

django框架-3
小练习
作业题:用django编写用户数据的增删改查
自己写这道题整理的一些思路~
准备工作(养成习惯):
1.mysql里创建用的库(create database day57;)
2.去settings里修改配置
'DIRS' = [os.path.join(BASE_DIR,'templates')]
MIDDLEWARE的第四行注掉
看一下INSTALLED_APPS 最后一行app有没有注册好
3.DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'day57',
'HOST': '127.0.0.1',
'PORT': 3306,
'USER': 'root',
'PASSWORD': '666',
'CHARSET': 'utf8'
}
}
4.最下方静态配置文件
STATICFILES_DIRS = [
os.path.join(BASE_DIR,'static')
]
5.此时类是空壳 去models建表 输入:姓名 年龄等 记录迁移表makemigrations和migrate
6.启动database里的mysql 建立链接
7.之前下好的bootstrap-3.4.1-dist放到templates中
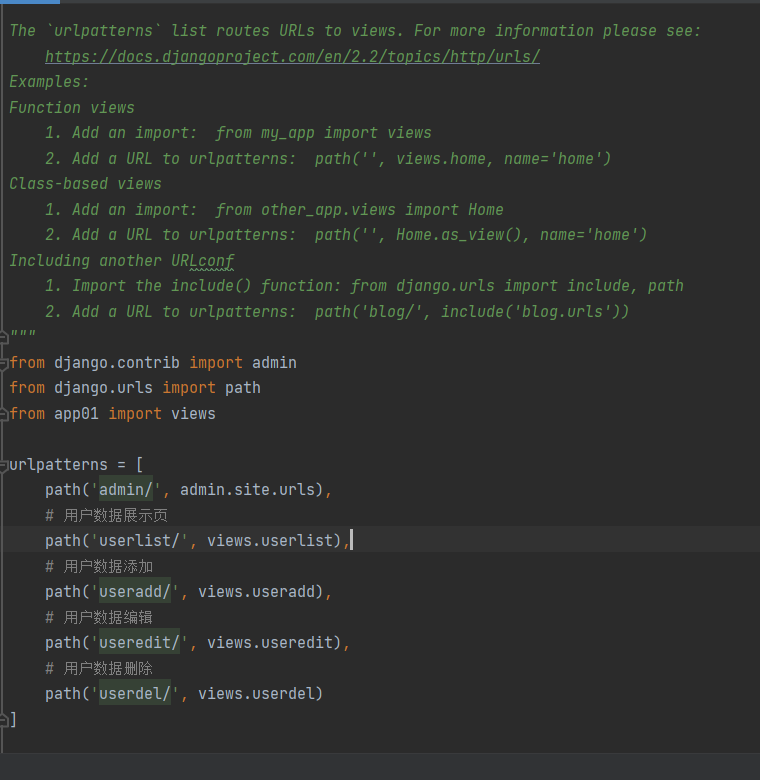
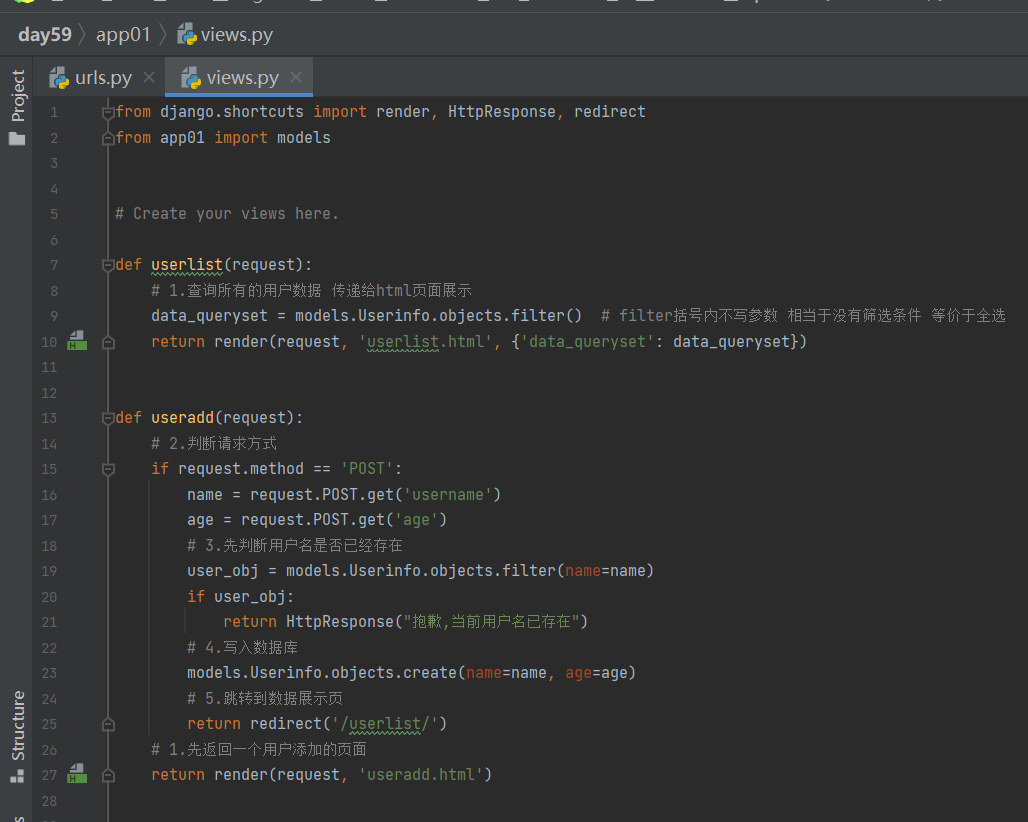
数据展示页
1.在urls中先写数据展示页 导过来views
2.查询所有的用户数据 传递给html页面展示 小知识点:filter括号内不写参数 相当于没有筛选条件 等价于全选
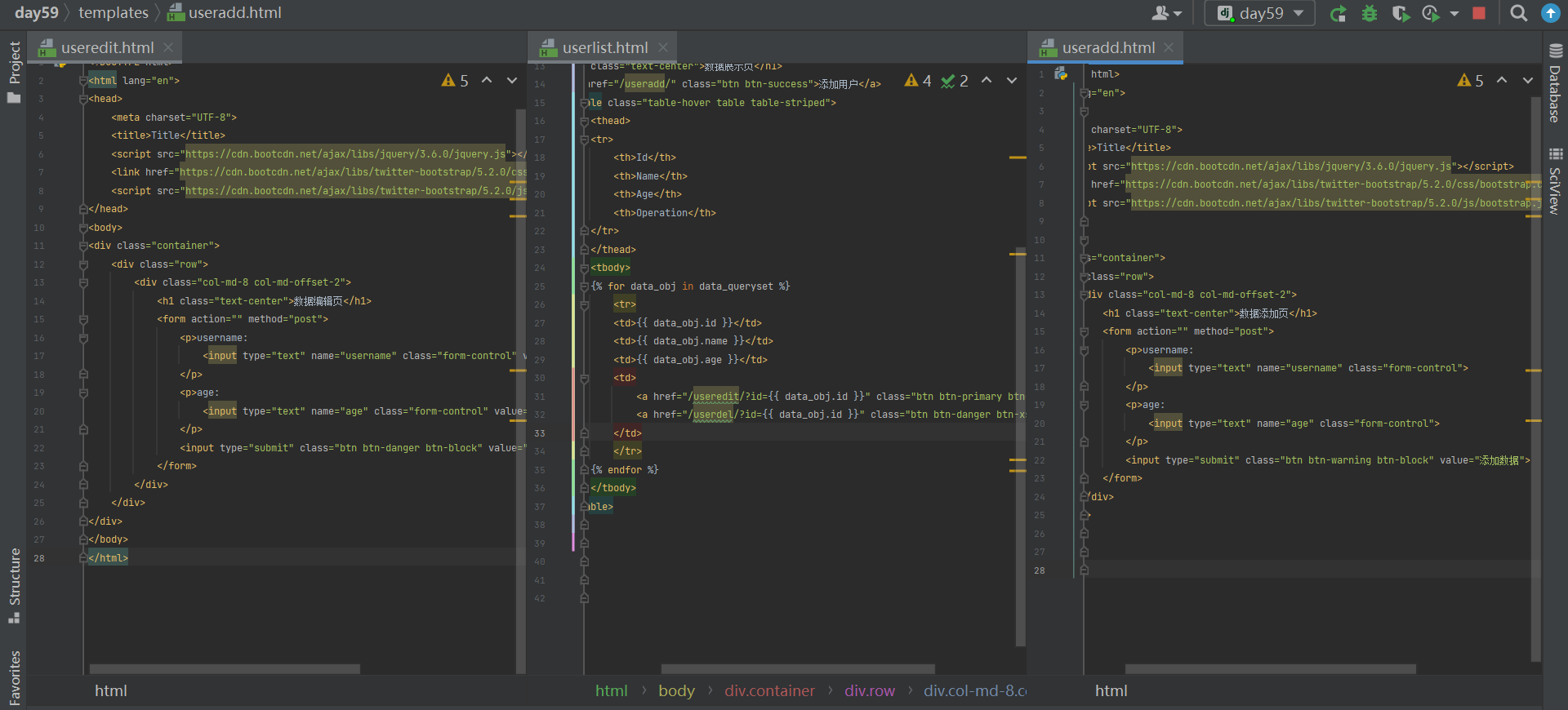
3.templates创建userlist.html
4.mysql里创建数据
数据添加功能
1.建对应关系 函数 封装添加数据页面 在userlist的a标签链接添加数据的地址
2.添加数据页面建好后 判断请求方式 获取用户名和年龄 判断用户名是否已存在
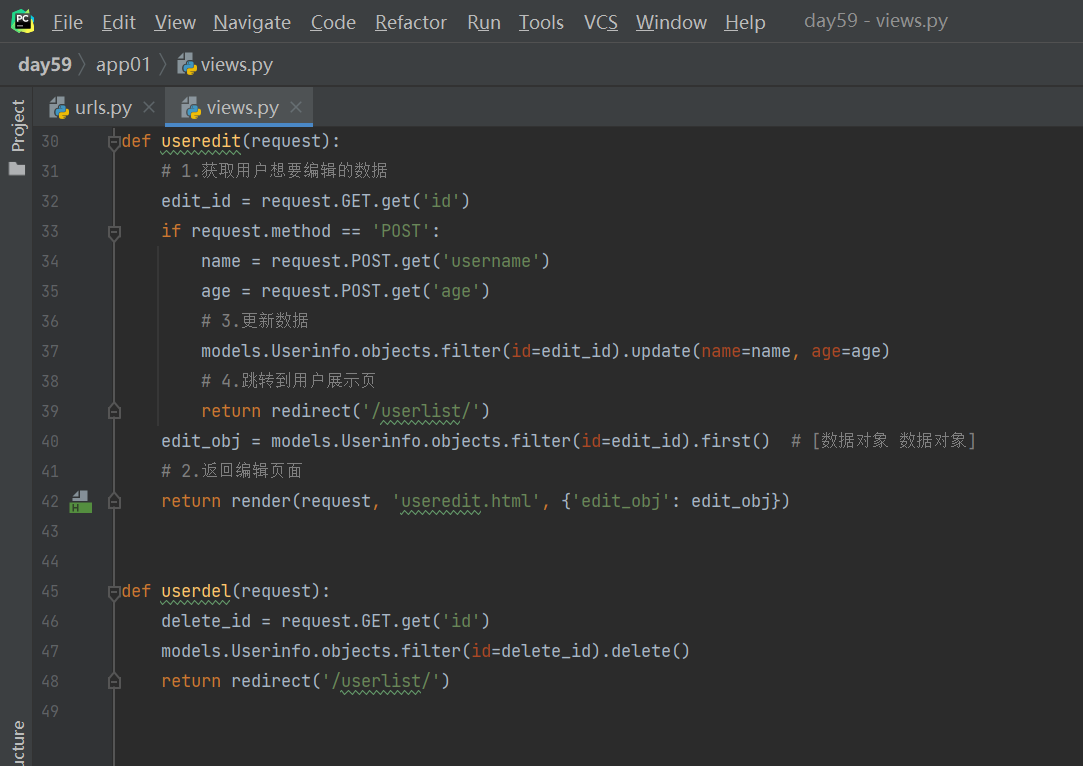
数据编辑功能
1.建对应关系 函数 封装编辑数据页面
2.考虑修改的数据关系 id ?id={{data_obj.id}}
3.获取用户想要编辑的数据
4.页面 value导过去
5.更新数据
6.跳转到用户展示页
数据删除功能
1.类比编辑功能 找到删除的id
2.获取id 删除 跳转回列表页面
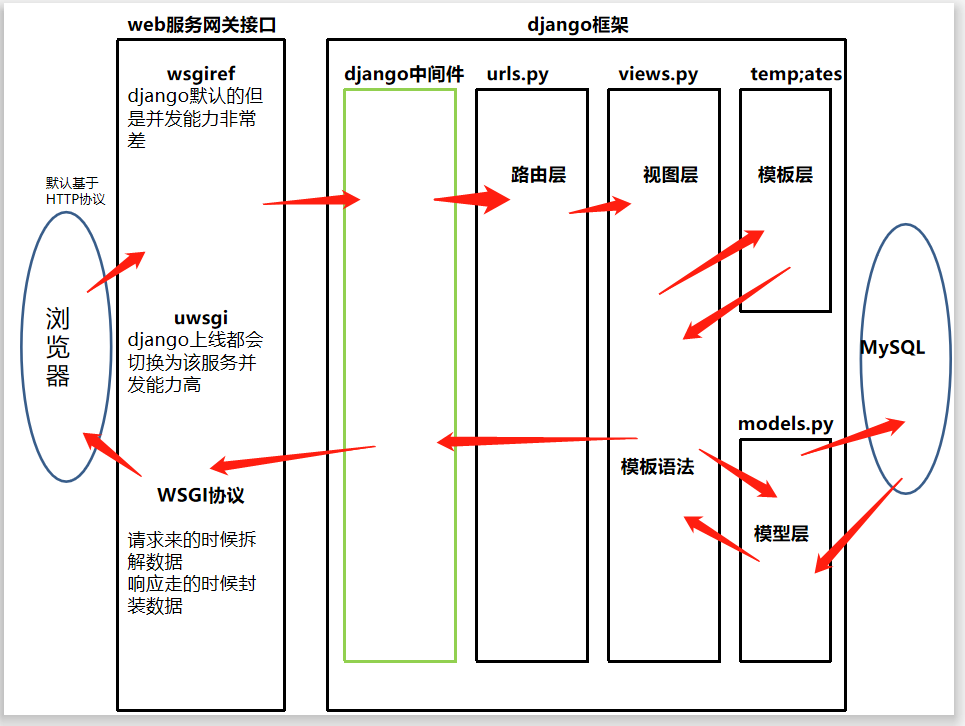
django请求生命周期流程图
话不多说 上图!!!
路由匹配
path('网址后缀',函数名)
一旦网址后缀匹配上了就会自动执行后面的函数
并结束整个路由的匹配
1.路由结尾的斜杠
默认情况下不写斜杠 django会做二次处理
第一次匹配不上 会让浏览器加斜杠再次请求
django配置文件中可以制定是否自动添加斜杠
APPEND_SLASH = False
2.path转换器
当网址后缀不固定的时候 可以使用转换器来匹配
'int': IntConverter(),
'path': PathConverter(),
'slug': SlugConverter(),
'str': StringConverter(),
'uuid': UUIDConverter(),
path('func/<int:year>/<str:info>/', views.func)
转换器匹配到的内容会当做视图函数的关键字参数传入
转换器有几个 都叫什么名字 那么视图函数的形参必须对应
def func(requesr,year,info):
pass
2.re_path正则匹配
re_path(正则表达式,函数名)
一旦网址后缀的正则能够匹配到内容就会自动执行后面的函数 并结束整个路由的匹配 re_path('^test/$', views.test)
当网址后缀不固定的时候 可以使用转换器来匹配
3.正则匹配之无名分组
re_path('^test/(\d+)/', views.test)
正则表达式匹配到的内容会当做视图函数的位置参数传递给视图函数
4.正则匹配之有名分组
re_path('^test/(?P<year>\d+)/(?P<others>.*?)/', views.test)
正则表达式匹配到的内容会当做视图函数的关键字参数传递给视图函数
5.django版本区别
在django1.11中 只支持正则匹配 方法是url()
在django2 django3 django4中 path() re_path()等价于url()
反向解析
页面上提前写了很多固定的路由 一旦路由发送变化会导致所有页面相关链接失效 为了防止出现该问题 我们才使用反向解析
"""
反向解析:返回一个结果 该结果可以访问到对应的理由
"""
1.路由对应关系起别名
path('register/', views.reg, name='reg_view')
2.使用反向解析语法
html页面
{% url 'reg_view' %}
后端
from django.shortcuts import reverse
reverse('reg_view')
ps:反向解析到的操作三个方法都一样path() re_path() url()
无名有名反向解析
path('reg/<str:info>/', views.reg, name='reg_view')
当路由中有不确定的匹配因素 反向解析的时候需要人为给出一个具体的值
reverse('reg_view', args=('jason',))
{% url 'reg_view' 'jason' %}
ps:反向解析的操作三个方法都一样path() re_path() url()
路由分发
django中的应用都可以有自己独立的urls.py templates文件夹 static文件夹
能够让基于django开发的多个应用完全独立 便于团队开发
总路由
path('app01/', include('app01.urls')),
path('app02/', include('app02.urls')),
子路由
path('after/', views.after) # app01
path('after/', views.after) # app02
"""
当项目特别大 应用特别多的时候 可以使用路由分发非常方便!!!
"""
名称空间
有路由分发场景下多个应用在涉及到反向解析别名冲突的时候无法正常解析
解决方式1
名称空间
namespace
path('app01/', include(('app01.urls', 'app01'), namespace='app01'))
path('app01/', include(('app01.urls', 'app02'), namespace='app02'))
解决方式2
别名不冲突即可
"""
那么麻烦 你就保证django项目下没有重复的别名即可
"""
9.1小练习
1.简述数据库表设计中一对一、一对多、多对多的应用场景,char与varchar的区别
一对一:一个只能对应一个 类似于一个人只能有一个身份证
一对多:一件事物能对应多种事物 一个班级可以有多个学生 学生只能有一个班级
多对多:多件事物对应多件事物 一位作者可以写多本书 一本书可以有多个作者
char是定长的,也就是当你输入的字符小于你指定的数目时,char(8),你输入的字符小于8时,它会再后面补空值。当你输入的字符大于指定的数时,它会截取超出的字符。
varchar:存储变长数据,但存储效率没有CHAR高,必须在括号里定义长度,可以有默认值。保存数据的时候,不进行空格自动填充,而且如果数据存在空格时,当值保存和检索时尾部的空格仍会保留。另外,varchar类型的实际长度是它的值的实际长度+1,这一个字节用于保存实际使用了多大的长度。
2.有一个列表[3,4,1,2,5,6,6,5,4,3,3]请写出一个函数,找出该列表中没有重复的数的总和
lst = [3,4,1,2,5,6,6,5,4,3,3]
l1 = [3,4,1,2,5,6,6,5,4,3,3]
x = 0
s1 = set(l1)
for i in s1:
x += i
print(x)
3.什么是函数的递归调用?书写递归函数需要注意什么?你能否利用递归函数打印出下面列表中每一个元素(只能打印数字),l = [1,[2,[3,[4,[5,[6,[7,[8,[9]]]]]]]]]
l = [1,[2,[3,[4,[5,[6,[7,[8,[9]]]]]]]]]
def abc(li):
for i in li:
if type(i) != list:
print(i)
else:
abc(i)
abc(l)
4.谈谈你对web框架的认识,简述web框架请求流程并列举出python常见web框架
web框架理解为浏览器版socket服务端,能连接前端和后端开发数据库,使他俩不再成为单独的个体
首先一个浏览器通过http协议发送一个请求,到我们的服务器,首先是web服务网关接口,接收到这个请求,这里Django默认用的是wsgiref模块这个模块首先解析这个请求中的数据,并将这个数据全部解析成一个reque的大字典,wsgiref封装的就是socket连接和数据解析的功能,解析之后得到数据,就能知道浏览器的请求是什么,然后拿着请求类型和urls中的路由与视图函数映射关系获取到到低是要哪个视图,匹配成功之后,再到views.py的具体的视图中去,执行这个具体的特定的视图函数,这个视图函数在执行的过程中,需要首先到templates模板层中去找到特定的html文件,这个html文件就是前端渲染出来的效果,这个html可以通过
模板语法得到后端也就是这个视图函数中生成好的数据,在这个过程中视图函数也可以去操作模型层,通过模型层的orm,生成数据库的表,这个模型可以连接到
后端的数据库,这个数据库可以是mysql 也可以是mongoDB,很多数据库都可以,模型来操作数据库,视图函数将得到的模板html文件,与模型一起渲染,最后将
结果发送给wsgiref模块也就是web网关接口,web网关接口再将数据打包使其符合HTTP协议发送到浏览器,这样一次完整的请求就算结束了
Django flask tornado


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)