B 树
序
你心里没点 B 树吗?同学之间经常会说起这么一句话。B 树是由 Bayer 和 McCreight 发明的,一开始提出,是为了高效管理大量随机访问文件的索引。这些文件很多,以至于索引也非常多,这就导致了一个问题:内存放不下所有的索引了,这可怎么破?借助于磁盘,可以将索引的一部分写入到磁盘中,等需要的时候,使用磁盘 IO 来读取。如果只是单纯的放到磁盘,那普通的平衡二叉树也可以啊。问题是磁盘 IO 操作是非常耗时的,可以通过优化来大大减少磁盘 IO。B 树非常适应这种和磁盘交互的场景,尽可能的减少 IO 来提高性能。
作为一颗平衡树,B 树支持四种操作:查找、顺序访问、插入、删除。B+ 树在 B 树的基础上改进了一点,只需要叶子节点存储数据,内部节点仅存储键,将叶子节点按顺序连接起来,这样就可以加快顺序访问的速度。
根据 Knuth 的定义,一个 “度为 \(m\) 的 B 树” 有如下 5 中性质:
- 每个节点最多只能有 \(m\) 个孩子。
- 一个非叶、非根节点,至少要有 \(\lceil m/2 \rceil\) 个孩子。
- 如果根节点不是叶子节点,那么至少要有两个孩子。
- 一个非叶节点,有 \(k\) 个孩子,那么节点上就要有 \(k-1\) 个键。
- 所有的叶子节点出现在同一层,并且不携带任何信息。这意味着,每个叶子节点到根节点的距离是一样的,都是树高。
如果将上面的性质组合一下,我们可以得出如下结论
- 根据 1 和 4,每个非叶节点,最多只能有 \(m-1\) 个 key
- 根据 2 和 4,每个非叶非根节点,最少有 \(\lceil m/2 \rceil - 1\) 个 key
上面还缺少一个非常重要的性质,顺序!有两个顺序,第一种顺序,节点内的顺序,节点内的键是按从小到大排序。第二种顺序,父节点和子节点之间的顺序。一个节点的子节点,子节点包含的键值取值范围在父节点中两个键值之间。
这里有两个可视化的链接,后面将结合这两个可视化链接,分析四种操作:
B 树:https://www.cs.usfca.edu/~galles/visualization/BTree.html
B+ 树:https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
B 树
查找
算法,总结起来就一句话:从根节点开始,从左往右,从上到下。
- 从左往右的意思是,在当前节点找一个键,它的值刚好比搜索键大。
- 从上往下的意思是,找到那个键之后,往下寻找。
- 当搜索到叶子节点的时候,从左往右找,找到就存在,找不到就不存在。
初始化
不断插入 1 到 20,然后删除 11,得出如下 B 树。
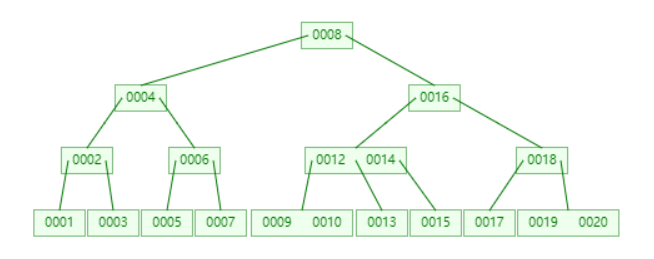
查找 13
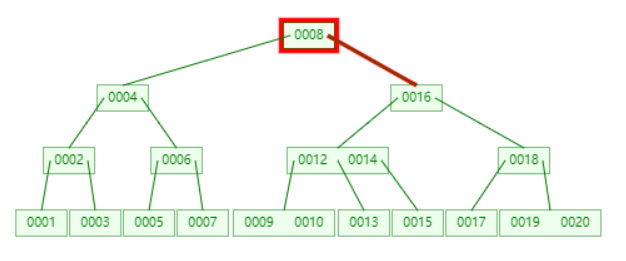
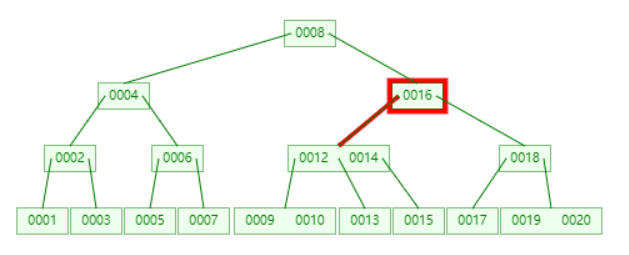
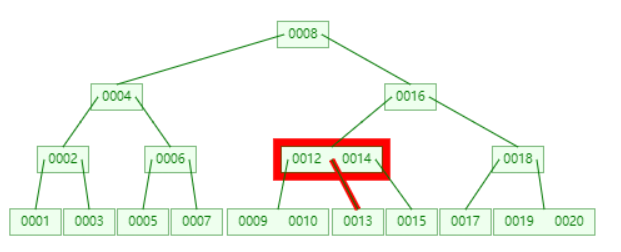
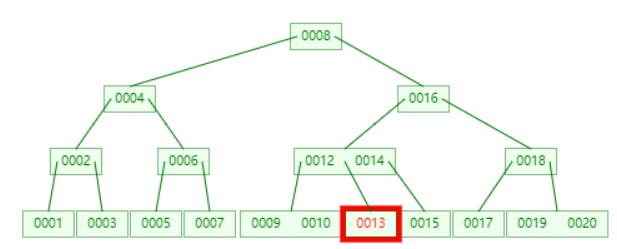
查找 11
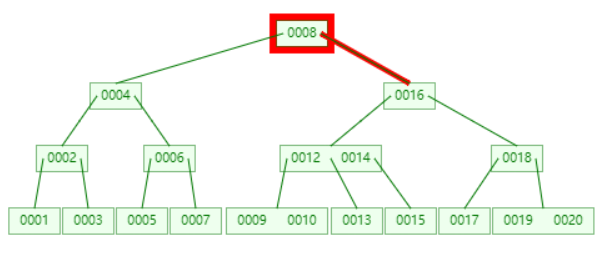
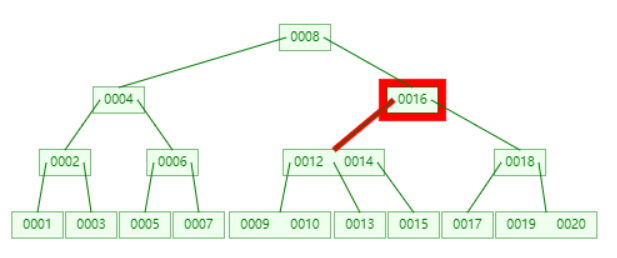
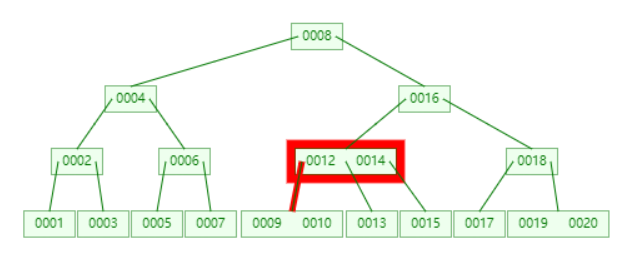

顺序访问
顺序访问的实现,类似二叉树的先序遍历。B 树的节点可以这样存储:child key child ... key child,顺序访问的时候,递归调用 child,然后打印 key,再递归调用 child,再 key...
伪代码:
public void preorder(BtreeNode b) {
if (b.isLeaf) {
for (int i = 0; i < b.keys.length; i++) {
print(b.keys[i]);
}
return;
}
for (int i = 0; i < b.degree - 1; i++) {
preorder(b.children[i]);
print(b.keys[i]);
}
print(b.children[b.degree - 1]);
}
插入
插入算法描述如下:
寻找一个适合插入的叶子节点,这时叶子节点有两种情况:
- 叶子节点少于 \(m-1\) 个键值,直接插入即可。
- 叶子节点刚好有 \(m-1\) 个键值,先插入,然后将中间值提出来,插入到父节点中,并且将这个叶子节点以中间值进行分裂。
插入到父节点可以分为三种情况:
- 父节点少于 \(m-1\) 个键值,直接插入即可
- 父节点刚好有 \(m-1\) 个键值,先插入,然后将中间值提出来,插入到父节点中,并且将这个节点以中间值进行分裂。
- 如果父节点是根节点,并且刚好有 \(m-1\) 个键值,那么同样需要将中间值提出来,创建一个新的根节点,并且原来的节点以中间值进行分裂。
下面展示,在一个度为3 的 B 树中插入 1 ~ 7。
插入 1,2


插入 3
插入到根节点,但是根节点已经有 \(m-1\) 个节点了,于是分裂节点。
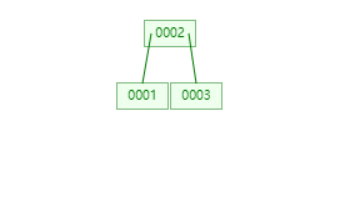
插入 4
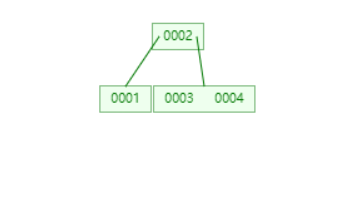
插入 5
找到了 3,4 这个叶子节点,然后插入,发现已经满了,于是分裂,将中间值 4 提到了父节点。父节点没有满,流程结束。
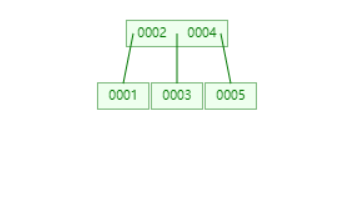
插入 6
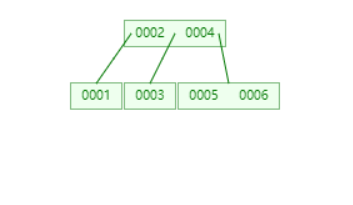
插入 7
找到叶子节点,插入。发现已经满了,提出中间值,插入到父节点。以中间值分裂叶子节点。
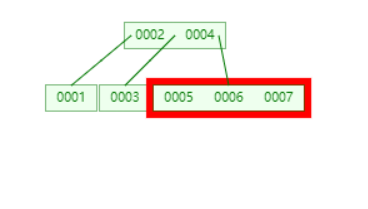
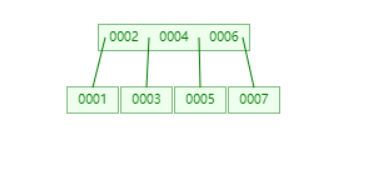
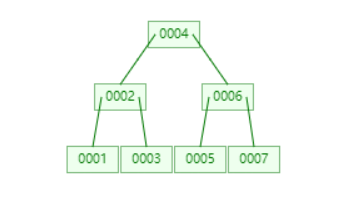
可以发现父节点也满了,以父节点的中间值分裂节点,并且因为父节点刚好是根节点,需要新建根节点。
删除
B 树的插入比较复杂。一般有两种删除的策略,第一种是先定位到元素,删除并重建。第二种是,一边定位一边处理,定位的过程中,处理一下节点,后面删除键值的时候,需要重建。维基百科中介绍了第一种策略。
删除存在两种可能:
- 删除发生在叶子节点,直接删除。如果不够要求的最少数目,进行 rebalance.
- 删除发生在非叶节点,使用那个键的左子树最大值,或者右子树最小值来替代删除的键值。如果子树的叶子节点不够要求的最少数目,进行 rebalance。
rebalance 分为三种情况:
- 如果当前节点的左节点和右节点,其中一个大于 \(\lceil m/2 \rceil - 1\) 个键值,那么可以借一个节点过来。
- 如果当前节点的左节点和右节点,都刚好只有 \(\lceil m/2 \rceil - 1\) 个键值。记删除键的节点为原节点。sibling 节点都不够借了,那么可以将当前节点和 sibling 合并起来。但是如果直接合并的话,会导致父节点少一个子节点。此时,可以做的是,将父节点的键下移到 sibling,然后合并原节点和那个 sibling。此时,父节点如果键不够了,还要递归执行。
- 对于根节点来说,不够的情况,只能是没有键了,这时,直接删除,并且将刚刚新合并的节点作为新的根节点。
ps. 这里的向左节点借一个,实际上的操作是,将左节点的键上移,然后将父节点的一个键下移。这里的向父节点借一个,实际上的操作是,将父节点下移,然后合并原节点和 sibling。
下面使用可视化网站,分别展示三种可能的 rebalance,B 树的度为 5。
从 sibling 借
初始数据
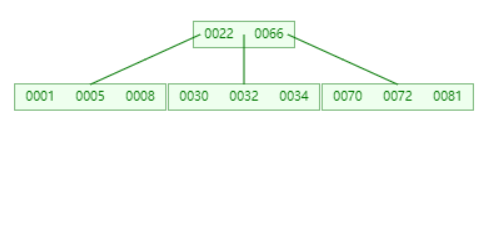
删除 30
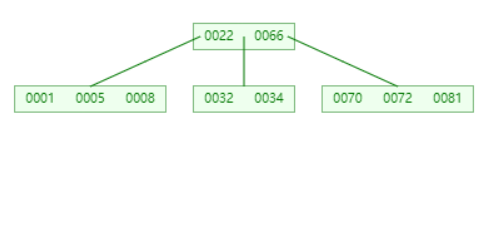
删除 32
删除 32,从左节点借一个过来
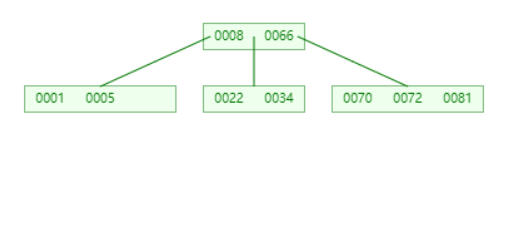
从 parent 借,并且 parent 还够
原始数据
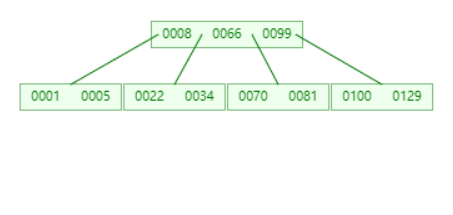
删除 34
此时左右节点都不够借,只能向父节点借了。将父节点的 8 下移到左节点,然后合并。
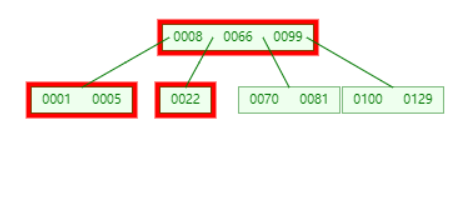
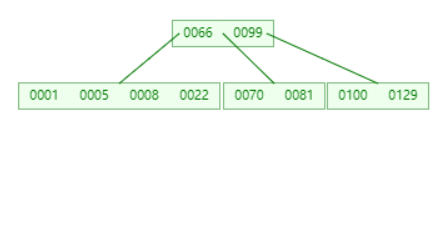
从 parent 借,但是 parent 不够
原始数据
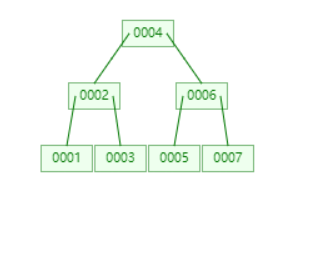
删除 3
定位并删除 3
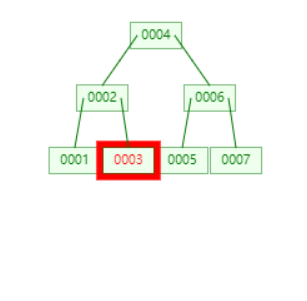
将 2 下移,合并节点。
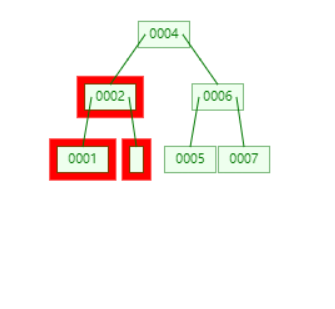
此时会发现,中间的节点达不到最少键数。需要向 sibling 节点借,但是 sibling 还是不够,只能向父节点借。
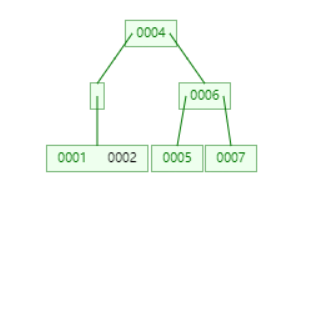
将 4 下移,合并节点。
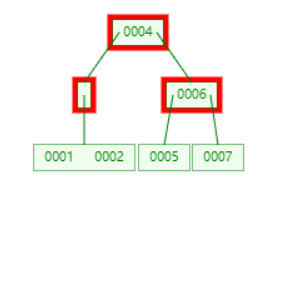
此时,发现根节点已经没有键了。
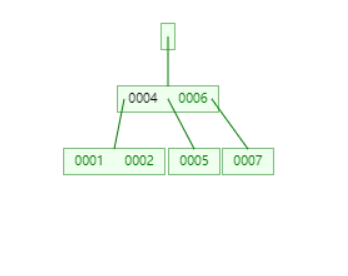
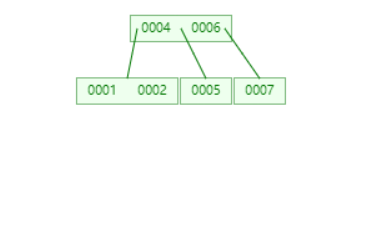
设置新的根节点。
B+ 树
B+ 树在 B 树的基础上改进了一点,只需要叶子节点存储数据,内部节点仅存储键,将叶子节点按顺序连接起来,这样就可以加快顺序访问的速度。
这一篇文章讲解了 B+ 树和 B 树的区别,同时分析了查找和范围查找上的区别。B+ 树在范围查找的时候,速度更快。
查找
过程类似 B 树,不过因为中间节点不存储信息,只存储键,因此需要遍历到叶子节点。
查找 4
过程类似 B 树,从左往右,从上到下。
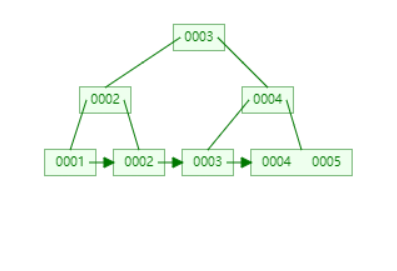
顺序访问
可以从最左边的节点开始,逐个访问。如果需要范围查询,可以先找到下限,然后再往右查。
插入
和 B 树,略有区别的一个地方是,分裂的时候,需要复制键,而不是移动键。因为内部节点只存储键,叶子节点要存储键和数据。因此,键是重复存储的。
原始数据
插入 6
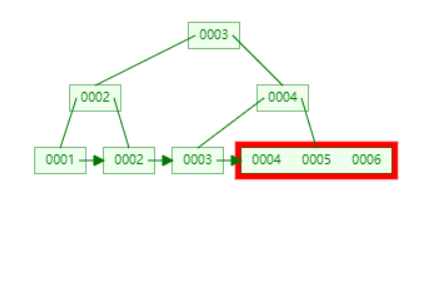
以 4,5,6 的中间值为分割点,分开。并且复制键 5。
删除
删除和 B 树有一个显著的区别,如果删除的键,出现在了内部节点,需要如何处理?
前面提到,删除的键,如果出现在了内部节点,需要如何处理?代码的处理方法是,在 sibling 中找到 nextSmallest,如果没有就设置为空。接着,沿着父指针不断往上,不断替换为 smallest.
之后的处理和 B 树类似。
总结如下:
- 删除时,先定位到叶子节点。找到 nextSmallest,沿着父指针不断往上替代。
- 执行删除,如果叶子节点的数目满足最小要求,那么流程结束。
- 如果叶子节点的数目,小于最小要求,那么需要 repair。分为两种情况,第一种是从 stealing from sibling,另一种是 merging。
- stealing。类似旋转。和 B 树差不多。流程结束。
- merging。将节点合并。如果父节点的键数小于最小要求数目,还需要递归调用 repair。
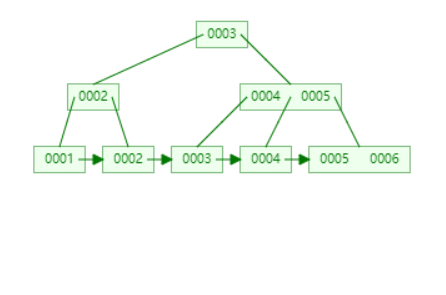
原始数据
删除 3
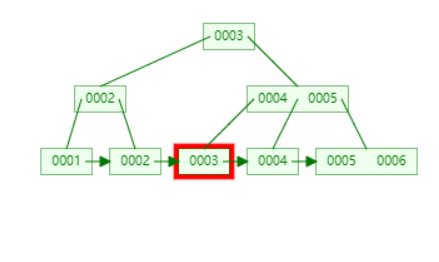
定位到 3,并且需要将所有的 3 替换为 nextSmallest。此时,sibling 不够借,只能 merging。
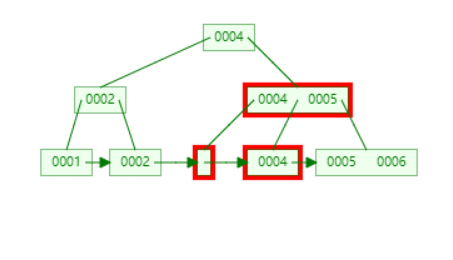
执行 merging。可以不用管 4,5 那个节点中的 4,因为叶子节点一定会有。merging 的方法是,合并右边的 sibling,然后父节点的键整体向左移。
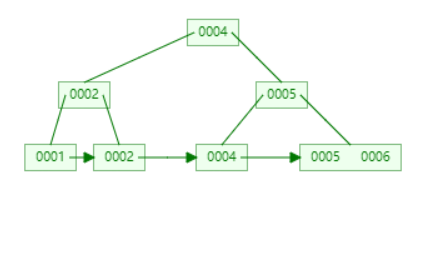
删除 5
直接删除即可。
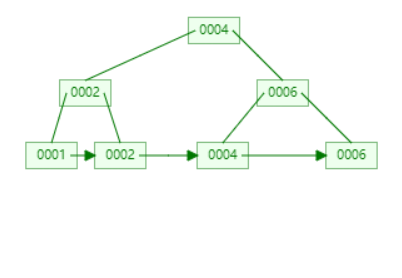
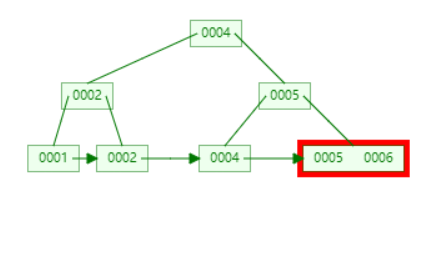
删除 6
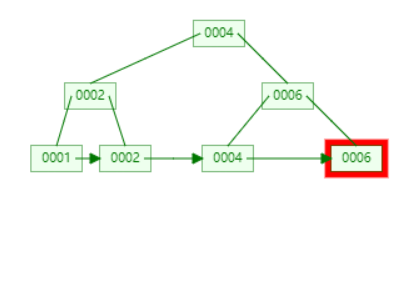
路径上的所有 6 都要设置为 nextSmallest,但是不存在 nextSmallest,所以设置为空即可。
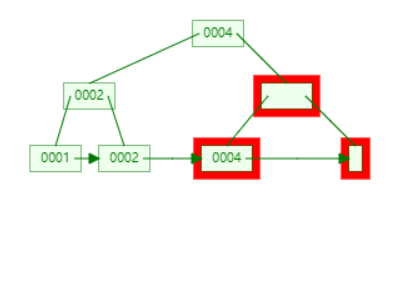
接下来,sibling 借不了,所以执行 merging。
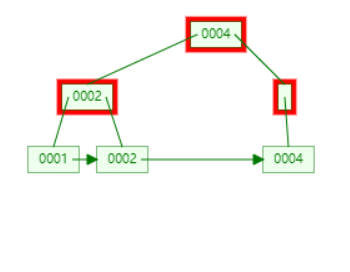
合并之后,父节点的键数还是不够,递归调用。发现 sibling 仍然不够。继续 merging。
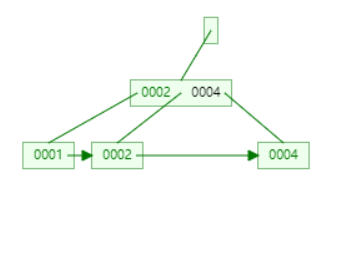
根节点为空了,所以设置新的根节点。
一点反思
数据库
这篇文章最后介绍了,MyISAM 和 InnoDB。两者都是 MySQL 的存储引擎,使用的原理都是 B+ 树。
- MyISAM 将索引文件和数据文件分开,索引文件存储元组的偏移量。辅助索引,同样存储元组的偏移量。如果偏移量发生改变,两个索引都得修改。
- InnoDB 单个文件,主索引的叶子节点还要存储数据,不是存储偏移量。辅助索引,存储的叶子节点存储主键。这个就没有 MyISAM 的烦恼了,不需要修改两个索引,但是需要查找两次才行。
实现
B 树是用来优化 IO 操作的,上面的算法几乎不涉及实现中,如何优化。一般来说,可以设置一个节点为一个 4K block,将节点写入到文件,当需要的时候,读入内存当中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号