labels)
flow.optimizer.Adam(
flow.optimizer.PiecewiseConstantScheduler([], [0.001])
).minimize(loss)
return loss
if __name__ == '__main__':
(train_images, train_labels), (test_images, test_labels) = flow.data.load_mnist(
BATCH_SIZE, BATCH_SIZE
)
for epoch in range(20):
for i, (images, labels) in enumerate(zip(train_images, train_labels)):
loss = train_job(images, labels)
if i % 20 == 0:
print("Epoch [{}/{}], Loss: {:.4f}".format(epoch + 1, 20, loss.mean()))
flow.checkpoint.save("./mlp_model")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号