
Hive常用函数
窗口函数与分析函数
应用场景:
(1)用于分区排序
(2)动态Group By
(3)Top N
(4)累计计算
(5)层次查询
窗口函数
FIRST_VALUE:取分组内排序后,截止到当前行,第一个值
LAST_VALUE: 取分组内排序后,截止到当前行,最后一个值
LEAD(col,n,DEFAULT) :用于统计窗口内往下第n行值。第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)
LAG(col,n,DEFAULT) :与lead相反,用于统计窗口内往上第n行值。第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
OVER从句
1、使用标准的聚合函数COUNT、SUM、MIN、MAX、AVG
2、使用PARTITION BY语句,使用一个或者多个原始数据类型的列
3、使用PARTITION BY与ORDER BY语句,使用一个或者多个数据类型的分区或者排序列
4、使用窗口规范,窗口规范支持以下格式:
(ROWS | RANGE) BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN CURRENT ROW AND (CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN [num] FOLLOWING AND (UNBOUNDED | [num]) FOLLOWING- 1
- 2
- 3
当ORDER BY后面缺少窗口从句条件,窗口规范默认是 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
当ORDER BY和窗口从句都缺失, 窗口规范默认是 ROW BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING.
OVER从句支持以下函数, 但是并不支持和窗口一起使用它们。
Ranking函数: Rank, NTile, DenseRank, CumeDist, PercentRank.Lead 和 Lag 函数.
分析函数
ROW_NUMBER() 从1开始,按照顺序,生成分组内记录的序列,比如,按照pv降序排列,生成分组内每天的pv名次,ROW_NUMBER()的应用场景非常多,再比如,获取分组内排序第一的记录;获取一个session中的第一条refer等。
RANK() 生成数据项在分组中的排名,排名相等会在名次中留下空位
DENSE_RANK() 生成数据项在分组中的排名,排名相等会在名次中不会留下空位
CUME_DIST 小于等于当前值的行数/分组内总行数。比如,统计小于等于当前薪水的人数,所占总人数的比例
PERCENT_RANK 分组内当前行的RANK值-1/分组内总行数-1
NTILE(n) 用于将分组数据按照顺序切分成n片,返回当前切片值,如果切片不均匀,默认增加第一个切片的分布。NTILE不支持ROWS BETWEEN,比如 NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)。
Hive2.1.0及以后支持Distinct
在聚合函数(SUM, COUNT and AVG)中,支持distinct,但是在ORDER BY 或者 窗口限制不支持。
COUNT(DISTINCT a) OVER (PARTITION BY c)- 1
Hive 2.2.0中在使用ORDER BY和窗口限制时支持distinct
COUNT(DISTINCT a) OVER (PARTITION BY c ORDER BY d ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)- 1
Hive2.1.0及以后支持在OVER从句中支持聚合函数
SELECT rank() OVER (ORDER BY sum(b))
FROM T
GROUP BY a;- 1
- 2
- 3
测试数据集:
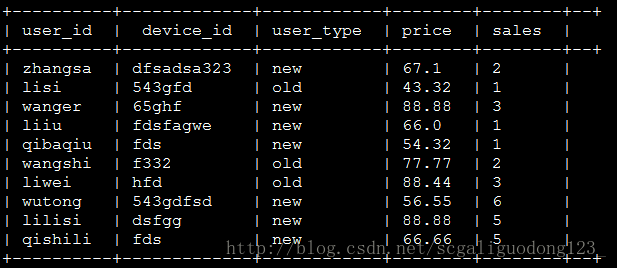
## COUNT、SUM、MIN、MAX、AVG
select
user_id,
user_type,
sales,
--默认为从起点到当前行
sum(sales) OVER(PARTITION BY user_type ORDER BY sales asc) AS sales_1,
--从起点到当前行,结果与sales_1不同。
sum(sales) OVER(PARTITION BY user_type ORDER BY sales asc ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS sales_2,
--当前行+往前3行
sum(sales) OVER(PARTITION BY user_type ORDER BY sales asc ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) AS sales_3,
--当前行+往前3行+往后1行
sum(sales) OVER(PARTITION BY user_type ORDER BY sales asc ROWS BETWEEN 3 PRECEDING AND 1 FOLLOWING) AS sales_4,
--当前行+往后所有行
sum(sales) OVER(PARTITION BY user_type ORDER BY sales asc ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS sales_5,
--分组内所有行
SUM(sales) OVER(PARTITION BY user_type) AS sales_6
from
order_detail
order by
user_type,
sales,
user_id
+----------+------------+--------+----------+----------+----------+----------+----------+----------+--+
| user_id | user_type | sales | sales_1 | sales_2 | sales_3 | sales_4 | sales_5 | sales_6 |
+----------+------------+--------+----------+----------+----------+----------+----------+----------+--+
| liiu | new | 1 | 2 | 2 | 2 | 4 | 22 | 23 |
| qibaqiu | new | 1 | 2 | 1 | 1 | 2 | 23 | 23 |
| zhangsa | new | 2 | 4 | 4 | 4 | 7 | 21 | 23 |
| wanger | new | 3 | 7 | 7 | 7 | 12 | 19 | 23 |
| lilisi | new | 5 | 17 | 17 | 15 | 21 | 11 | 23 |
| qishili | new | 5 | 17 | 12 | 11 | 16 | 16 | 23 |
| wutong | new | 6 | 23 | 23 | 19 | 19 | 6 | 23 |
| lisi | old | 1 | 1 | 1 | 1 | 3 | 6 | 6 |
| wangshi | old | 2 | 3 | 3 | 3 | 6 | 5 | 6 |
| liwei | old | 3 | 6 | 6 | 6 | 6 | 3 | 6 |
+----------+------------+--------+----------+----------+----------+----------+----------+----------+--+
注意:
结果和ORDER BY相关,默认为升序
如果不指定ROWS BETWEEN,默认为从起点到当前行;
如果不指定ORDER BY,则将分组内所有值累加;
关键是理解ROWS BETWEEN含义,也叫做WINDOW子句:
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:无界限(起点或终点)
UNBOUNDED PRECEDING:表示从前面的起点
UNBOUNDED FOLLOWING:表示到后面的终点
其他COUNT、AVG,MIN,MAX,和SUM用法一样。## first_value与last_value
select
user_id,
user_type,
ROW_NUMBER() OVER(PARTITION BY user_type ORDER BY sales) AS row_num,
first_value(user_id) over (partition by user_type order by sales desc) as max_sales_user,
first_value(user_id) over (partition by user_type order by sales asc) as min_sales_user,
last_value(user_id) over (partition by user_type order by sales desc) as curr_last_min_user,
last_value(user_id) over (partition by user_type order by sales asc) as curr_last_max_user
from
order_detail;
+----------+------------+----------+-----------------+-----------------+---------------------+---------------------+--+
| user_id | user_type | row_num | max_sales_user | min_sales_user | curr_last_min_user | curr_last_max_user |
+----------+------------+----------+-----------------+-----------------+---------------------+---------------------+--+
| wutong | new | 7 | wutong | qibaqiu | wutong | wutong |
| lilisi | new | 6 | wutong | qibaqiu | qishili | lilisi |
| qishili | new | 5 | wutong | qibaqiu | qishili | lilisi |
| wanger | new | 4 | wutong | qibaqiu | wanger | wanger |
| zhangsa | new | 3 | wutong | qibaqiu | zhangsa | zhangsa |
| liiu | new | 2 | wutong | qibaqiu | qibaqiu | liiu |
| qibaqiu | new | 1 | wutong | qibaqiu | qibaqiu | liiu |
| liwei | old | 3 | liwei | lisi | liwei | liwei |
| wangshi | old | 2 | liwei | lisi | wangshi | wangshi |
| lisi | old | 1 | liwei | lisi | lisi | lisi |
+----------+------------+----------+-----------------+-----------------+---------------------+---------------------+--+
## lead与lag
select
user_id,device_id,
lead(device_id) over (order by sales) as default_after_one_line,
lag(device_id) over (order by sales) as default_before_one_line,
lead(device_id,2) over (order by sales) as after_two_line,
lag(device_id,2,'abc') over (order by sales) as before_two_line
from
order_detail;
+----------+-------------+-------------------------+--------------------------+-----------------+------------------+--+
| user_id | device_id | default_after_one_line | default_before_one_line | after_two_line | before_two_line |
+----------+-------------+-------------------------+--------------------------+-----------------+------------------+--+
| qibaqiu | fds | fdsfagwe | NULL | 543gfd | abc |
| liiu | fdsfagwe | 543gfd | fds | f332 | abc |
| lisi | 543gfd | f332 | fdsfagwe | dfsadsa323 | fds |
| wangshi | f332 | dfsadsa323 | 543gfd | hfd | fdsfagwe |
| zhangsa | dfsadsa323 | hfd | f332 | 65ghf | 543gfd |
| liwei | hfd | 65ghf | dfsadsa323 | fds | f332 |
| wanger | 65ghf | fds | hfd | dsfgg | dfsadsa323 |
| qishili | fds | dsfgg | 65ghf | 543gdfsd | hfd |
| lilisi | dsfgg | 543gdfsd | fds | NULL | 65ghf |
| wutong | 543gdfsd | NULL | dsfgg | NULL | fds |
+----------+-------------+-------------------------+--------------------------+-----------------+------------------+--+
## RANK、ROW_NUMBER、DENSE_RANK
select
user_id,user_type,sales,
RANK() over (partition by user_type order by sales desc) as r,
ROW_NUMBER() over (partition by user_type order by sales desc) as rn,
DENSE_RANK() over (partition by user_type order by sales desc) as dr
from
order_detail;
+----------+------------+--------+----+-----+-----+--+
| user_id | user_type | sales | r | rn | dr |
+----------+------------+--------+----+-----+-----+--+
| wutong | new | 6 | 1 | 1 | 1 |
| qishili | new | 5 | 2 | 2 | 2 |
| lilisi | new | 5 | 2 | 3 | 2 |
| wanger | new | 3 | 4 | 4 | 3 |
| zhangsa | new | 2 | 5 | 5 | 4 |
| qibaqiu | new | 1 | 6 | 6 | 5 |
| liiu | new | 1 | 6 | 7 | 5 |
| liwei | old | 3 | 1 | 1 | 1 |
| wangshi | old | 2 | 2 | 2 | 2 |
| lisi | old | 1 | 3 | 3 | 3 |
+----------+------------+--------+----+-----+-----+--+ ## NTILE
select
user_type,sales,
--分组内将数据分成2片
NTILE(2) OVER(PARTITION BY user_type ORDER BY sales) AS nt2,
--分组内将数据分成3片
NTILE(3) OVER(PARTITION BY user_type ORDER BY sales) AS nt3,
--分组内将数据分成4片
NTILE(4) OVER(PARTITION BY user_type ORDER BY sales) AS nt4,
--将所有数据分成4片
NTILE(4) OVER(ORDER BY sales) AS all_nt4
from
order_detail
order by
user_type,
sales
+------------+--------+------+------+------+----------+--+
| user_type | sales | nt2 | nt3 | nt4 | all_nt4 |
+------------+--------+------+------+------+----------+--+
| new | 1 | 1 | 1 | 1 | 1 |
| new | 1 | 1 | 1 | 1 | 1 |
| new | 2 | 1 | 1 | 2 | 2 |
| new | 3 | 1 | 2 | 2 | 3 |
| new | 5 | 2 | 2 | 3 | 4 |
| new | 5 | 2 | 3 | 3 | 3 |
| new | 6 | 2 | 3 | 4 | 4 |
| old | 1 | 1 | 1 | 1 | 1 |
| old | 2 | 1 | 2 | 2 | 2 |
| old | 3 | 2 | 3 | 3 | 2 |
+------------+--------+------+------+------+----------+--+
求取sale前20%的用户ID
select
user_id
from
(
select
user_id,
NTILE(5) OVER(ORDER BY sales desc) AS nt
from
order_detail
)A
where nt=1;## CUME_DIST、PERCENT_RANK
select
user_id,user_type,sales,
--没有partition,所有数据均为1组
CUME_DIST() OVER(ORDER BY sales) AS cd1,
--按照user_type进行分组
CUME_DIST() OVER(PARTITION BY user_type ORDER BY sales) AS cd2
from
order_detail;
+----------+------------+--------+------+----------------------+--+
| user_id | user_type | sales | cd1 | cd2 |
+----------+------------+--------+------+----------------------+--+
| liiu | new | 1 | 0.3 | 0.2857142857142857 |
| qibaqiu | new | 1 | 0.3 | 0.2857142857142857 |
| zhangsa | new | 2 | 0.5 | 0.42857142857142855 |
| wanger | new | 3 | 0.7 | 0.5714285714285714 |
| lilisi | new | 5 | 0.9 | 0.8571428571428571 |
| qishili | new | 5 | 0.9 | 0.8571428571428571 |
| wutong | new | 6 | 1.0 | 1.0 |
| lisi | old | 1 | 0.3 | 0.3333333333333333 |
| wangshi | old | 2 | 0.5 | 0.6666666666666666 |
| liwei | old | 3 | 0.7 | 1.0 |
+----------+------------+--------+------+----------------------+--+
select
user_type,sales
--分组内总行数
SUM(1) OVER(PARTITION BY user_type) AS s,
--RANK值
RANK() OVER(ORDER BY sales) AS r,
PERCENT_RANK() OVER(ORDER BY sales) AS pr,
--分组内
PERCENT_RANK() OVER(PARTITION BY user_type ORDER BY sales) AS prg
from
order_detail;
+----+-----+---------------------+---------------------+--+
| s | r | pr | prg |
+----+-----+---------------------+---------------------+--+
| 7 | 1 | 0.0 | 0.0 |
| 7 | 1 | 0.0 | 0.0 |
| 7 | 4 | 0.3333333333333333 | 0.3333333333333333 |
| 7 | 6 | 0.5555555555555556 | 0.5 |
| 7 | 8 | 0.7777777777777778 | 0.6666666666666666 |
| 7 | 8 | 0.7777777777777778 | 0.6666666666666666 |
| 7 | 10 | 1.0 | 1.0 |
| 3 | 1 | 0.0 | 0.0 |
| 3 | 4 | 0.3333333333333333 | 0.5 |
| 3 | 6 | 0.5555555555555556 | 1.0 |
+----+-----+---------------------+---------------------+--+增强的聚合 Cube和Grouping 和Rollup
这几个分析函数通常用于OLAP中,不能累加,而且需要根据不同维度上钻和下钻的指标统计,比如,分小时、天、月的UV数。
GROUPING SETS
在一个GROUP BY查询中,根据不同的维度组合进行聚合,等价于将不同维度的GROUP BY结果集进行UNION ALL,
其中的GROUPING__ID,表示结果属于哪一个分组集合。
select
user_type,
sales,
count(user_id) as pv,
GROUPING__ID
from
order_detail
group by
user_type,sales
GROUPING SETS(user_type,sales)
ORDER BY
GROUPING__ID;
+------------+--------+-----+---------------+--+
| user_type | sales | pv | grouping__id |
+------------+--------+-----+---------------+--+
| old | NULL | 3 | 1 |
| new | NULL | 7 | 1 |
| NULL | 6 | 1 | 2 |
| NULL | 5 | 2 | 2 |
| NULL | 3 | 2 | 2 |
| NULL | 2 | 2 | 2 |
| NULL | 1 | 3 | 2 |
+------------+--------+-----+---------------+--+
select
user_type,
sales,
count(user_id) as pv,
GROUPING__ID
from
order_detail
group by
user_type,sales
GROUPING SETS(user_type,sales,(user_type,sales))
ORDER BY
GROUPING__ID;
+------------+--------+-----+---------------+--+
| user_type | sales | pv | grouping__id |
+------------+--------+-----+---------------+--+
| old | NULL | 3 | 1 |
| new | NULL | 7 | 1 |
| NULL | 1 | 3 | 2 |
| NULL | 6 | 1 | 2 |
| NULL | 5 | 2 | 2 |
| NULL | 3 | 2 | 2 |
| NULL | 2 | 2 | 2 |
| old | 3 | 1 | 3 |
| old | 2 | 1 | 3 |
| old | 1 | 1 | 3 |
| new | 6 | 1 | 3 |
| new | 5 | 2 | 3 |
| new | 3 | 1 | 3 |
| new | 1 | 2 | 3 |
| new | 2 | 1 | 3 |
+------------+--------+-----+---------------+--+CUBE
根据GROUP BY的维度的所有组合进行聚合。
select
user_type,
sales,
count(user_id) as pv,
GROUPING__ID
from
order_detail
group by
user_type,sales
WITH CUBE
ORDER BY
GROUPING__ID;
+------------+--------+-----+---------------+--+
| user_type | sales | pv | grouping__id |
+------------+--------+-----+---------------+--+
| NULL | NULL | 10 | 0 |
| new | NULL | 7 | 1 |
| old | NULL | 3 | 1 |
| NULL | 6 | 1 | 2 |
| NULL | 5 | 2 | 2 |
| NULL | 3 | 2 | 2 |
| NULL | 2 | 2 | 2 |
| NULL | 1 | 3 | 2 |
| old | 3 | 1 | 3 |
| old | 2 | 1 | 3 |
| old | 1 | 1 | 3 |
| new | 6 | 1 | 3 |
| new | 5 | 2 | 3 |
| new | 3 | 1 | 3 |
| new | 2 | 1 | 3 |
| new | 1 | 2 | 3 |
+------------+--------+-----+---------------+--+ROLLUP
是CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合。
select
user_type,
sales,
count(user_id) as pv,
GROUPING__ID
from
order_detail
group by
user_type,sales
WITH ROLLUP
ORDER BY
GROUPING__ID;
+------------+--------+-----+---------------+--+
| user_type | sales | pv | grouping__id |
+------------+--------+-----+---------------+--+
| NULL | NULL | 10 | 0 |
| old | NULL | 3 | 1 |
| new | NULL | 7 | 1 |
| old | 3 | 1 | 3 |
| old | 2 | 1 | 3 |
| old | 1 | 1 | 3 |
| new | 6 | 1 | 3 |
| new | 5 | 2 | 3 |
| new | 3 | 1 | 3 |
| new | 2 | 1 | 3 |
| new | 1 | 2 | 3 |
+------------+--------+-----+---------------+--+
 浙公网安备 33010602011771号
浙公网安备 33010602011771号