openpyxl模块读取数据
from openpyxl import Workbook, load_workbook
wb = Workbook()
wb1 = wb.create_sheet('红浪漫消费记录', 0)
wb2 = wb.create_sheet('天上人间消费记录')
wb3 = wb.create_sheet('白马会所消费记录')
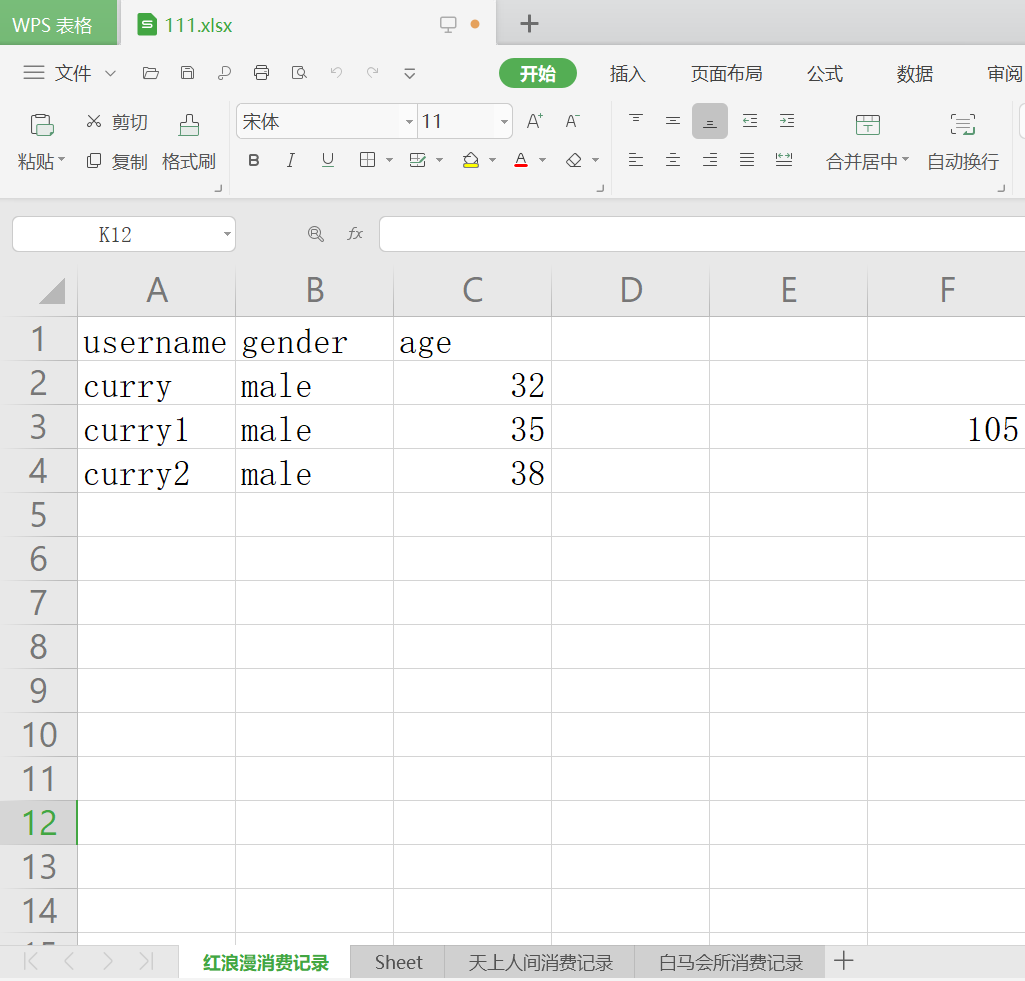
wb1.append(['username', 'gender', 'age'])
wb1.append(['curry', 'male', 32])
wb1.append(['curry1', 'male', 35])
wb1.append(['curry2', 'male', 38])
wb1['f3'] = '=sum(c2:c4)'
wb.save(r'111.xlsx')
wb = load_workbook(r'111.xlsx', data_only=True)
print(wb.sheetnames)
wb1 = wb['红浪漫消费记录']
print(wb1.max_row)
print(wb1.max_column)
print(wb1['A1'].value)
print(wb1.cell(row=2, column=2).value)
for i in wb1.columns:
print([i.value for i in j])
"""
openpyxl1不擅长读数据 所以有一些模块优化了读取的方式
pandas模块
一层层优化(站在巨人的肩膀上)
"""
爬取链家二手房源一页数据
"""
封装了openpyxl的pandas模块操作excel表格的方式
import pandas
d = {
'公司名称': ['老男孩', '老女孩', '老伙计', '老北鼻'],
'公司地址': ['上海', '深圳', '杭州', '东京'],
'公司电话': [120, 130, 129, 996],
}
df = pandas.DataFrame(d)
df.to_excel(r'222.xlsx')
"""
import requests
with open(r'lj.html', 'r', encoding='utf8') as f:
data = f.read()
home_title_list = re.findall(
'<a class="" href=".*?" target="_blank" data-log_index=".*?" data-el="ershoufang" data-housecode=".*?" data-is_focus="" data-sl="">(.*?)</a>',
data
)
home_name_list = re.findall(
'<a href=".*?" target="_blank" data-log_index=".*?" data-el="region">(.*?) </a>',
data
)
home_addr_list = re.findall(
' - <a href=".*?" target="_blank">(.*?)</a>',
data
)
home_info_list = re.findall(
'<div class="houseInfo"><span class="houseIcon"></span>(.*?)</div>',
data
)
home_others_list = re.findall(
'<div class="followInfo"><span class="starIcon"></span>(.*?)</div>',
data
)
home_total_price = re.findall(
'<div class="totalPrice totalPrice2"><i> </i><span class="">(.*?)</span><i>万</i></div>',
data
)
home_unit_price = re.findall(
'<div class="unitPrice" data-hid=".*?" data-rid=".*?" data-price=".*?"><span>(.*?)</span></div>',
data
)
d = {
'房屋标题':home_title_list,
'小区名称':home_name_list,
'所在街道':home_addr_list,
'具体信息':home_info_list,
'其他信息':home_others_list,
'房屋总价':home_total_price,
'房屋单价':home_unit_price
}
df = pandas.DataFrame(d)
df.to_excel(r'333.xlsx')

andom随机数模块
import random
print(random.random())
print(random.randint(1, 10))
print(random.choice(['一等奖', '二等奖', '三等奖']))
print(random.sample(['快男', '老铁', '铁子', '宝贝'], 3))
l1 = ['A', 1, 2, 3, 4, 5, 6, 7, 8, 9, 'J', 'Q', 'K']
random.shuffle(l1)
print(l1)
"""搜狗python工程师笔试题"""
code = ''
for i in range(5):
random_int = str(random.randint(0,9))
random_lower = chr(random.randint(97,122))
random_upper = chr(random.randint(65,90))
temp = random.choice([random_int, random_lower ,random_upper])
code += temp
print(code)
def get_code(n):
code = ''
for i in range(n):
random_int = str(random.randint(0,9))
random_lower = chr(random.randint(97,122))
random_upper = chr(random.randint(65,90))
temp = random.choice([random_int, random_lower ,random_upper])
code += temp
return code
res = get_code(4)
print(res)
res1 = get_code(10)
print(res1)
hashlib加密模块
1.什么是加密
将明文数据(看得懂)经过处理之后变成密文数据(看不懂)的过程
2.为什么要加密
不想让敏感的数据轻易的泄露
3.如何判断当前数据值是否已经加密
一般情况下如果是一串没有规则的数字字母符合的组合一般都是加密之后的结果
4.加密算法
就是对明文数据采用的加密策略
不同的加密算法复杂度不一样 得出的结果长短也不一样
通常情况下加密之后的结果越长 说明采用的加密算法越复杂
5.常见加密算法
md5 sha系列 hmac base64
6.代码实参
import hashlib
md5 = hashlib.md5()
md5.update(b'123')
res = md5.hexdigest()
print(res)
加密模块补充说明
1.加密之后的结果一般情况下不能反解密
202cb962ac59075b964b07152d234b70
"""
所谓的反解密很多时候其实是偷换概念
提前假设别人的密码是什么 然后用各种算法算出对应的密文
之后构造对应关系 然后比对密文 最终映射明文
{'密文1':123,'密文2':321,...}
"""
2.只要明文数据是一样的那么采用相同的算法得出的密文肯定一样
import hashlib
md5 = hashlib.md5()
md5.update(b'123')
md5.update(b'hello')
md5.update(b'curry')
res = md5.hexdigest()
print(res)
md5.update(b'123hellocurry')
res = md5.hexdigest()
print(res)
3.加盐处理(salt)
干扰项每次都不一样
eg:每次获取当前时间 每个用户用户名截取一段
4.动态加盐(salt)
干扰项每次都不一样
eg:每次获取当前时间 每个用户用户名截取一段
5.加密实际应用场景
1.用户密码加密
注册存储密文 登录也是比对密文
2.文件安全性校验
正规的软件程序写完之后做一个内容的加密
网址提供软件文件记忆该文件内容对应的密文
用户下载完成后不直接运行 而是对下载的内容做加密
然后比对两次密文是否一致 如果一致表示文件没有被改
不一致则表示改程序有可能被植入病毒
3.大文件加密优化
程序文件100G
一般情况下读取100G内容然后全部加密 太慢
不对100G所有的内容加密 而是截取一部分加密
eg:每隔500M读取30bytes
subprocess模块
模拟计算机cmd命令窗口
import subprocess
cmd = input('请输入您的指令>>>:').strip()
sub = subprocess.Popen(cmd,
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
print(sub.stdout.read().decode('gbk'))
print(sub.stderr.read().decode('gbk'))
日志模块
"""日志模块需要你写的代码很少 几乎都是CV"""
1.什么是日志
日志就类似于是历史记录
2.为什么要使用日志
为了记录事物发生的事实(史官)
3.如何使用日志
3.1.日志等级
import logging
logging.debug('debug等级')
logging.info('info等级')
logging.warning('warning等级')
logging.error('error等级')
logging.critical('critical等级')
3.2.基本使用
import logging
file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf-8',)
logging.basicConfig(
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
handlers=[file_handler,],
level=logging.ERROR
)
logging.error('我不好行了吧!!!')
日志模块组成部分
import logging
logger = logging.getLogger('购物车记录')
hd1 = logging.FileHandler('a1.log', encoding='utf-8')
hd2 = logging.FileHandler('a2.log', encoding='utf-8')
hd3 = logging.StreamHandler()
fm1 = logging.Formatter(
fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
)
fm2 = logging.Formatter(
fmt='%(asctime)s - %(name)s: %(message)s',
datefmt='%Y-%m-%d',
)
logger.addHandler(hd1)
logger.addHandler(hd2)
logger.addHandler(hd3)
hd1.setFormatter(fm1)
hd2.setFormatter(fm2)
hd3.setFormatter(fm1)
logger.setLevel(10)
logger.debug('写了半天 累啊!!!!!!')
"""
我们在记录日志的时候 不需要向上述一样全部自己写 过于繁琐
所以该模块提供了固定的配置字典直接调用即可
"""
日志配置字典
import logging
import logging.config
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]'
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
logfile_path = 'a3.log'
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {},
'handlers': {
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler',
'formatter': 'simple'
},
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler',
'formatter': 'standard',
'filename': logfile_path,
'maxBytes': 1024*1024*5,
'backupCount': 5,
'encoding': 'utf-8',
},
},
'loggers': {
'': {
'handlers': ['default', 'console'],
'level': 'DEBUG',
'propagate': True,
},
},
}
logging.config.dictConfig(LOGGING_DIC)
logger1 = logging.getLogger('红浪漫顾客消费记录')
logger1.debug('慢男 猛男 骚男')
实战应用
日志字典数据应该放在哪个py文件内
字典数据是日志模块固定的配置 写完一次之后几乎都不需要动
它属于配置文件
"""配置文件中变量名推荐全大写"""
该案例能够带你搞明白软件开发目录规范中所有py文件的真正作用
def get_logger(msg):
logging.config.dictConfig(settings.LOGGING_DIC)
logger1 = logging.getLogger(msg)
return logger1




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)